

Understanding Partitioning, Replication and Backup in Apache IoTDB
With the rapid evolution of IT and OT technologies, time-series data has become a critical asset across industries such as manufacturing, energy and transportation. Applications including AI analytics, predictive maintenance, and anomaly detection rely heavily on the efficient storage and processing of time-series data.
However, managing massive time-series datasets introduces significant challenges in terms of storage scalability, query performance, and system reliability. To address these challenges, Apache IoTDB provides robust mechanisms for data partitioning, replication, and backup.
This article introduces how IoTDB implements these mechanisms and how they support large-scale industrial scenarios.
Characteristics of Time-Series Data
Time-series data has several unique characteristics compared with traditional transactional data.
Massive Number of Data Points
Industrial systems often contain an extremely large number of measurement points.
For example:
A large energy storage facility may deploy millions of sensors
Nationwide monitoring systems may contain tens of billions of measurement points
Connected vehicle platforms may collect billions of telemetry signals from vehicles on the road
These measurement points continuously generate data streams.
High Storage Cost
Industrial environments typically produce data at high frequency and high volume.
Examples include:
Ultra-large steel manufacturing equipment
Wind turbines in renewable energy plants
In these scenarios, data collection frequencies can be extremely high, and the total storage demand can easily reach petabyte scale.
Without efficient data organization mechanisms, managing such datasets becomes extremely difficult.
Data Partitioning in Apache IoTDB
What Is Data Partitioning
Data partitioning refers to dividing data into multiple segments according to defined rules so that each segment can be managed independently.
A simple analogy is a library:
Without partitioning, all books are stored randomly.
With partitioning, books are categorized and placed on different shelves.
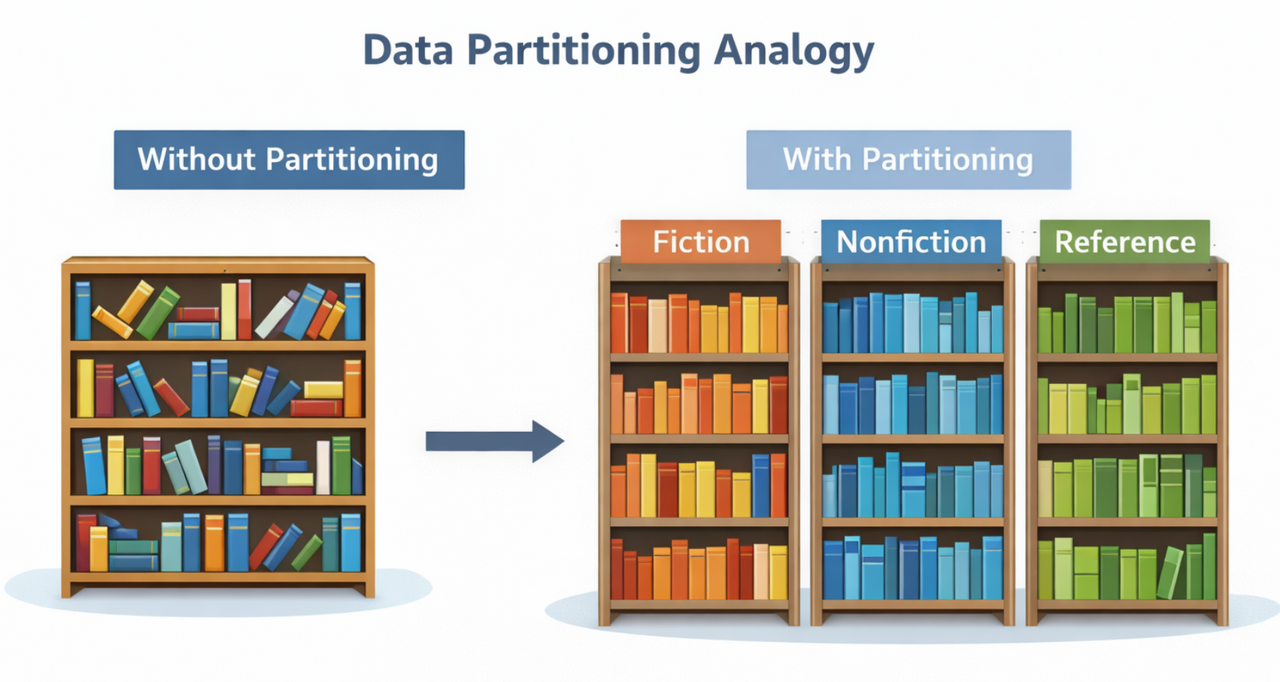 This organization significantly improves data management efficiency and query performance. For time-series databases handling massive datasets, partitioning becomes a core architectural component.
This organization significantly improves data management efficiency and query performance. For time-series databases handling massive datasets, partitioning becomes a core architectural component.
Data Partitioning Mechanism in IoTDB
Apache IoTDB implements a two-dimensional partitioning strategy based on:
Series dimension
Time dimension
These correspond to Series Partition Slots and Time Partition Slots.
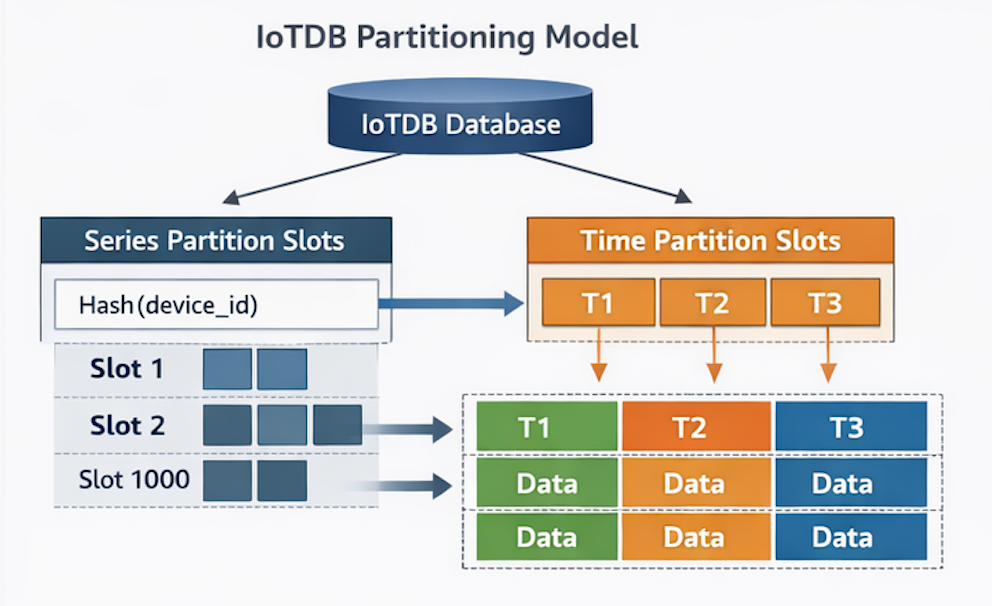
Series Partition Slot
Series partitioning is used to manage time series vertically.
By default:
Partitioning occurs at the database level
Each database contains 1,000 series partition slots
IoTDB uses a Hash Algorithm to map each time series to a specific partition slot.
This approach provides several benefits:
Efficient metadata management
Reduced memory mapping overhead
Better load distribution across nodes
This design is particularly important for scenarios involving hundreds of millions or billions of devices.
Time Partition Slot
Time partitioning manages time series horizontally. Data is divided into segments based on fixed time intervals. By default, each time partition represents: 7 days of data.
This design improves query efficiency because:
Queries typically target specific time ranges
Only relevant partitions need to be scanned
As a result, IoTDB avoids unnecessary full-dataset scans.
Partition Distribution in an IoTDB Cluster
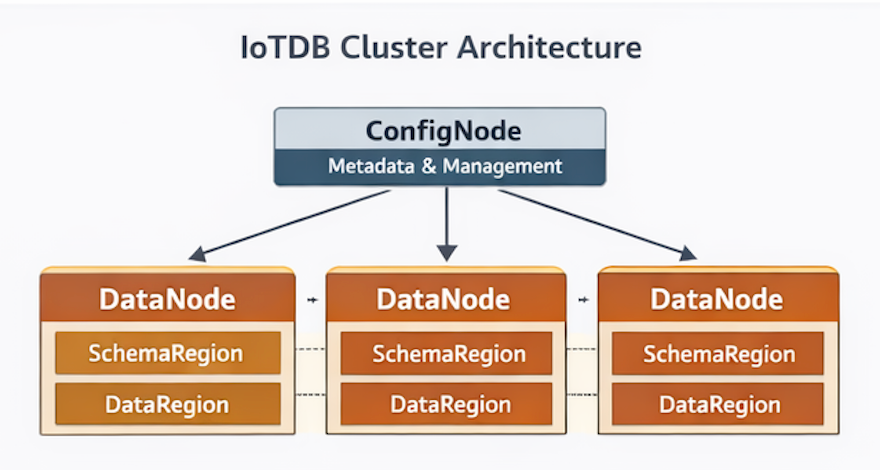 An IoTDB cluster contains two types of nodes:
An IoTDB cluster contains two types of nodes:
ConfigNode
The ConfigNode is responsible for cluster management and coordination, including:
Metadata management
Partition allocation
Cluster configuration
DataNode
The DataNode handles actual data operations, including:
Data ingestion
Query processing
Storage management
Within each DataNode, data is organized into:
SchemaRegion
DataRegion
IoTDB distributes partitions across nodes using load balancing algorithms, ensuring that data and write workloads are evenly distributed across the cluster.
This architecture improves:
Storage scalability
Write throughput
Cluster stability
Partition Execution from Read and Write Perspectives
Write Workflow
When a client sends a write request:
The request can be sent to any node in the IoTDB cluster.
The node applies a load-balancing algorithm based on
device_id.The system determines the target DataNode.
The timestamp determines which time partition the data belongs to.
The data is then written to the corresponding DataRegion.
Query Workflow
When a query is executed:
The query request is sent to the cluster.
The query engine determines the target node using
device_id.The request is forwarded to the corresponding node.
The query engine scans only the relevant time partitions.
Because unrelated partitions are skipped, query performance is significantly improved.
Data Partitioning Mechanisms in IoTDB
IoTDB supports two types of synchronization:
Intra-cluster synchronization
Cross-cluster synchronization
Each serves different purposes.
Intra-Cluster Synchronization
Intra-cluster synchronization refers to data replication between nodes within the same cluster.
Its primary goal is to ensure:
High availability
Replica consistency
IoTDB supports two types of consensus protocols.
Strong Consistency: Ratis Protocol
IoTDB uses the Apache Ratis protocol to achieve strong consistency for:
ConfigNode metadata
Some partition operations
With strong consistency: A request is considered successful only after all replicas confirm the update. This ensures strong data consistency but may introduce higher latency.
High-Performance Replication: IoTConsensus
For DataNode operations, IoTDB uses its own protocol called IoTConsensus. This protocol prioritizes write performance.
Workflow:
Data is first written to the local node
Replication to other nodes occurs asynchronously
This design significantly improves ingestion throughput, which is critical for industrial time-series workloads.
Replication Workflow
The replication process follows these steps:
The server receives a write request
The consensus layer processes the request
The request is delivered to the state machine
The state machine forwards the request to the DataRegion
The storage engine writes the data into:
MemTable
Write-Ahead Log (WAL)
A log distribution thread asynchronously replicates the write request to replica nodes.
If a replica node goes offline:
The leader records the synchronization progress
When the node recovers, synchronization resumes automatically
This ensures eventual consistency across replicas.
Failover and High Availability
The intra-cluster consensus protocol enables automatic failover.
If the leader node fails:
A replica node is automatically promoted to leader
Read and write services continue without interruption
This mechanism ensures high service availability in production environments.
Cross-Cluster Synchronization
IoTDB also supports synchronization between different clusters. This capability is useful for scenarios such as:
Disaster recovery
Geo-redundant backup
Edge-cloud collaboration
IoTDB Streaming Framework
IoTDB provides a stream processing framework consisting of three stages:
Data Extraction
Data Processing
Data Delivery
Data Extraction
Defines which data should be extracted from IoTDB, including:
Measurement scope
Time range
Data Processing
Users can apply programmable processing logic, such as:
Removing outliers
Transforming data types
Filtering values
Data Delivery
Processed data can be sent to different destinations.
Users can implement custom logic using IoTDB’s standardized plugin framework, and the platform also provides built-in plugins.
Typical Use Cases
The IoTDB streaming framework enables many real-world scenarios.
Disaster Recovery
Data synchronization tasks can be created using simple SQL commands, enabling:
Cross-region disaster recovery
Real-time backup
Replication latency can be as low as milliseconds.
Real-Time Data Processing
The framework can also support:
Real-time alerts
Stream computing
Real-time aggregation
Data write-back
Cross-System Data Integration
IoTDB can integrate with external systems including:
Message queues
Apache Flink
Offline analytics pipelines
[Added for clarity: common enterprise architectures frequently integrate IoTDB with data lakes or streaming platforms]
Frequently Asked Questions (FAQ)
When Should You Use the Ratis Protocol?
If your workload requires strict consistency and write throughput is not the primary concern, Ratis may be appropriate. However, IoTConsensus typically provides better write performance for large-scale ingestion.
Why Does IoTDB Use Series Partition Slots?
In scenarios such as energy storage systems or meteorological monitoring, the number of time series can be extremely large.Series partition slots reduce memory overhead by managing series through hash-based slot mapping.
Can IoTDB Support Cross-Network Gateway Transmission?
Yes. The streaming framework has already been adapted for common industrial gateways. Other gateways typically require only minimal integration work.
Cost-Efficient Storage Options
IoTDB supports tiered storage, allowing users to store:
Hot data on SSD
Warm data on HDD
Cold data on object storage such as Amazon S3
During queries, data stored in S3 can be retrieved transparently.
Is Data Loss Possible?
Under extreme conditions, a small amount of data loss may occur when using eventual consistency replication, because asynchronous replication introduces a short delay. However, this delay is typically within 1 millisecond.
Impact of Multiple Replicas
Multiple replicas improve availability and fault tolerance, but they also increase storage consumption. Replication is asynchronous and usually does not affect the primary write thread, unless system resources become constrained.
Query Optimization
The client can cache the leader node of each device, allowing queries to be sent directly to the leader and reducing request forwarding. This feature can be enabled or disabled depending on client resource constraints.
Can Replicas Be Placed on Specific Nodes?
Currently, IoTDB does not support explicitly assigning replicas to specific nodes.However:
Manual migration is supported
Cross-cluster synchronization can be used to build geo-distributed active-active architectures


