

Since I shifted my focus from doing classical IT-consulting towards Industrial use-cases, I have worked for a large number of companies, helped with a greater number of projects and exchanged thoughts with even more.
During this time, we ran into a lot of problems, as for most we were trying to do, what no one had done before in those companies. Especially when it came to getting, collecting and storing data for future processing. Superficially, every problem sort of seemed unique, but the more problems I came across, the more I noticed that they were actually mostly just instances of a number of general root problems.
Summing it up, I see these problem categories:
Overloading Automation Equipment
Overloading Automation Networks
Overloading Automation Site-Infrastructure
Overloading the Internet-Uplink of the site
Overloading Narrowband IoT Transports
Dealing with unreliable internet connections
In this blog, I'd love to discuss some of these root problems and how Apache IoTDB can help with addressing them very efficiently.
The following should help visualize these problems. I tried showing the "load" by the width of the lines and the capacity by the width of the "device" or bit of infrastructure.
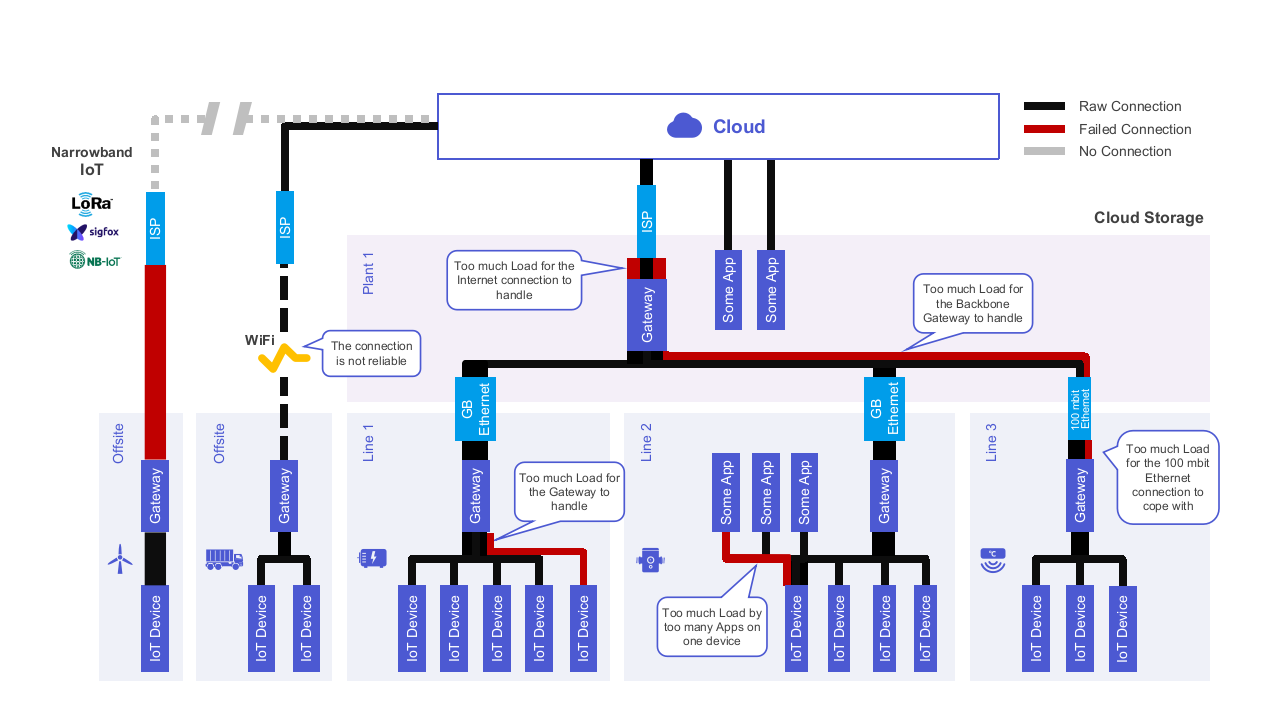
Now let me go into the details for each of these sets of problems.
Overloading Automation Equipment
I guess this is probably the most basic problem. For most people in the IT-world or even from the consumer world, everything accepting connections can support as many clients as there are. The idea of a device supporting only a small and limited number of connections feels strange for them.
Most might understand from experience, that millions of people trying to access one website at the same time might cause issues, but the idea of a system not even supporting a 2-digit number of connections simply does not occcur.
In my time working on Apache PLC4X I quickly learned, that even a 2-digit number of connections in the industrial space can be a challenge. Having a look at the devices that I personally own and use:
All my Siemens S7 1200 devices support at most 3 concurrent connections
My KNXNet/IP gateway allows 2 connections
But even if a device supports more connections, the processing power is usually limited so much, that even big PLCs can easily be overloaded even by very few connections. Each connection comes with performance costs for handling and managing the connection. Also are there great differences in memory- and CPU-time costs for the different protocols. Sicking with my Siemens PLCs for example: I can get huge amounts of data from an S7 1200 using the S7comm protocol, but I can easily kill the PLC by asking it a way smaller number of tags via OPC-UA. Keep in mind, that even powerful automation hardware is usually based on CPUs that one wouldn't even want to work with if built into a PC.
Unfortunately many (I)IoT projects are setup that each new application goes directly to the equipment and asks for the information it needs in order to do it's job.
I have seen on many occasions, that a production-line stopped working because some equipment was overloaded by too many requests, or a dashboard app "stole the connection" of the MES or SCADA system. In the worst case, machinery, products or people could get hurt as the CPU of the PLC didn't have the time to react fast enough and stop a motor, turn off a press or whatever.
Overloading Automation Networks
If the previous issue didn't lead to complications, the subsequent one often becomes significantly troublesome. Usually, during the implementation phase, we only deal with a few devices, so this problem doesn't pop up. But the moment we roll out the solution to the whole production line, that's when the real issues begin.
Gigabit Ethernet networks are becoming more and more standard, but simple 100mbit infrastructure is still quite common, even in 2023.
I suppose it's easy to imagine that fetching data from just a few devices during the initial stages of design and development wouldn't lead to any issues. But now, think about deploying the same applications to production lines with potentially hundreds of PLCs or other IO hardware.
Industry switches are typically designed to prioritize traffic to ensure smooth operation of the production line. However, it's easy to imagine that troubleshooting applications that appear to be losing packets randomly can be quite frustrating. Especially as many industry protocols seem to favor connection-less protocols based on UDP.
Overloading Automation Site-Infrastructure
The next challenge arises when we transition solutions from a line-level to a site-level. What worked seamlessly at a line-level becomes more complex as companies begin collecting data from all lines and attempt to create a comprehensive site-level data lake.
Assuming you had a gigabit ethernet setup on the line-level, which was able to deal with all traffic without any problems, because the equipment only utilized half of its capacity.
Many people in the past forgot that in order to aggregate all of this on a site with, let's say, 10-20 lines requires a completely different network infrastructure in order to cope with so much traffic. You might be in need of something like an optical fibre network in order to deal with this.
However, this might only be the most obvious problem to run into.
It's a common fact that databases don't scale linearly. What worked with 1000 devices will most likely not work with millions of devices. In the IT-World we've grown accustomed to distributed systems that allow handling unbelievable volumes of data. The problem is: In the automation world distributed systems are just starting to establish themselves. I have only heard of automation vendors planning on building distributed solutions, but have never even seen any of these being used in the field. Unfortunately, in most cases, data was simply collected in systems based on classical monolithic relational databases. There wasn't a single case, where this was not a problem on site-level.
In most cases, reducing the number of tags and/or reducing the frequency the tags were being collected was considered the "solution".
Overloading the Internet-Uplink of the Site
Collecting and processing site data in the cloud quite often also was something that many companies aimed for. The idea of having all your companies' production-data in the cloud where data-scientists can do whatever they want with it, without having to manage and maintain the infrastructure on-site, is just too tempting.
However, this usually was the part where I had to play devil's advocate in early meetings, usually commenting: "Not gonna work". In almost all cases, a little discussion would start on how I could say such a thing without even knowing the details.
That usually was the time when I simply started doing a little calculation on paper: "Sooo... These are the details I know: We've got 20 lines, each line has roughly 300-400 PLCs. From each PLC we collect 3000 Tags every second. Let's assume each Tag is a 10 CHAR String (For some reason automation-engineers tend to use STRINGs for things that Software-Engineers would use numeric enums, so this assumption is actually quite conservative)" ... then, I usually do the maths: "20 x 400 x 3000 x 10 = 240,000,000 bytes/s = 240 MB/s". Usually, as soon as they see that they would need at least 10 times the maximum internet connection they currently have, we start discussing alternative approaches.
Overloading Narrowband IoT Transports
NB-IoT, LoRa, Sigfox, are all awesome technologies for passing along data from a large number of independent devices out in the field without requiring a full-blown earth-bound internet connection. In many cases, such an earth-bound connection isn't even technically or financially possible.
LoRa for example, allows data-packets of max 256 bytes. Now one may think: "Well, then I'll just send more packets". However, this is not how it works. In LoRa exist so-called "fair-use" policies that limit the amount of packets a participant is allowed to send.
This usually elimiates most classical approaches of instantly sending data coming in.
Dealing with Unreliable Internet Connections
One interesting case was where one customer wanted to collect data on "mobile devices". These mobile devices however, were huge trucks used in some of their mines. They wanted to collect data on these trucks and start processing that data in order to do predictive maintenance and optimize some of the routes.
The problem with some of these mines is that they are unbelievably big. Providing wireless communication coverage for some of them is just not feasible. Also do the nature of Mines being huge holes in rock provide their own challenges for wireless connectivity.

I also had other customers, where I explicitly had to deal with the fact that Internet is only available via GPRS and that not even continuously (This allows 20 kbits/s of throughput).
Classical approaches simply don't work in these environments and manual implementation of workarounds is required.
Addressing all of these with Apache IoTDB
When I came across IoTDB, at the time the existing team from the Tsinghua University planned on joining the Apache Incubator, I knew this project was special. From just reading the description it felt for me like it was the missing puzzle piece in my picture I had of an industrial open-source ecosystem.
That was why I instantly jumped on board, serving the young project as a mentor, helping the project evolve into a healthy and thriving Apache project.
Interestingly, it seems that the core-concepts it is built around can help solve all of the above problems.
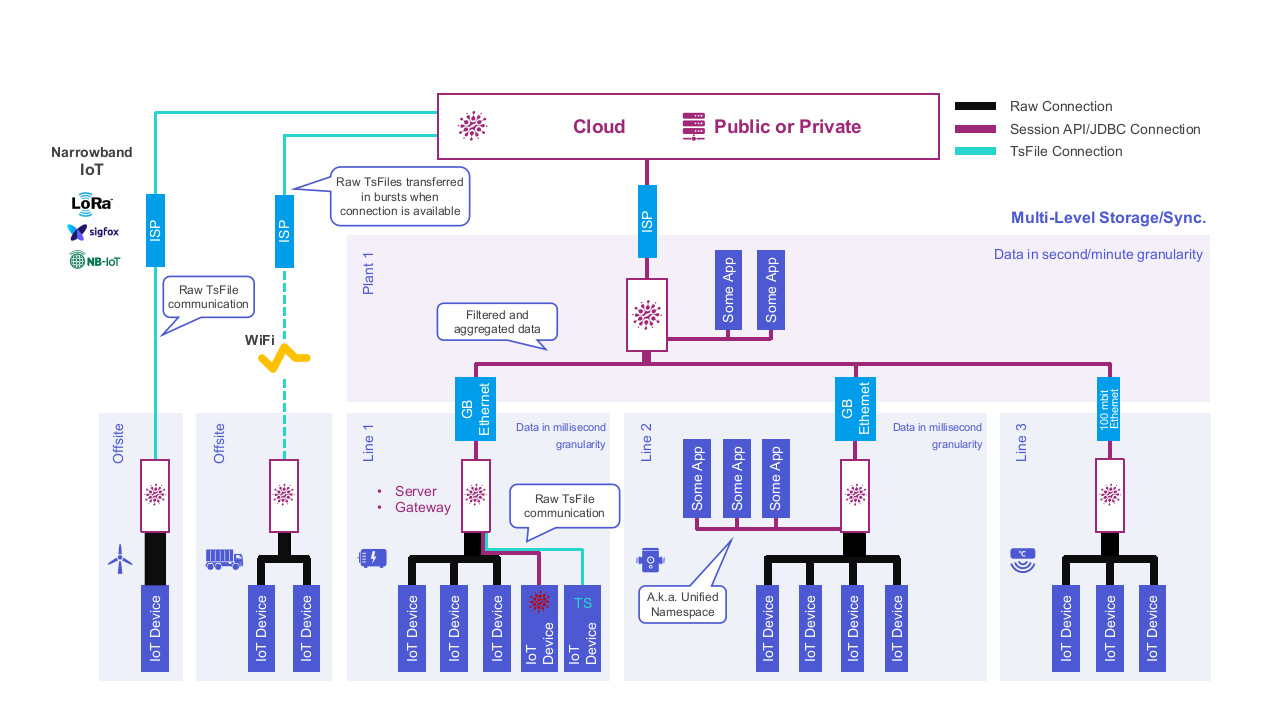
Overloading Automation Equipment and Automation Networks
One big problem with existing automation products is that they were not built for being used as a central data-hub. While some allow querying information from them, they tend to have issues with performance and latency.
Apache IoTDB usually responds a lot faster than the PLC itself. As an example, a typical roundtrip using the S7 protocol (which I would even consider quite performant) takes around 10-20 ms (when querying quite a number of datapoints). IoTDB, in contrast, is able to respond to the same query in significantly faster.
This makes it an ideal solution for being used as a central data-hub for a number of automation applications. These can query IoTDB or even register themselves as receivers for complex queries, so they are informed by IoTDB whenever new data is available.
Walker Reynolds called this concept: "Unified Namespace" and our friends at HiveMQ are actively advocating the adoption of this concept.
All we need to ensure is that one connector is connected to the Hardware collecting all the information that is needed by all applications, in the granularity required and that data is saved in IoTDB.
Of course, if more data is required in granularities that the hardware can't provide, this approach too doesn't help directly. But the reduced amount of connections, some querying the same data, greatly reduces the load on the systems as well as the network connecting everything.
As soon as more data is needed than can be read from one PLC directly, one quite interesting option might help:
Apache IoTDB can be run in what we call an "embedded mode". In this case we don't start a complete instance of IoTDB; instead, we typically only write data into what is known as TsFiles. These files are highly efficient at handling large volumes of data even on systems with limited hardware resources. So in this scenario, we'd be writing data from within the PLC process into local TsFiles and these would then be ingested by a connected IoTDB server.
Overloading Automation Site-Infrastructure and Internet-Uplink
IoTDB can help prevent overloading the site-network with two features:
As mentioned in the previous chapter, IoTDB allows transferring so-called TsFiles. You can imagine these as compressed mini-database files. So instead of transferring a stream of uncompressed data, we transfer chunks of compressed binary data. But I'll go a bit more into detail with this when describing some of the other scenarios, as I think this approach fits them better. I just wanted to make sure this approach is mentioned.
The better approach for helping in this scenario is what we call multi-level data-sync.
In almost all cases, there was a need to have a significant amount of data available at high frequencies only at the shop-floor level. However, aggregated data was more than sufficient to address topics at higher levels, such as the site-level or in the cloud.
The multi-level data synchronization introduces a hierarchical storage system in which a higher-level instance of IoTDB consumes data from a lower-level instance. Aggregation is utilized as part of the replication process.
Unlike simply reducing the sampling rate, aggregation greatly enhances data usability.
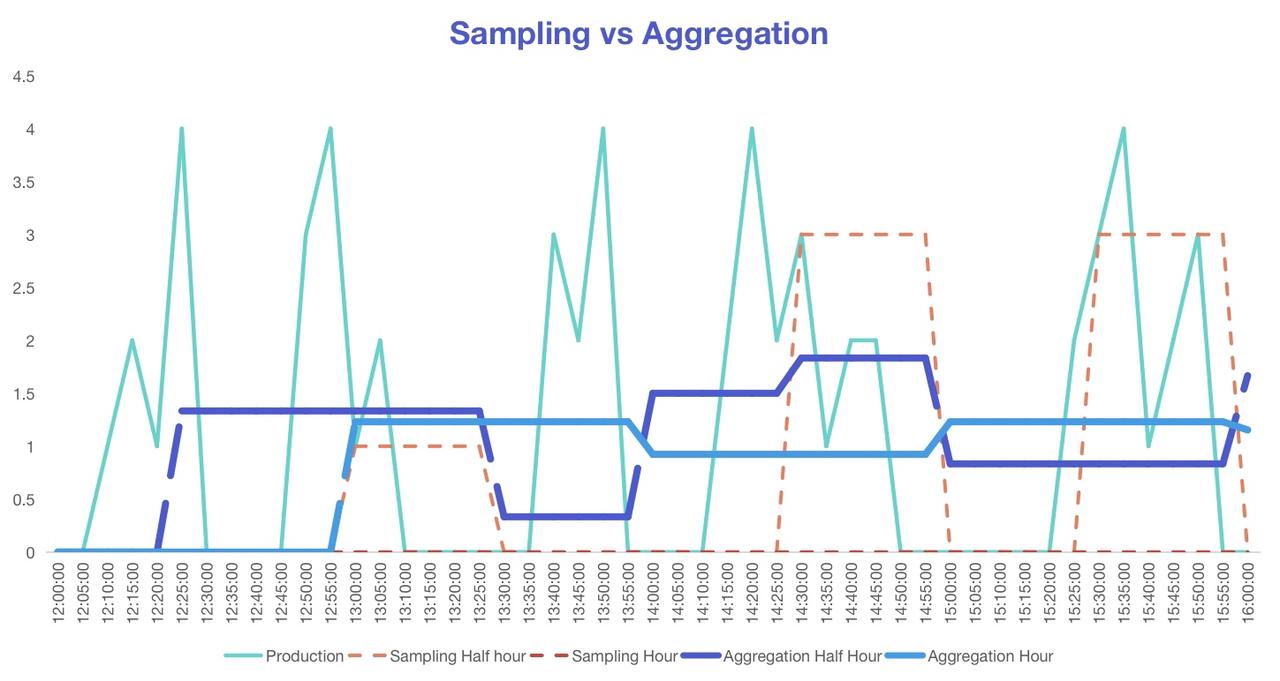
Especially for company-wide cloud-based analytics, having data at minute granularity is overly detailed, and hourly averages suffice for these scenarios. Therefore, hierarchical storage holds significant potential for cost savings, particularly concerning the cloud-uplink challenge.
Overloading Narrowband IoT Transports
I mentioned the ability to handle TsFile storage before, but in this and the following scenarios I think it probably can provide the most advantages.
In such an approach, we wouldn't necessarily be running a full instance of IoTDB, but only write date into IoTDB's native data format: TsFiles. This format allows even doing this on very small and simple embedded hardware. TsFile has the advantage of using very little data for saving sparse data as well as data-sets with small value deviations, and it is even able to use compression to reduce data even more.
IoTDB is able to store data lossless with an average compression ratio of 10:1 and if it doesn't have to be lossless it can even provide a compression of up to 100:1.
So the device starts writing data into a local TsFile and as soon as the size of that reaches the maximum capacity of the underlying transport media, the device will switch to writing to a new file and send the old one over the "wire".
This greatly reduces the number of sent packets utilizes the transport media to the maximum and hereby greatly reduces the overall amount of data transferred.
I should also point out that this approach can also help greatly reduce the costs for sending data to cloud providers such as Azure IoT. Here MQTT has usually established itself as the de-facto standard for ingesting data. Pricing is usually based on the number of messages consumed. In order to prevent megabyte large MQTT payloads, there usually is a limit for the size of MQTT messages. The approach of using TsFiles locally allows utilizing the size of such MQTT messages to the absolute maximum, hereby reducing the number of messages sent and the costs.
Dealing with Unreliable Internet Connections
This scenario is very similar to the one discussed in the last section. The trigger for sending out data is simply different.
In this scenario, we'd be writing data to TsFiles with the same benefits as in the previous scenario, but in contrast to that, we'd send the data as soon as a network connection is detected.
In the case of the mine-truck, this would be when the truck is back from the mine, deploying it's cargo or when it returns back to the headquarter after it's shift. As soon as something such as a WIFI connection is established, the client on the truck would upload the TsFile data in one big burst.
Similarly, things would probably happen in the case of unreliable internet connection. Here, it might be necessary to implement some chunking of TsFiles to sensibly sized files, which we have a chance of transferring. There is no use in having a 100MB TsFile with data from the last day, if usually the connection only allows us to send 1MB at a time.
In this case, it might also make sense to automatically utilize aggregation, if the volume of data we want to pass along is not able to go out due to changed conditions (bad weather, failing infrastructure, ...), sending aggregated data might be the solution to still get at least some valuable data over.
Summary
Apache IoTDB is a fascinating project, solving many complex problems easily by simple design choices. However, this flexibility does not come with hidden costs with respect to performance or complexity. Recently some performance-benchmark data was published, proving that Apache IoTDB is able to provide unmatched performance for handling timeseries data.
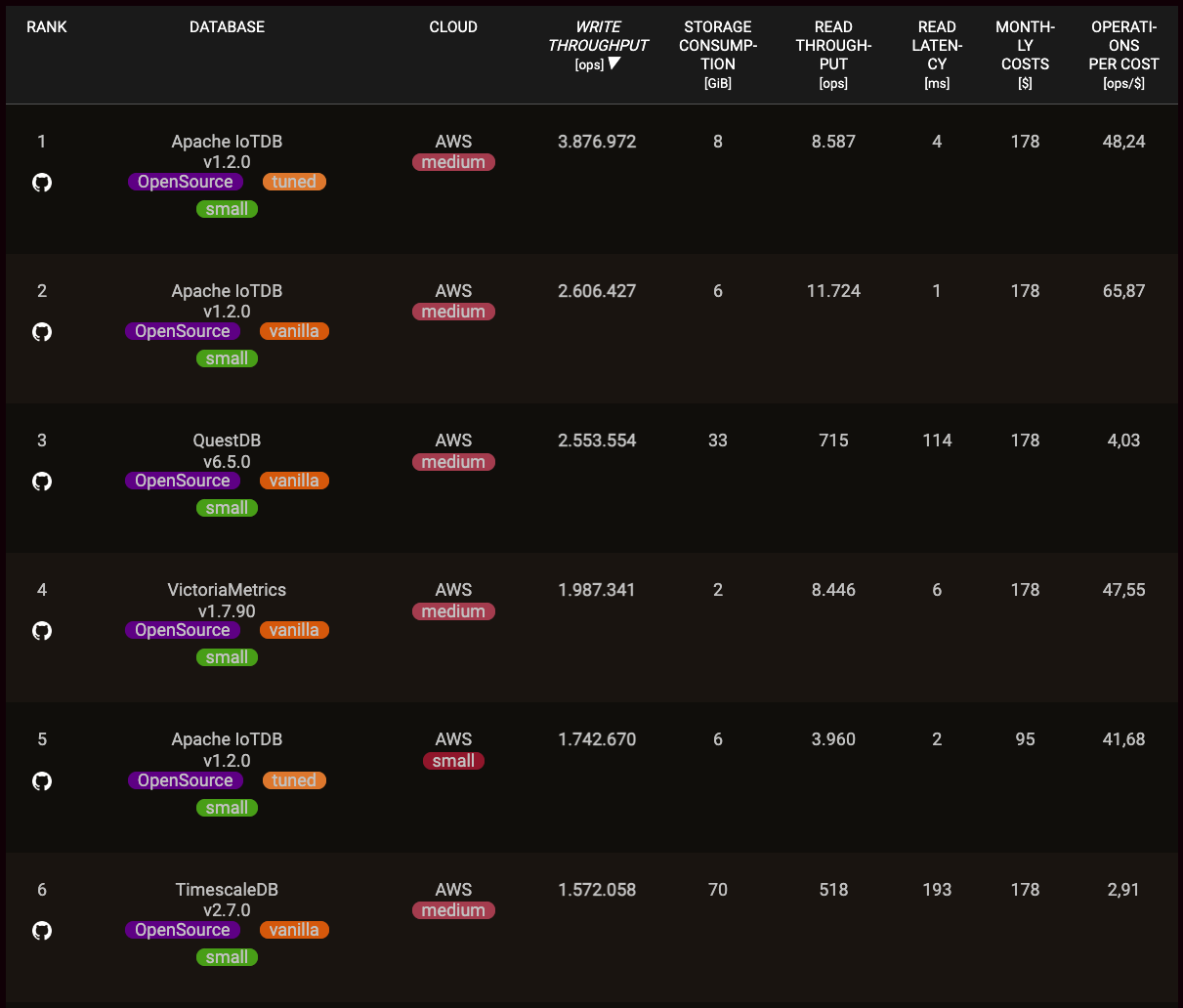
And this is simply speaking about the free open-source Apache IoTDB stack. Based on Apache IoTDB, Timecho offers advanced commercial solution "TimechoDB", which provides additional features targeted at enterprise customers as well as increased performance. If you are in need for some more advanced features, more performance or commercial support, Timecho with it's TimechoDB is there to help.
Relevant Links
benchANT, Apache IoTDB: A New Leader in Time Series Databases
Apache IoTDB Homepage
Apache IoTDB Github Repository
Author
| Christofer Dutz Solution Consulting Expert at Timecho Board Member at Apache Software Foundation | |



