

Beyond the Myth of "Simple" Time-Series Forecasting
Many practitioners still view time-series forecasting as a straightforward exercise: use historical data to predict future trends. In real industrial systems, however, the problem is far more complex.
Load forecasting is tightly coupled with temperature variation.
Equipment health prediction depends heavily on operating conditions.
Wind power forecasting is driven by meteorological factors.
Production energy consumption forecasting relies on scheduling plans.
In practice, real-world time series exist within strongly coupled multivariate systems. Relying solely on the historical values of a target variable imposes a natural ceiling on predictive performance. The true technical frontier of time-series forecasting lies in the accurate modeling and utilization of covariates.
From Univariate Forecasting to Covariate-Aware Modeling
Early time-series models primarily focused on the intrinsic dynamics of a single curve. The typical question was:
How will this series evolve in the future?
In industrial environments, the more meaningful question is:
How will this series evolve under the current environmental and operational conditions?
External factors that influence the target variable—such as temperature, humidity, load, control parameters, and operating state—are referred to as covariates.
Importantly, covariate forecasting is not merely about increasing the number of input variables. Its core objective is to enable models to understand the dynamic dependencies and coupling relationships among variables. It addresses a system-level problem:
How does the target variable evolve under multi-variable interaction?
In strongly coupled industrial systems, the ability to robustly handle covariates represents a key breakthrough toward higher-complexity forecasting scenarios.

The Timer Roadmap: Structural in Time-Series Modeling
Time-series foundation models are emerging as a new modeling paradigm in large-scale forecasting research. Through large-scale pretraining, these models learn general time-series representations and achieve cross-domain transferability.
The Timer model family illustrates a clear technical evolution toward more general and powerful time-series intelligence:
Timer 1.0 — Feasibility of General Representation Learning The initial phase focused on validating the viability of general time-series pretraining. With large-scale pretraining, the model began to demonstrate cross-dataset transfer capability, moving time-series modeling toward a more generalized paradigm.
Timer-XL (Timer 2.0) — Long-Context Modeling Timer-XL strengthened long-sequence modeling and established a unified forecasting framework. Industrial systems typically exhibit both long-term trends and short-term fluctuations; improving context length and modeling stability was a critical step toward real-world applicability.
Timer-Sundial (Timer 3.0) — Generative Forecasting and Uncertainty Modeling Timer 3.0 introduced native continuous time-series tokenization and leveraged trillion-scale pretraining tokens for broader distribution learning. While maintaining strong generalization, the model achieved significantly improved zero-shot forecasting capability.
Learn more on the website: https://thuml.github.io/timer/
Compared with version 2.0, Timer 3.0 delivers notable gains in both inference quality and efficiency. It also supports quantile forecasting, enabling prediction outputs to move beyond single-point estimates and explicitly characterize uncertainty intervals.
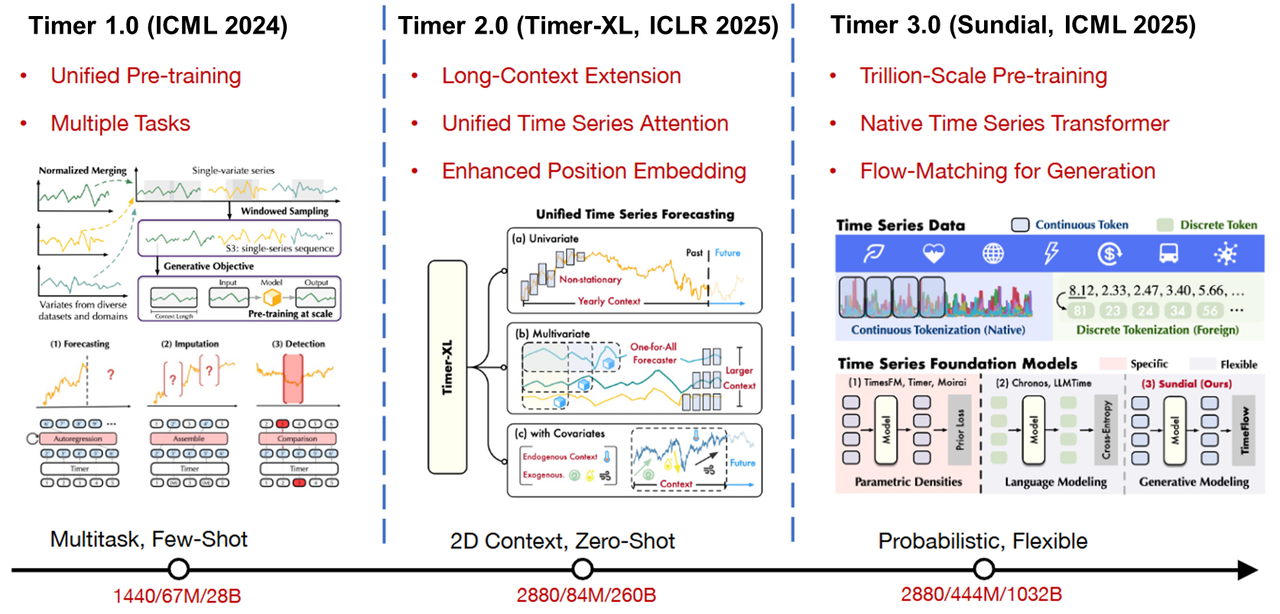
The Timer roadmap is not a simple feature accumulation. It represents a structural evolution that continuously strengthens modeling depth, generalization, and engineering readiness on top of a general pretraining foundation.
The Changing Role of the Database: Data–Model Co-Execution
As general time-series models become more capable, a practical question emerges:
How can these models be integrated into production systems in a controllable, engineering-friendly way?
Today, capabilities such as zero-shot forecasting, quantile prediction, and covariate modeling are increasingly available at the algorithmic level. However, if forecasting pipelines still depend on:
data export
external inference
and result write-back
then system complexity and data movement costs rise significantly.

In the evolution of Apache IoTDB, the preferred direction is data–model co-execution. By introducing the native intelligent analytics node (AINode), covariate forecasting can be scheduled and executed directly within the database system.
Once forecasting becomes a native component of the data infrastructure, the role of the time-series database fundamentally shifts—from a pure data management system to an integrated data-and-intelligence platform.
This transition implies that productionizing covariate forecasting is not only an algorithmic upgrade; it also requires a new round of architectural evolution in time-series databases.
Covariate Modeling: A System-Level Capability Upgrade
From univariate prediction to covariate modeling…
From scenario-specific models to general pretrained foundations…
From offline analytics to in-database native inference…
Time-series analytics is undergoing a fundamental shift in modeling paradigms and system architecture..
Within the ongoing evolution of Apache IoTDB, covariate forecasting is viewed as a key strategic direction. The surrounding technologies are being continuously refined and hardened for real-world deployment.
Further practical insights on engineering covariate forecasting inside the database stack will be shared in upcoming work.


