

Introduction
Many teams default to relational databases because they are familiar and versatile. For business systems, that choice is often correct.
But when the workload shifts — from mutable business records to high-frequency telemetry streams — the database architecture begins to matter in very different ways.
Not all data problems are relational. And not all databases are designed for time.
Relational databases (RDBMS) power enterprise systems such as e-commerce platforms, logistics platforms, and ERP systems, thanks to their general-purpose modeling capabilities and strong transactional guarantees.
Time-series databases (TSDB), by contrast, are purpose-built for time-indexed data. They are widely used in industrial IoT, energy systems, observability platforms, monitoring infrastructures, and financial time-series analysis.
To understand when each is appropriate, we compare them across five architectural dimensions.
Transaction Mechanism: Essential vs. Often Secondary
Relational Databases: ACID Is Fundamental
Relational databases support ACID transactions, ensuring atomicity, consistency, isolation, and durability.
Consider a bank transfer:
Account A deducts $10
Account B credits $10
Both operations must either succeed together or fail together. If a system crash or network failure occurs mid-operation, the database must roll back to preserve consistency.
To achieve this in distributed systems, RDBMS engines maintain:
Write-ahead logs (WAL)
State tracking
Concurrency control mechanisms
Rollback and recovery protocols
Transactional integrity is a core requirement because business data is frequently modified and subject to concurrent updates.
Time-Series Databases: Transactions Are Often Less Critical for Ingestion
In many industrial IoT ingestion workloads, data originates from sensors. Each record represents a real-world measurement at a specific timestamp (e.g., temperature, wind speed, voltage).
Typical characteristics:
Data is append-only
Each record is independent
No multi-row atomic updates
No write-write conflicts
In these workloads, heavy transactional coordination adds overhead without delivering proportional value.
TSDB systems therefore trade transactional complexity for ingestion scale — prioritizing high-throughput, stable streaming writes.
Write Patterns: Consistency-Centric vs. Throughput-Centric
Relational Databases: Strong Schema & Consistency
RDBMS typically stores:
Configuration data
Personnel records
Business entities
Financial transactions
Data is often entered via structured forms and must conform strictly to predefined schemas and constraints.
Because of transaction semantics:
Writes are grouped
Entire batches commit or roll back
Consistency is prioritized over raw throughput
This design is ideal for systems where correctness across related entities is critical.
Time-Series Databases: Extreme Write Throughput
Time-series workloads differ dramatically:
Data originates from sensors or devices
Device counts can range from thousands to millions
Sampling intervals may be seconds or milliseconds
Write rates can reach tens of millions of points per second
TSDB systems are engineered for:
High concurrency ingestion
High throughput
Out-of-order data handling
For example, Apache IoTDB leverages its underlying storage format Apache TsFile, enabling:
Columnar data ingestion
Millisecond-level data access
Out-of-order separation storage mechanisms for unstable network environments
Stable high-throughput ingestion in benchmark scenarios
When data volume grows from gigabytes to multi-year telemetry archives, ingestion architecture becomes a scaling boundary — not just a performance metric.
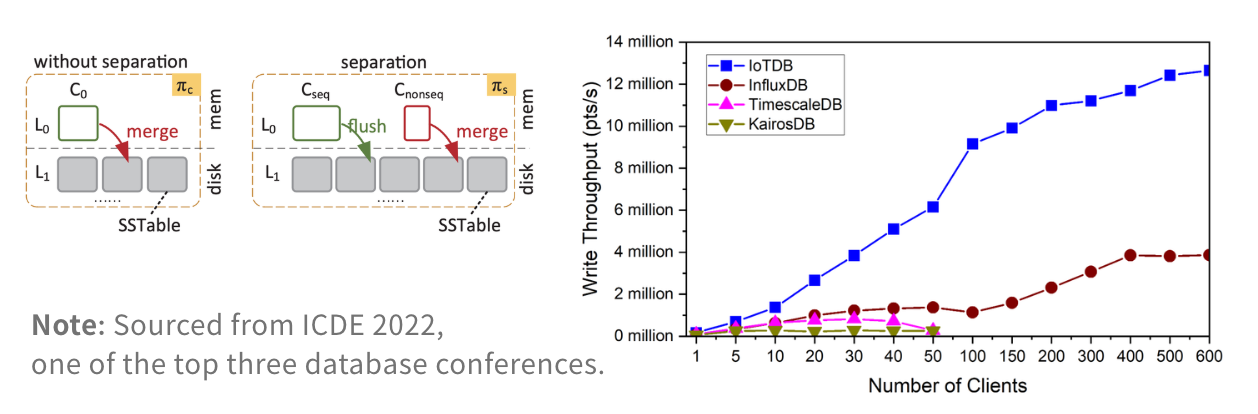 (Figure 1: The out-of-order separation storage engine, 4x performance increased)
(Figure 1: The out-of-order separation storage engine, 4x performance increased)
Storage & Compression: General-Purpose vs. Time-Series-Optimized
Relational Databases: B+ Trees & Generic Compression
RDBMS storage engines typically use:
B+ tree indexing
Row-based or hybrid storage
Generic compression algorithms (LZ77, DEFLATE, etc.)
Compression is optional and tuned based on workload requirements. The storage format is optimized for multi-dimensional querying and transactional consistency.
Time-Series Databases: Time-Series-Optimized Storage
Time-series data exhibits structural properties that storage engines can exploit:
Strong temporal locality
Sequential append patterns
Small deltas between consecutive data points
These characteristics enable:
Columnar storage
Run-Length Encoding (RLE)
Delta encoding
Specialized Compression Algorithm
In IoTDB, the underlying format Apache TsFile provides:
Multi-dimensional indexing (device, sensor, timestamp)
Fast time-range filtering
5-10× query throughput improvement compared to generic formats
Up to 15× higher compression ratios
This significantly reduces storage footprint while improving I/O efficiency.
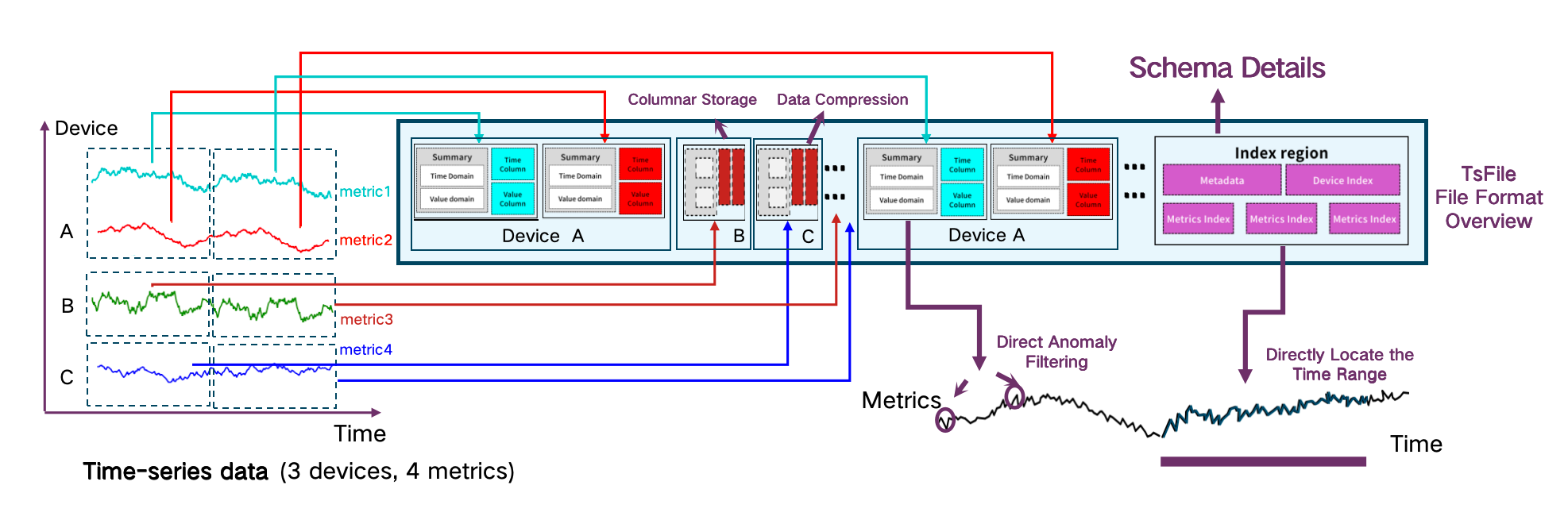
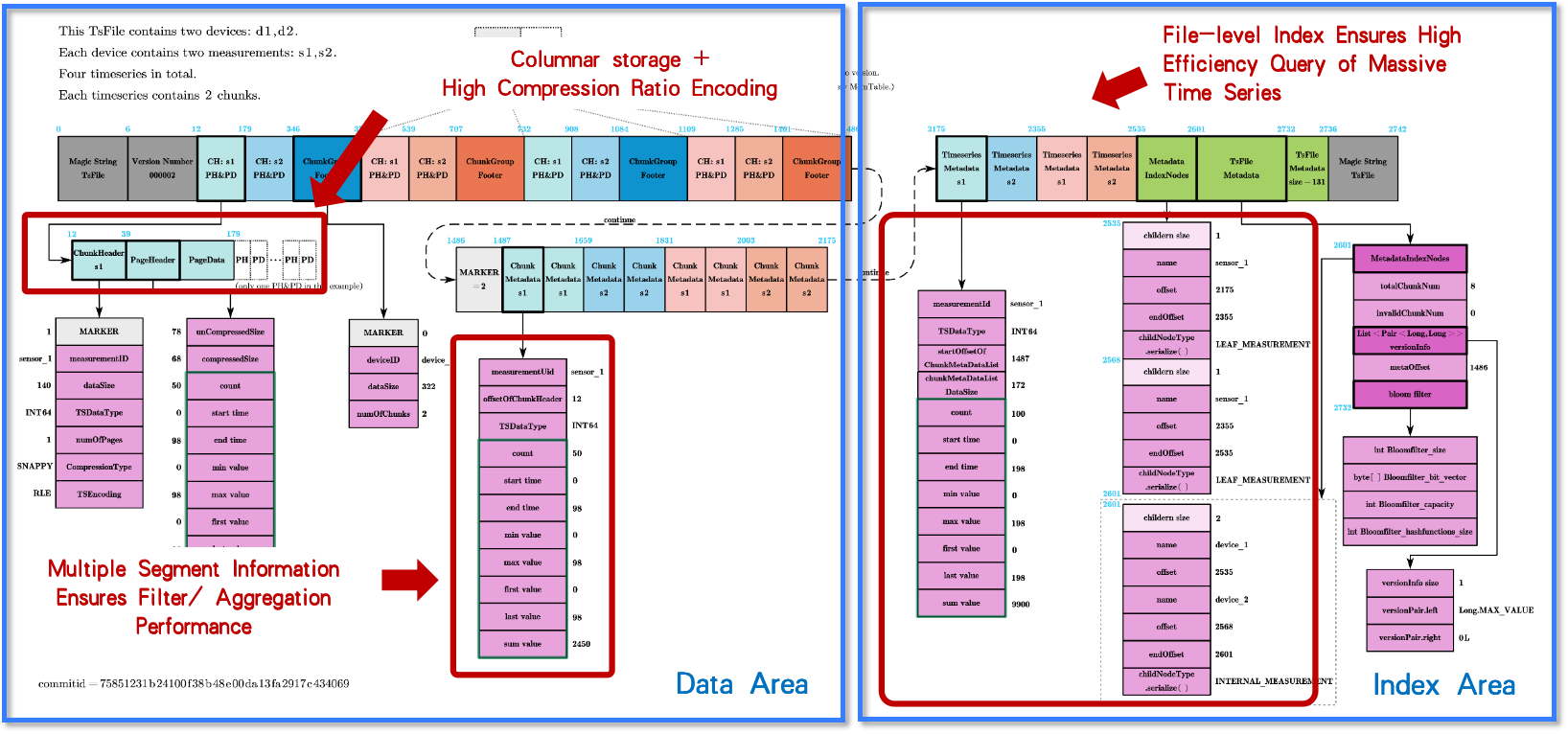 (Figure 2/3: Time-series database: time-aware file formats)
(Figure 2/3: Time-series database: time-aware file formats)
Query Patterns: Precise Retrieval vs. Time-Dimension Analytics
Relational Databases: Entity-Based Querying
Using SQL constructs such as:
SELECT: select target columns.FROM: define the source table.WHERE: set filtering conditions.
RDBMS excel at:
Precise filtering
Multi-table joins
Complex business logic queries
Foreign key relationships
The goal is accurate entity retrieval and relational consistency across structured datasets.
Time-Series Databases: Temporal Analysis at Scale
TSDB queries commonly involve:
Trend analysis over weeks, months, or years
Large-scale aggregation across hundreds of thousands of points
High-frequency dashboard refreshes (e.g., hundreds of metrics per second)
Users expect:
High query throughput
Efficient time-window filtering
Native time-series processing capabilities
IoTDB supports:
High-throughput time-range queries via TsFile
Downsampling for visualization efficiency
Nearly 100 built-in time-series processing functions, including segmentation, gap filling, and data repair.
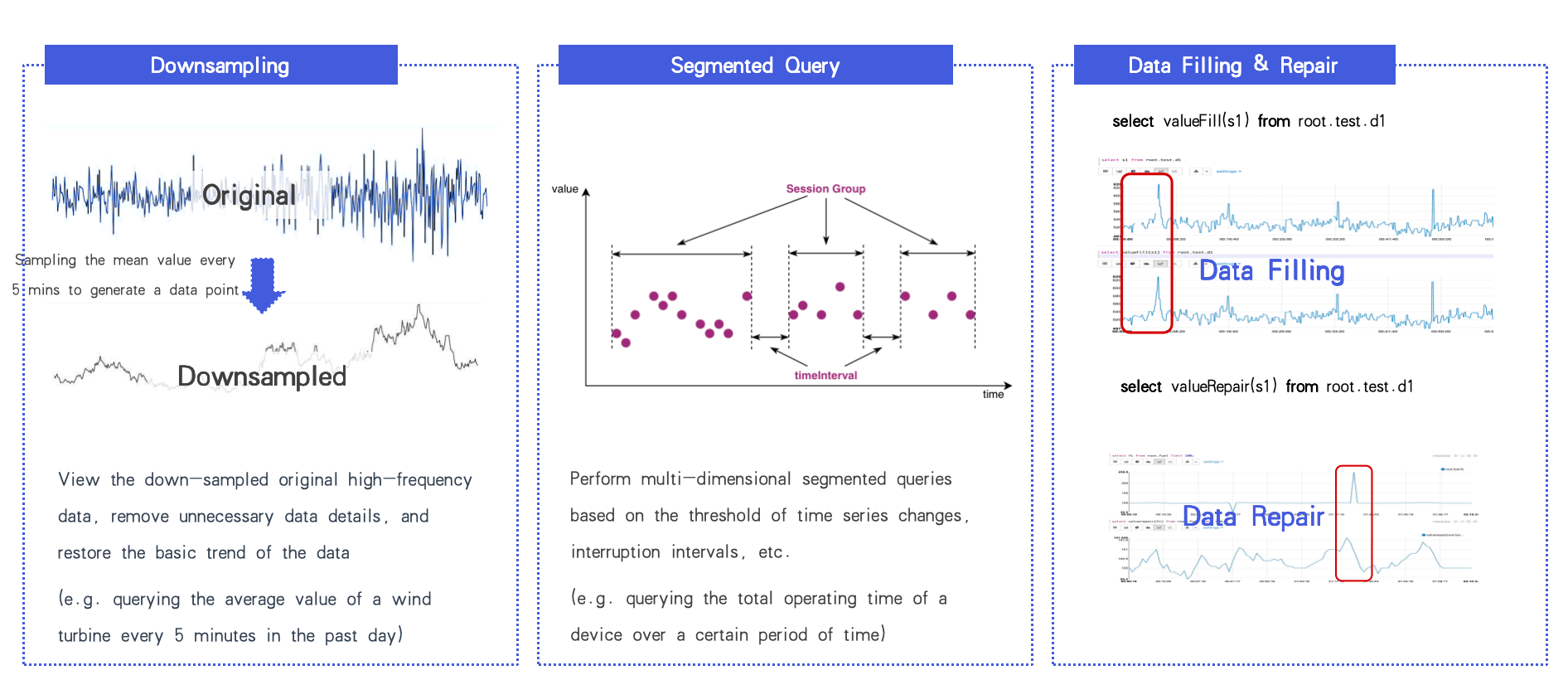 (Figure 4: Multi-functions via TsFile)
(Figure 4: Multi-functions via TsFile)
Data Circulation: Centralized Management vs. Edge-Cloud Collaboration
Relational Databases: Platform-Centric Storage
RDBMS systems typically:
Store internal business data
Use proprietary storage formats
Serve centralized application workloads
Data migration often requires format conversion when systems evolve.
Time-Series Databases: Edge-Cloud Synchronization
Industrial IoT architectures frequently involve:
Devices → Edge nodes → Regional data centers → Central cloud platforms
Additional constraints may include:
Production network isolation
One-way data gateways
Bandwidth limitations
TSDB systems must optimize:
Efficient cross-terminal synchronization
Low-bandwidth replication
Minimal CPU overhead
Efficient file-based transfer
IoTDB addresses this through its unified TsFile format, enabling file-based data exchange and subscription-based synchronization, reducing re-processing overhead compared to re-ingestion-based approaches, achieving up to 90% network bandwidth savings and 95% CPU savings on receiving nodes.
In distributed industrial systems, data mobility can be as important as raw database performance.
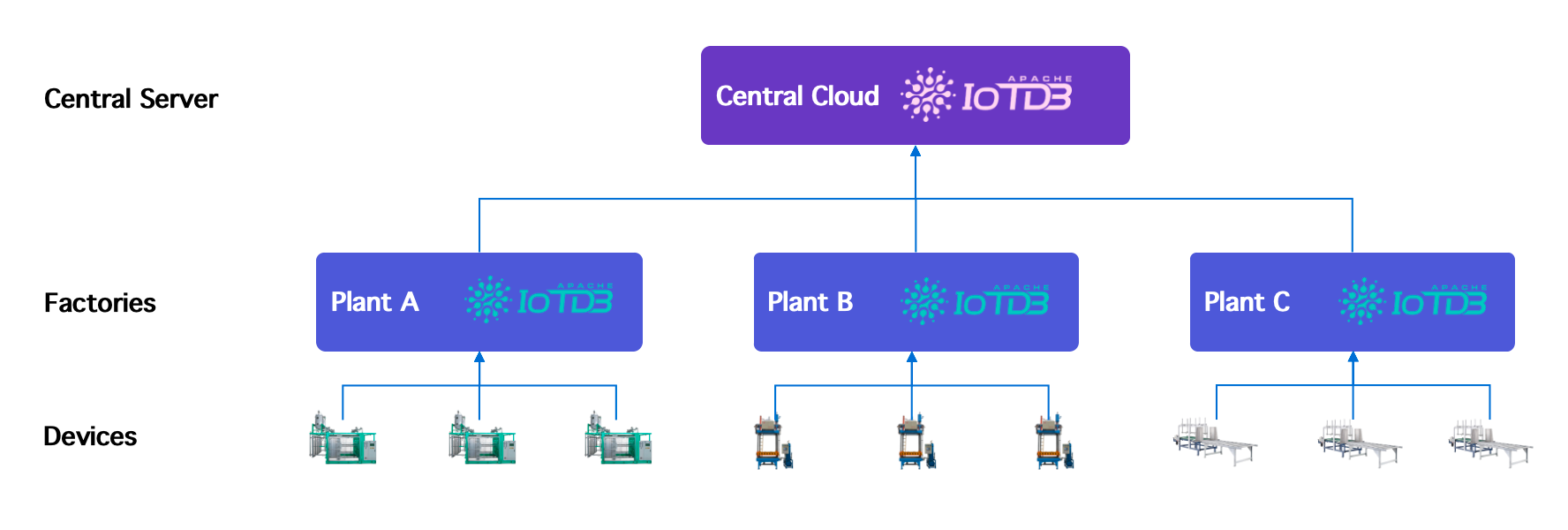 (Figure 5: Edge-cloud data synchronization solution)
(Figure 5: Edge-cloud data synchronization solution)
Conclusion
The differences between time-series databases and relational databases stem fundamentally from the nature of the data they serve:
When choosing between a TSDB and an RDBMS, organizations should evaluate:
Data generation patterns (Is it time-correlated?)
Write throughput requirements
Query complexity
Edge-to-cloud synchronization needs
Infrastructure constraints
Selecting the correct database architecture is not merely a technical preference—it directly impacts scalability ceilings, infrastructure cost, and long-term operational efficiency.
This is not a feature comparison.
It is a workload architecture decision.


