

Introduction
In a distributed cluster, to enable horizontal scaling for large data scenarios, the cluster needs to partition all data according to specific rules and store it across different nodes. This approach allows for better utilization of the computing and storage resources of each node. For any shard in the cluster, to ensure high availability, the data needs to be redundantly stored as multiple replicas on different physical nodes, thus avoiding single points of failure.
However, having multiple replicas of the same data may lead to inconsistencies among different replicas. Existing distributed systems typically address data consistency issues among multiple replicas through consensus algorithms.
Different business scenarios require different levels of consistency and availability from consensus algorithms. For instance, in application monitoring scenarios, Google's time-series database Monarch emphasizes availability over consistency for monitoring data. However, for crucial metadata like data partitions, it still uses the externally consistent Spanner database.
For Apache IoTDB, a distributed time-series database designed for IoT scenarios, it is often suitable to choose consensus algorithms that favor availability for time-series data. Conversely, for core information like partition data and metadata, stronger consistency algorithms are usually preferred.
This article will discuss consensus algorithms, explaining the trade-offs IoTDB makes in terms of consistency, availability, and performance. It will introduce IoTDB's unique consensus algorithm framework, helping you understand and master various consensus strategies in IoTDB, allowing flexible selection and configuration based on your business needs.
Consensus Algorithms
Why Consensus Algorithms are Needed
In the previous part (Distributed Architecture Trilogy Part 2), we mentioned that distributed systems enhance overall availability and performance by horizontally scaling through sharding and redundantly storing multiple replicas on different physical nodes. IoTDB adopts a horizontally scalable distributed architecture, as shown below:
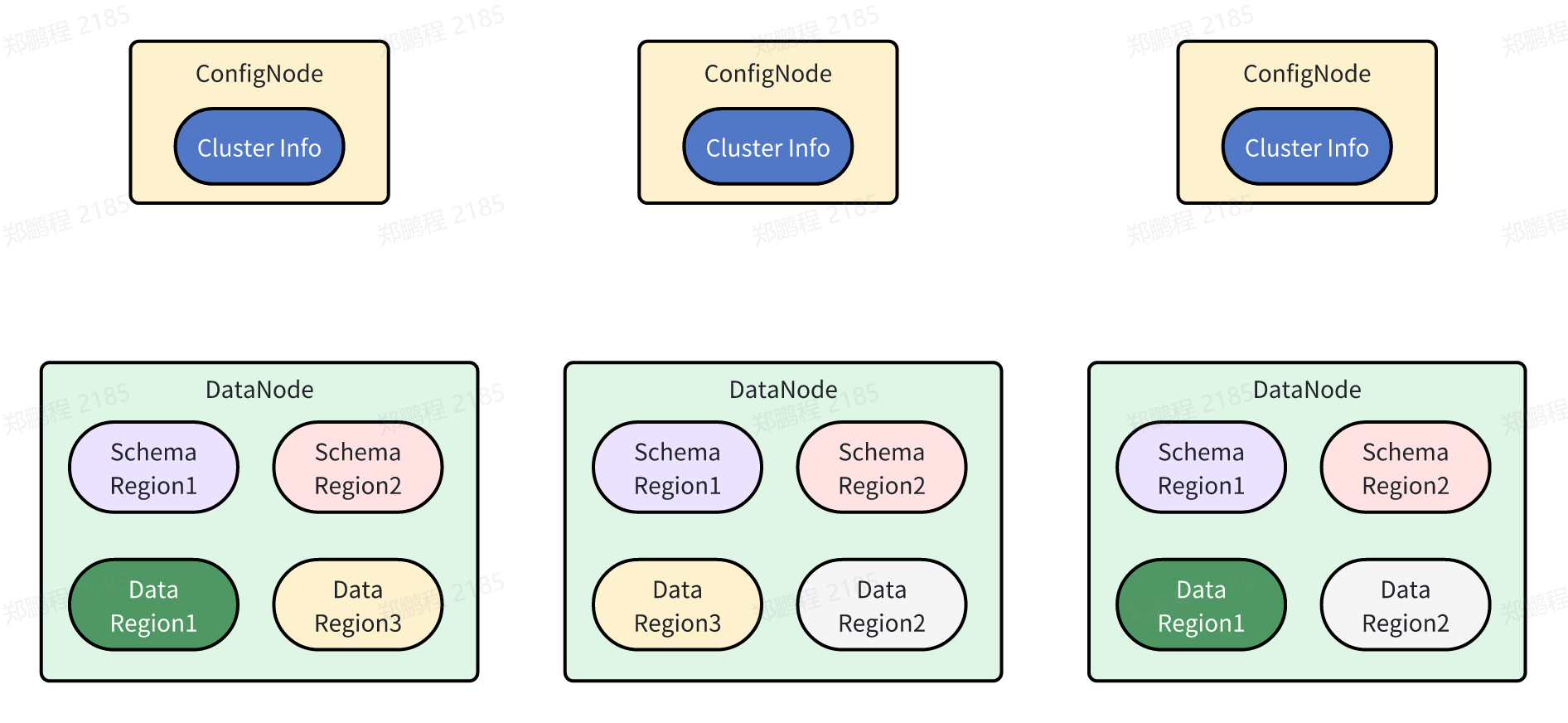
Although the multi-replica design of distributed systems greatly increases system availability and performance, it also presents challenges such as:
How to ensure data consistency among different replicas?
Which replica to trust when different replicas receive different write requests simultaneously?
How to recover a replica on other nodes when a node fails?
Which replica to query for the best results?
Consensus algorithms are designed to address these challenges, allowing users to enjoy high availability and performance while being unaware of the existence of multiple replicas.
Concepts and Classification of Consensus Algorithms
Consensus algorithms are a critical mechanism in distributed systems, used to reach unanimous decisions among multiple participating nodes. Even in the presence of network delays, node failures, or malicious attacks, these algorithms ensure system consistency and reliability. In distributed systems, replicas on different nodes may be in inconsistent states, and the goal of consensus algorithms is to ensure that all nodes eventually agree, forming a unified decision, thus maintaining overall system consistency.
Over nearly half a century of development, consensus algorithms have become numerous and complex. They vary in replication modes and consistency levels. Generally, we can classify consensus algorithms based on their replication modes and consistency guarantees.
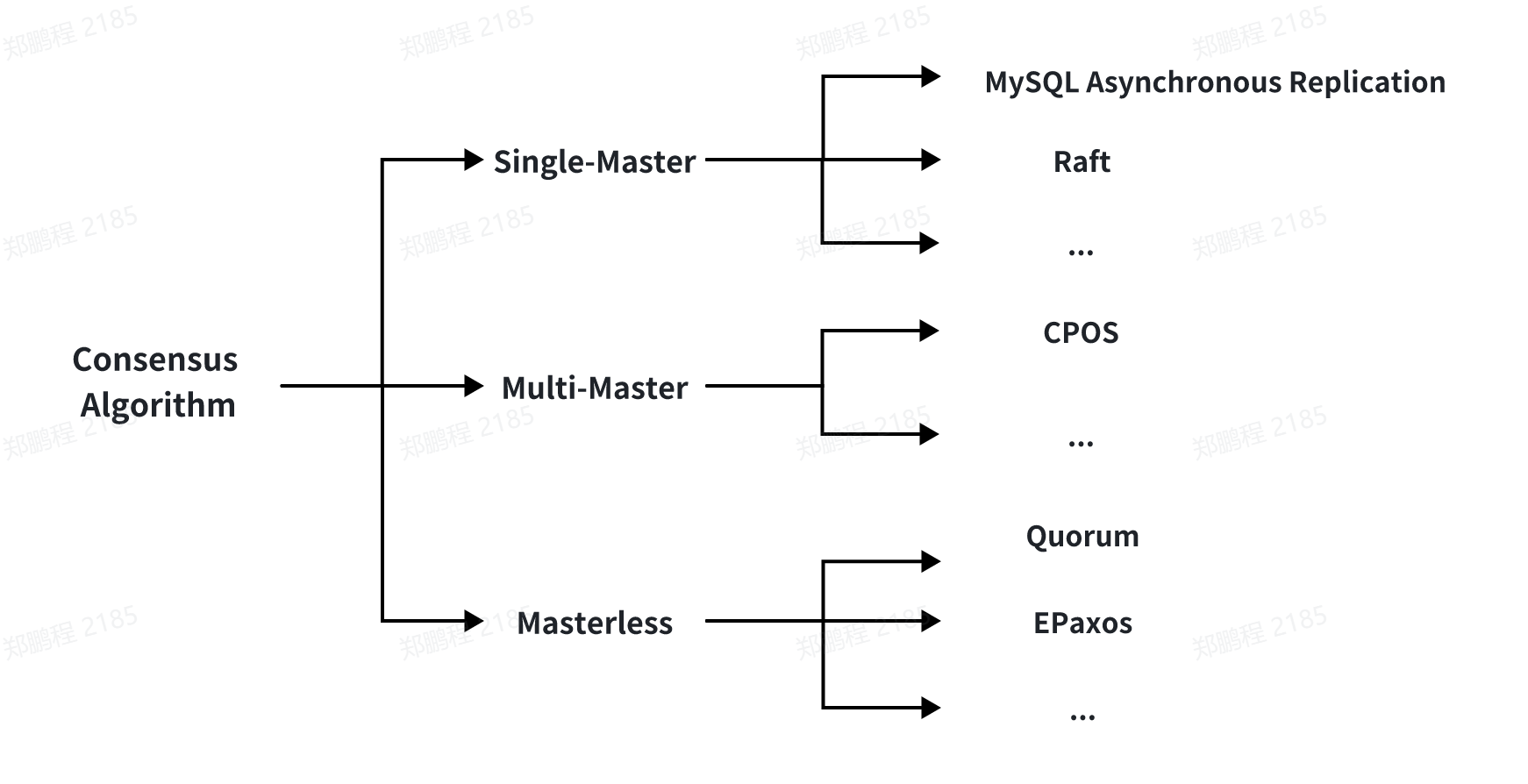
By Replication Mode:
Single-Master Replication: The client sends all write operations to a single node (the master), which streams data change events to other replicas (slaves). Reads can be performed on any replica, but the results from slaves might be stale.
Multi-Master Replication: The client sends each write to one of several master nodes, any of which can accept writes. Masters stream data change events to each other and any slave nodes.
Masterless Replication: The client sends each write to several nodes and reads from multiple nodes in parallel to detect and correct nodes with stale data.
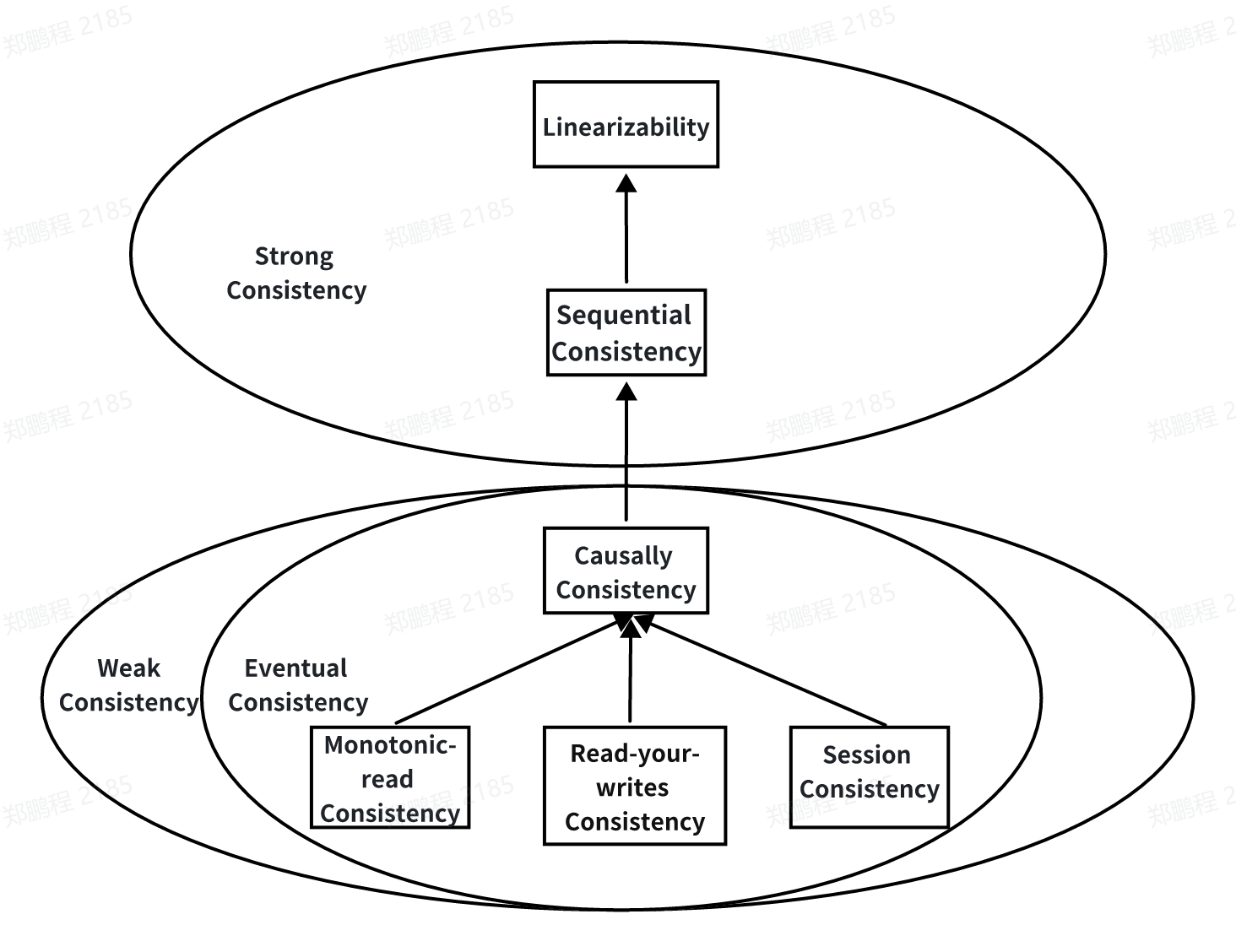
By Consistency Guarantee:
Strong Consistency: Ensures linearizability or sequential consistency. Linearizability is the strongest level, while sequential consistency is slightly weaker. If a consensus algorithm provides strong consistency, any subsequent read operation will always reflect the latest data value once a write operation completes. Although it ensures data consistency, it often comes at a performance cost since each write operation must be confirmed and completed by the majority of related nodes.
Weak Consistency: Typically provides eventual consistency, including causal consistency, monotonic read consistency, read-your-writes consistency, and session consistency. If a consensus algorithm provides weak consistency, the system allows temporary data state differences among nodes, eventually reaching consistency at some point or under specific conditions. Weak consistency designs are more flexible, improving system performance and availability, but they sacrifice some consistency.
For most consensus algorithms, we can identify their replication mode and consistency guarantee based on the descriptions above. Different consensus algorithms usually differ in performance, availability, and consistency guarantees. Generally, providing higher consistency levels often leads to reduced performance and availability.
Introduction to Mainstream Consensus Algorithms
From the previous introduction, you should have a basic understanding of the concepts, functions, and classifications of consensus algorithms. Next, let's briefly introduce two famous consensus algorithms and understand their differences in terms of availability, consistency, performance, and storage cost.
Raft
Raft is a leader-based strong consistency consensus algorithm. It decomposes the consensus process into several key sub-processes: leader election, log replication, and safety guarantees. By structuring the consensus process, Raft is not only easy to understand but also easy to implement, with multiple mature industrial implementations available.
Raft's understandability enables developers to quickly implement and debug distributed systems, while its strong consistency guarantees enhance system reliability and maintainability. As a strong consistency algorithm, Raft requires the majority (more than half) of nodes to respond for each write and necessitates log persistence, resulting in lower performance compared to weak consistency algorithms. Additionally, Raft's requirement for majority nodes to be operational limits availability. The need for persistent logs also increases storage costs.
Quorum
Quorum is the most famous masterless consensus algorithm. In Quorum, each copy of distributed system data is given a vote. Only when each read operation receives more than the minimum read votes and each write operation receives more than the minimum write votes can it proceed. In case of data inconsistency among nodes, it uses read repair and anti-entropy to ensure eventual consistency.
Quorum typically provides only eventual consistency, which is a weak consistency guarantee. Due to its lower consistency level, Quorum may not meet the consistency requirements of many applications. For example, Cassandra currently uses Paxos to manage lightweight transactions.
Quorum's read and write minimum votes can be adjusted to balance read and write performance. A higher write vote (V(w)) compared with read vote (V(r)) reduces read costs, and vice versa. Since Quorum reads and writes only need to operate on a subset of replicas, the minimum votes can be balanced based on read and write needs for better performance.
Unified Consensus Algorithm Framework
Consensus algorithms are core components of the critical path for data read and write operations in distributed systems. If each consensus algorithm independently implements its interfaces, it will inevitably lead to substantial special handling and adaptation for various consensus algorithms by other modules, negatively impacting system iteration efficiency and maintenance costs. Additionally, this would challenge future system scalability when integrating new consensus algorithms.
To improve the scalability and maintainability of system architecture, some distributed systems consider designing a unified consensus algorithm framework that supports different consensus algorithm implementations while providing a unified interface.
Next, let’s briefly understand the unified consensus algorithm framework proposed by the OSDI 2020 Best Paper, Virtual Consensus in Delos, and see the benefits it brings. [1] We will also detail IoTDB’s unified consensus algorithm framework later.
Facebook’s Delos abstracts virtual consensus services through a shared log, allowing different consensus algorithms to be implemented underneath without affecting the application layer and supporting seamless algorithm changes. These features unify all metadata management solutions within Facebook.
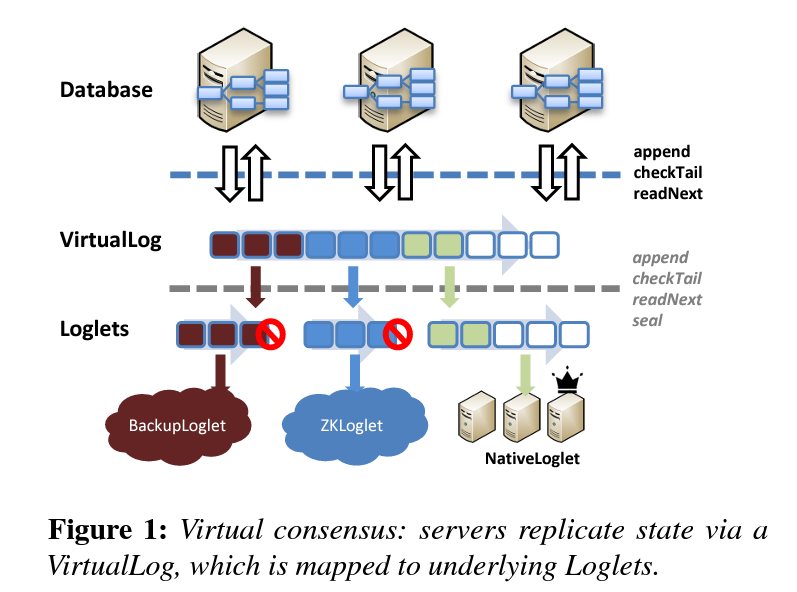
As shown in the figure above, the Delos framework encapsulates multiple complex consensus algorithms. It provides a unified VirtualLog API interface and integrates multiple consensus algorithms underneath. Each segment of a VirtualLog is called a Loglet, which can use different consensus algorithms.
Delos dynamically maintains Loglets, supporting dynamic consensus algorithm changes. Notably, Delos initially implemented a simple Zookeeper-based consensus solution called ZKLoglets. Eight months later, it successfully transitioned all consensus algorithms in the production environment from ZKLoglets to a custom NativeLoglets, achieving a tenfold performance improvement.
Consensus Algorithm Framework in Apache IoTDB
Having introduced consensus algorithms and the unified consensus algorithm framework, let’s delve into IoTDB’s internal consensus algorithm framework and the consensus algorithms it supports.
Concepts and Examples
Node: Corresponds to a process, which can be a physical node or a container runtime environment.
ConsensusGroup: Defines a consensus group corresponding to a shard in sharding technology. It logically exists on several Nodes, maintaining multiple replicas of data.
Peer: A logical unit of a ConsensusGroup on a Node. A ConsensusGroup on a Node corresponds to a Peer, with multiple Peers across nodes.
IStateMachine: The structure managing underlying storage engine data for a consensus group, maintaining a local replica of data. Each IStateMachine is logically owned by a Peer and exists on a Node.
IConsensus: The entry point for the consensus layer to provide services, managing all Peers on the Node, offering functions like adding/removing consensus groups, changing consensus group members, and reading/writing consensus group data. Developers can specify different consensus algorithm implementations (e.g., weak consistency IoTConsensus or strong consistency RatisConsensus) when creating IConsensus through configuration parameters.
As shown in the figure below, in IoTDB’s unified consensus algorithm framework, a piece of user data is managed by a consensus group (ConsensusGroup) composed of multiple Peers. Each Peer manages a local replica of the data through a user-defined IStateMachine. IConsensus manages all Peers belonging to different consensus groups within the process. IConsensus serves as the consensus layer’s external service entry, including creating consensus groups, changing group members, and reading/writing group data.
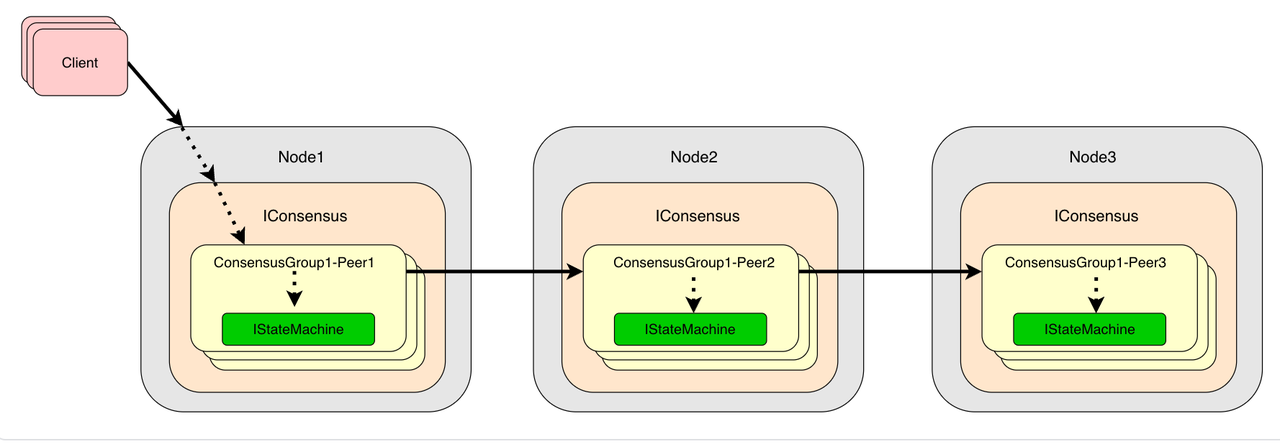
For a 4-node, 3-replica cluster, assuming the cluster partitions all data into two shards, the schematic diagram is as follows:
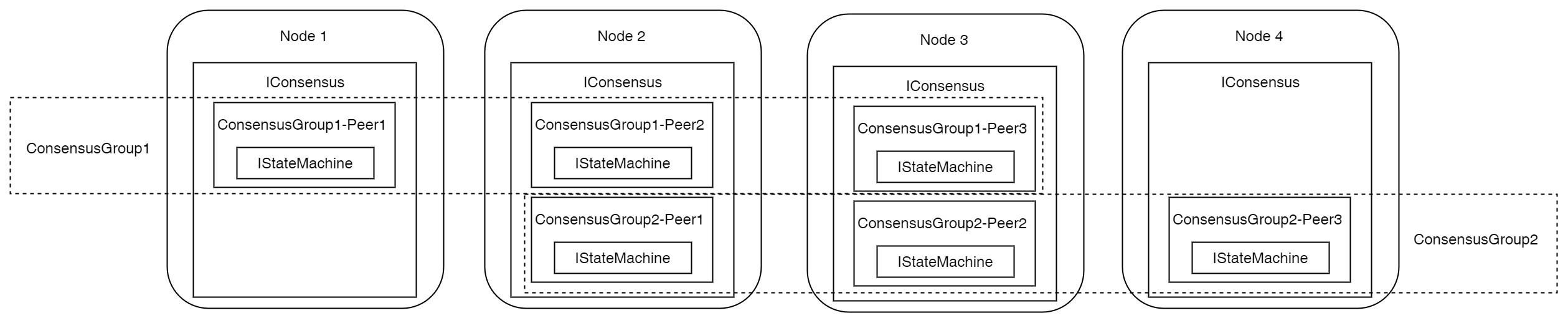
From the above diagram, we can gather the following information:
The entire cluster has four Nodes, each Node with an IConsensus instance.
The entire cluster has two shards, i.e., two ConsensusGroups. ConsensusGroup1 exists on Node1, Node2, and Node3, while ConsensusGroup2 exists on Node2, Node3, and Node4.
Node1’s IConsensus manages Peer1 of ConsensusGroup1, corresponding to one IStateMachine instance, holding half of the cluster’s data.
Node2’s IConsensus manages Peer2 of ConsensusGroup1 and Peer1 of ConsensusGroup2, corresponding to two IStateMachine instances, holding all the cluster’s data.
Node3’s IConsensus manages Peer3 of ConsensusGroup1 and Peer2 of ConsensusGroup2, corresponding to two IStateMachine instances, holding all the cluster’s data.
Node4’s IConsensus manages Peer3 of ConsensusGroup2, corresponding to one IStateMachine instance, holding half of the cluster’s data.
Current Supported Consensus Algorithms
Currently, the consensus layer supports three different consensus algorithms:
SimpleConsensus: A single-replica strong consistency consensus algorithm optimized for single-replica scenarios.
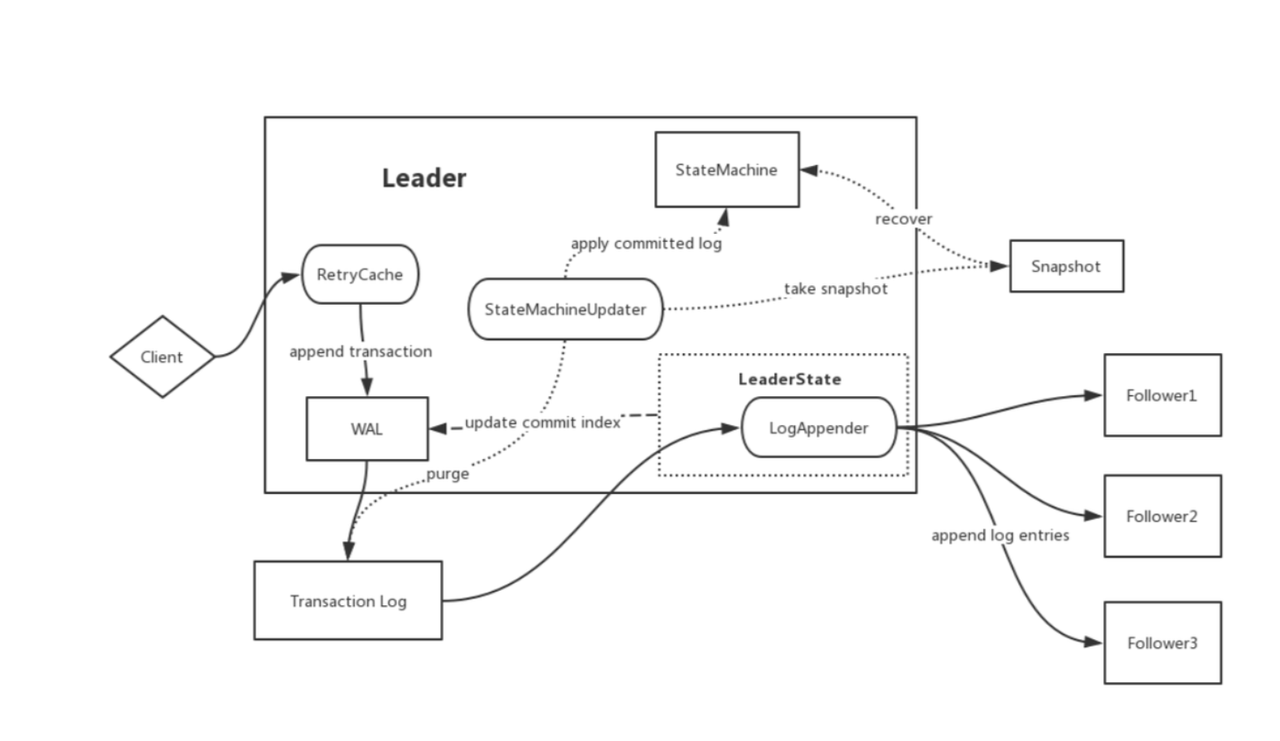
RatisConsensus: A multi-replica single-leader strong consistency consensus algorithm, based on the industrial Raft algorithm implementation in Apache Ratis.
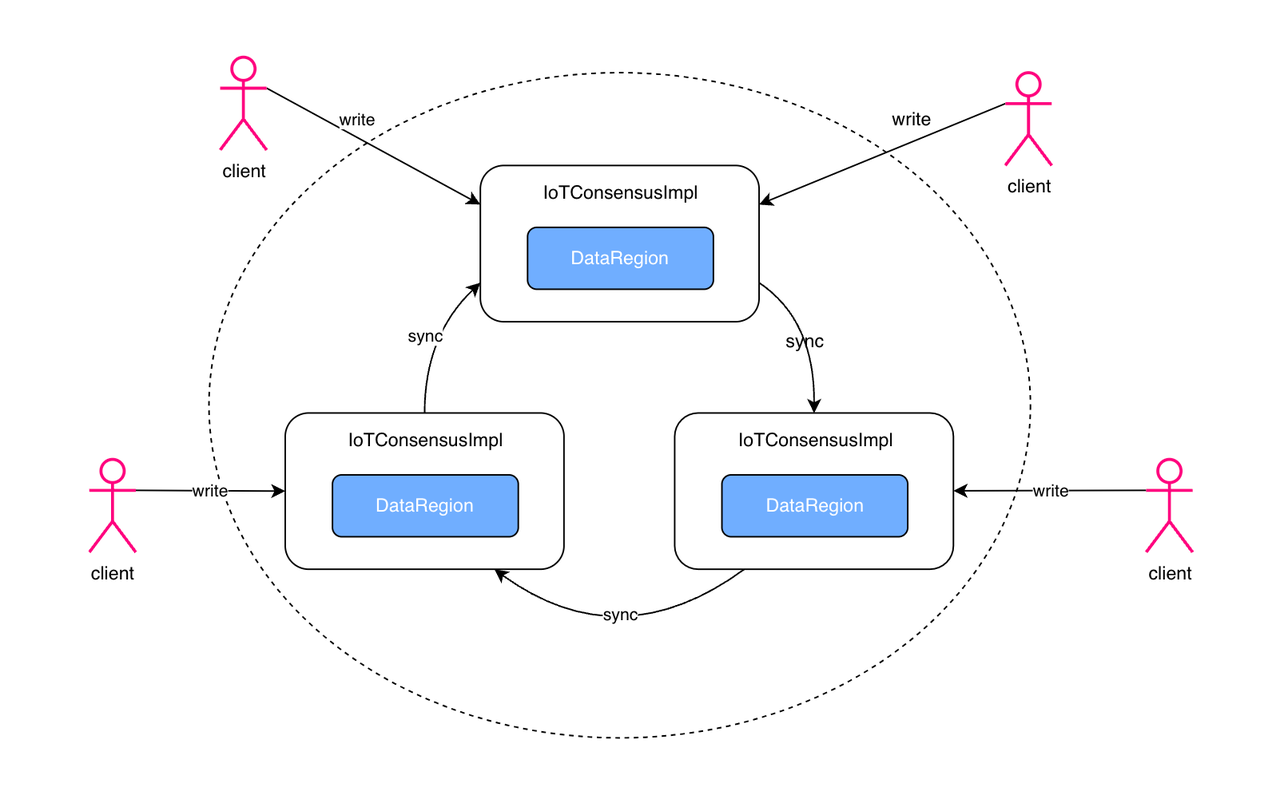
IoTConsensus: A multi-replica multi-leader weak consistency consensus algorithm designed for IoT scenarios, achieving high availability with only two replicas. Through asynchronous replication and extensive engineering optimizations, it provides nearly real-time synchronization performance. In IoT scenarios, write operations for different devices are usually independent, with minimal write-write conflicts between concurrent requests. Based on this characteristic, IoTConsensus can provide eventual consistency or even session consistency semantics.
Configuring IoTDB Consensus Algorithms
For IoTDB, you can configure the consensus algorithms by modifying the following configuration items in iotdb-system.properties.
Choosing a Consensus Algorithm
config_node_consensus_protocol_class: Consensus algorithm used by ConfigNode, which can be SimpleConsensus or RatisConsensus.
schema_region_consensus_protocol_class: Consensus algorithm used for metadata, which can be SimpleConsensus or RatisConsensus.
data_region_consensus_protocol_class: Consensus algorithm used for regular data, which can be SimpleConsensus, RatisConsensus, or IoTConsensus.
Replication Factor
The replication factor indicates the number of redundant storage copies for data shards. Generally, the more replicas, the higher the system's availability but the more resources it consumes.
schema_replication_factor: Number of metadata replicas.
data_replication_factor: Number of regular data replicas.
Load Balancing
Leader balance distributes leaders evenly across nodes to balance write traffic. We can choose whether to enable leader balance for RatisConsensus and IoTConsensus.
enable_auto_leader_balance_for_ratis_consensus: Enable leader balance for RatisConsensus.
enable_auto_leader_balance_for_iot_consensus: Enable leader balance for IoTConsensus.
How to Choose IoTDB Consensus Algorithms
SimpleConsensus: A lightweight single-replica consensus algorithm. In user scenarios where hardware cost is a concern, some users prefer deploying clusters with single replicas to save resources and costs. SimpleConsensus is designed to provide an economical option for scenarios with high scalability demands but lower availability requirements. It is usually used in single-replica deployment scenarios.
RatisConsensus: An industrial implementation of the Raft protocol, supporting Multi-Raft strong consistency consensus algorithms. It is typically used in ConfigNode and metadata management scenarios. Notably, the IoTDB community, in collaboration with the Ratis community, has extensively optimized RatisConsensus, ensuring it offers strong consistency guarantees with relatively ideal performance.
IoTConsensus: A weak consistency multi-leader consensus algorithm developed by the IoTDB team, tailored to the business characteristics of IoT scenarios. This algorithm not only performs better but also has higher availability. Compared to RatisConsensus, which requires three replicas for high availability, IoTConsensus achieves high availability with just two replicas, making it more cost-effective in terms of storage. This algorithm is typically used for managing time-series data.
Conclusion
Distributed systems achieve high availability and high performance by horizontally scaling and redundantly storing data on multiple physical nodes. In this process, consensus algorithms coordinate the actions of multiple nodes to ensure overall cluster consistency.
Compared to other time-series databases in the industry, Apache IoTDB is the first and only system to propose and apply a unified consensus protocol framework. Users can flexibly choose different consensus algorithms based on performance, availability, consistency, and storage cost requirements.
Notably, for the multi-leader weak consistency consensus algorithm IoTConsensus, developed by the IoTDB community specifically for IoT scenarios, while it already offers high performance and availability, there is still room for optimization in terms of performance and availability due to the use of WAL for replica synchronization. Recently, we have optimized IoTConsensus by using Apache TsFile for data synchronization, decoupling it from WAL, and further enhancing its performance and availability. This new consensus algorithm, FastIoTConsensus, is currently in internal testing and will be released soon. Stay tuned!
This article is the final part of the Apache IoTDB Distributed Trilogy. Through the trilogy, covering clusters, sharding and load balancing, replication and consensus algorithms, we hope you now have a deep understanding of IoTDB’s overall distributed architecture and design philosophy.[3][4] We expect the trilogy to help you effectively utilize IoTDB’s consensus algorithms, load balancing, and other distributed strategies to tackle complex IoT data management challenges!
Reference
[1] Balakrishnan, Mahesh, et al. "Virtual Consensus in Delos." 14th USENIX Symposium on Operating Systems Design and Implementation (OSDI 20), USENIX Association, 2020, pp. 617-632. https://www.usenix.org/conference/osdi20/presentation/balakrishnan
[2] Apache IoTDB, https://iotdb.apache.org/
[3] Apache IoTDB Distributed Architecture Trilogy: Part 1 - Cluster Concepts, https://www.timecho-global.com/archives/apache-iotdb-distributed-architecture-1-cluster-concepts
[4] Apache IoTDB Distributed Architecture Trilogy: Part 2 - Data Sharding and Load Balancing, https://www.timecho-global.com/archives/apache-iotdb-distributed-architecture-2-sharding-and-load-balancing
Authors
This article is a collective effort by several dedicated contributors from the Apache IoTDB community. We appreciate the valuable input and thorough reviews from our community members, ensuring the accuracy and quality of this publication.
For any questions or further discussions, please feel free to reach out to Xinyu Tan (tanxinyu@apache.org), senior software engineer at Timecho and one of the authors.
We look forward to hearing from you!


