
Timeseries Featured Analysis
Timeseries Featured Analysis
For time-series data feature analysis scenarios, IoTDB provides two core capabilities: pattern query and window functions. These capabilities deliver a flexible and efficient solution for in-depth mining and complex computation of time-series data. The following sections will elaborate on the two features in detail.
1. Pattern Query
1.1 Overview
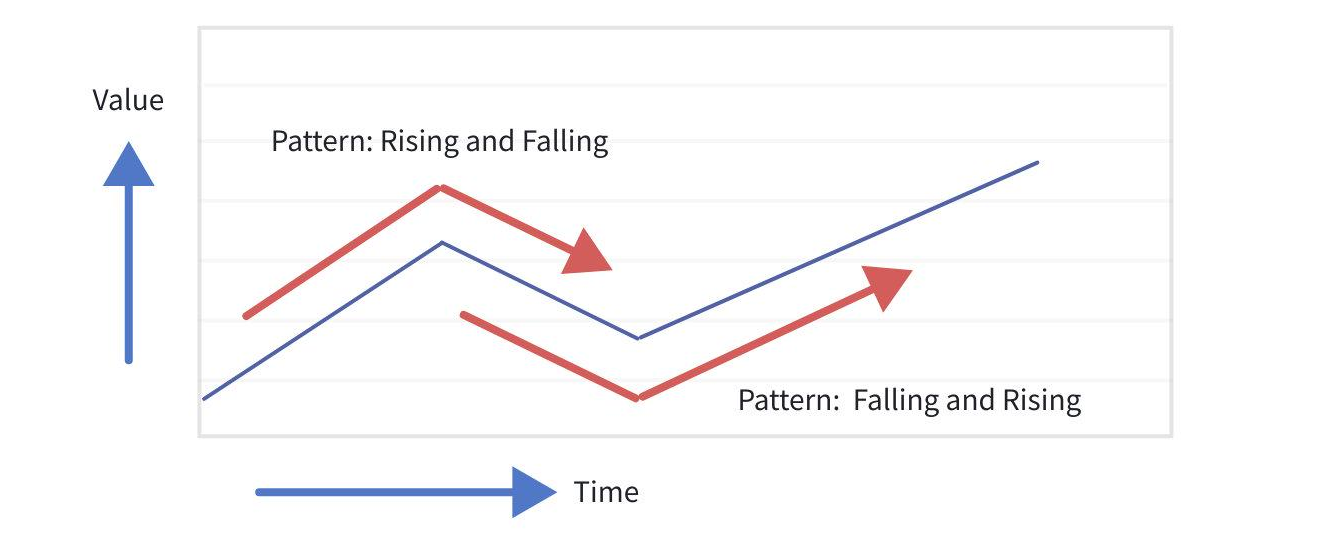
Pattern query enables capturing a segment of continuous data by defining the recognition logic of pattern variables and regular expressions, and performing analysis and calculation on each captured data segment. It is suitable for business scenarios such as identifying specific patterns in time-series data (as shown in the figure below) and detecting specific events.
Note: This feature is available starting from version V2.0.5.
1.2 Function Introduction
1.2.1 Syntax Format
MATCH_RECOGNIZE (
[ PARTITION BY column [, ...] ]
[ ORDER BY column [, ...] ]
[ MEASURES measure_definition [, ...] ]
[ ROWS PER MATCH ]
[ AFTER MATCH skip_to ]
PATTERN ( row_pattern )
[ SUBSET subset_definition [, ...] ]
DEFINE variable_definition [, ...]
)Note:
- PARTITION BY: Optional. Used to group the input table, and each group can perform pattern matching independently. If this clause is not specified, the entire input table will be processed as a single unit.
- ORDER BY: Optional. Used to ensure that input data is processed in a specific order during matching.
- MEASURES: Optional. Used to specify which information to extract from the matched segment of data.
- ROWS PER MATCH: Optional. Used to specify the output method of the result set after successful pattern matching.
- AFTER MATCH SKIP: Optional. Used to specify which row to resume from for the next pattern match after identifying a non-empty match.
- PATTERN: Used to define the row pattern to be matched.
- SUBSET: Optional. Used to merge rows matched by multiple basic pattern variables into a single logical set.
- DEFINE: Used to define the basic pattern variables for the row pattern.
Original Data for Syntax Examples:
IoTDB:database3> select * from t
+-----------------------------+------+----------+
| time|device|totalprice|
+-----------------------------+------+----------+
|2025-01-01T00:01:00.000+08:00| d1| 90|
|2025-01-01T00:02:00.000+08:00| d1| 80|
|2025-01-01T00:03:00.000+08:00| d1| 70|
|2025-01-01T00:04:00.000+08:00| d1| 80|
|2025-01-01T00:05:00.000+08:00| d1| 70|
|2025-01-01T00:06:00.000+08:00| d1| 80|
+-----------------------------+------+----------+
-- Creation Statement
create table t(device tag, totalprice int32 field)
insert into t(time,device,totalprice) values(2025-01-01T00:01:00, 'd1', 90),(2025-01-01T00:02:00, 'd1', 80),(2025-01-01T00:03:00, 'd1', 70),(2025-01-01T00:04:00, 'd1', 80),(2025-01-01T00:05:00, 'd1', 70),(2025-01-01T00:06:00, 'd1', 80)1.2.2 DEFINE Clause
Used to specify the judgment condition for each basic pattern variable in pattern recognition. These variables are usually represented by identifiers (e.g., A, B), and the Boolean expressions in this clause precisely define which rows meet the requirements of the variable.
- During pattern matching execution, a row is only marked as the variable (and thus included in the current matching group) if the Boolean expression returns TRUE.
-- A row can only be identified as B if its totalprice value is less than the totalprice value of the previous row.
DEFINE B AS totalprice < PREV(totalprice)- Variables not explicitly defined in this clause have an implicitly set condition of always true (TRUE), meaning they can be successfully matched on any input row.
1.2.3 SUBSET Clause
Used to merge rows matched by multiple basic pattern variables (e.g., A, B) into a combined pattern variable (e.g., U), allowing these rows to be treated as a single logical set for operations. It can be used in the MEASURES, DEFINE, and AFTER MATCH SKIP clauses.
SUBSET U = (A, B)For example, for the pattern PATTERN ((A | B){5} C+), it is impossible to determine whether the 5th repetition matches the basic pattern variable A or B during matching. Therefore:
- In the
MEASURESclause, if you need to reference the last row matched in this phase, you can do so by defining the combined pattern variableSUBSET U = (A, B). At this point, the expressionRPR_LAST(U.totalprice)will directly return thetotalpricevalue of the target row. - In the
AFTER MATCH SKIPclause, if the matching result does not include the basic pattern variable A or B, executingAFTER MATCH SKIP TO LAST BorAFTER MATCH SKIP TO LAST Awill fail to jump due to missing anchors. However, by introducing the combined pattern variableSUBSET U = (A, B), usingAFTER MATCH SKIP TO LAST Uis always valid.
1.2.4 PATTERN Clause
Used to define the row pattern to be matched, whose basic building block is a row pattern variable.
PATTERN ( row_pattern )1.2.4.1 Pattern Types
| Row Pattern | Syntax Format | Description |
|---|---|---|
| Pattern Concatenation | A B+ C+ D+ | Composed of subpatterns without any operators, matching all subpatterns in the declared order sequentially. |
| Pattern Alternation | A | B | C | Composed of multiple subpatterns separated by |, matching only one of them. If multiple subpatterns can be matched, the leftmost one is selected. |
| Pattern Permutation | PERMUTE(A, B, C) | Equivalent to performing alternation matching on all different orders of the subpattern elements. It requires that A, B, and C must all be matched, but their order of appearance is not fixed. If multiple matching orders are possible, the priority is determined by the lexicographical order based on the definition sequence of elements in the PERMUTE list. For example, A B C has the highest priority, while C B A has the lowest. |
| Pattern Grouping | (A B C) | Encloses subpatterns in parentheses to treat them as a single unit, which can be used with other operators. For example, (A B C)+ indicates a pattern where a group of (A B C) appears consecutively. |
| Empty Pattern | () | Represents an empty match that does not contain any rows. |
| Pattern Exclusion | {- row_pattern -} | Used to specify the matched part to be excluded from the output. Usually used with the ALL ROWS PER MATCH option to output rows of interest. For example, PATTERN (A {- B+ C+ -} D+) with ALL ROWS PER MATCH will only output the first row (corresponding to A) and the trailing rows (corresponding to D+) of the match. |
1.2.4.2 Partition Start/End Anchor
^Aindicates matching a pattern that starts with A as the partition beginning- When the value of the PATTERN clause is
^A, the match must start from the first row of the partition, and this row must satisfy the definition ofA. - When the value of the PATTERN clause is
^A^orA^, the output result is empty.
- When the value of the PATTERN clause is
A$indicates matching a pattern that ends with A as the partition end- When the value of the PATTERN clause is
A$, the match must end at the end of the partition, and this row must satisfy the definition ofA. - When the value of the PATTERN clause is
$Aor$A$, the output result is empty.
- When the value of the PATTERN clause is
Examples
- Query sql
SELECT m.time, m.match, m.price, m.label
FROM t
MATCH_RECOGNIZE (
ORDER BY time
MEASURES
MATCH_NUMBER() AS match,
RUNNING RPR_LAST(totalprice) AS price,
CLASSIFIER() AS label
ALL ROWS PER MATCH
AFTER MATCH SKIP PAST LAST ROW
PATTERN %s -- PATTERN 子句
DEFINE A AS true
) AS m;Results
- When the PATTERN clause is specified as PATTERN (^A)
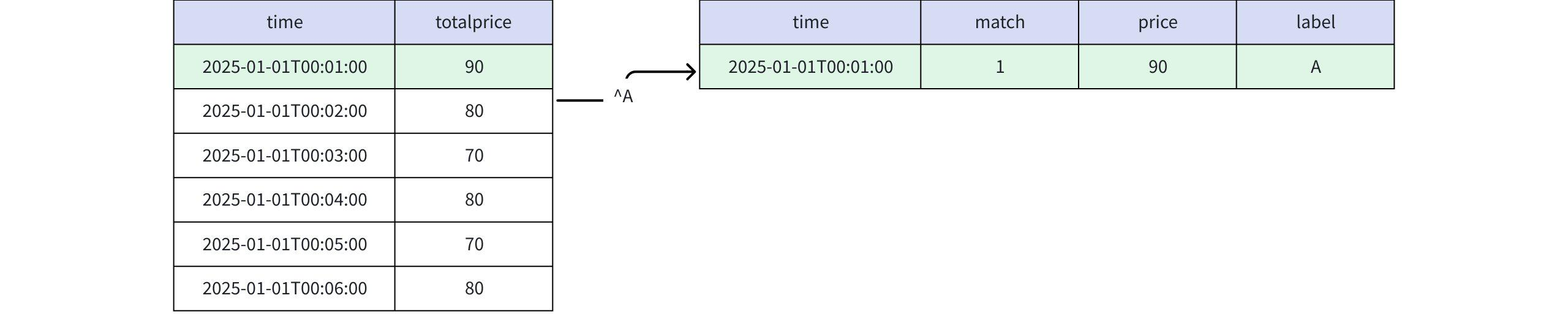
Actual Return
+-----------------------------+-----+-----+-----+ | time|match|price|label| +-----------------------------+-----+-----+-----+ |2025-01-01T00:01:00.000+08:00| 1| 90| A| +-----------------------------+-----+-----+-----+ Total line number = 1- When the PATTERN clause is specified as PATTERN (^A^), the output result is empty. This is because it is impossible to match an A starting from the beginning of a partition and then return to the beginning of the partition again.
+----+-----+-----+-----+ |time|match|price|label| +----+-----+-----+-----+ +----+-----+-----+-----+ Empty set.- When the PATTERN clause is specified as PATTERN (A$)
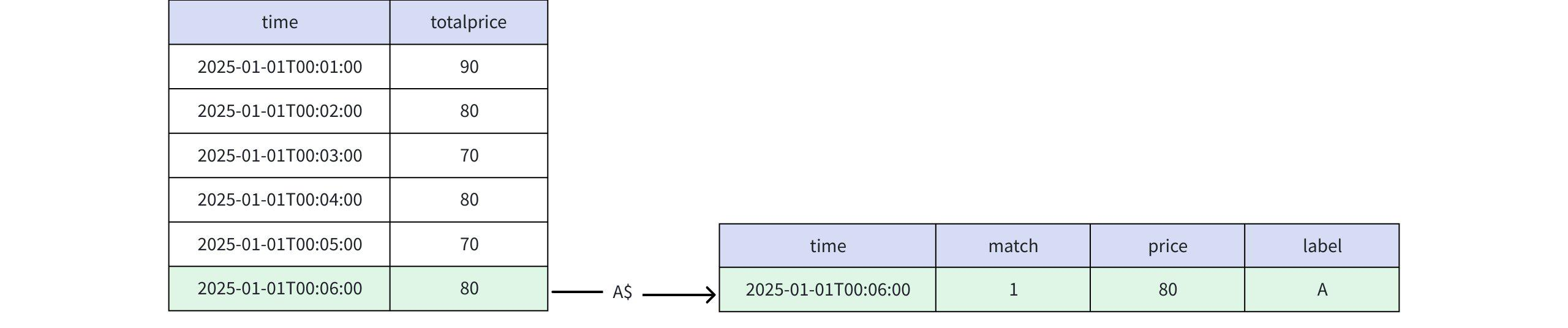
Actual Return
+-----------------------------+-----+-----+-----+ | time|match|price|label| +-----------------------------+-----+-----+-----+ |2025-01-01T00:06:00.000+08:00| 1| 80| A| +-----------------------------+-----+-----+-----+ Total line number = 1- When the PATTERN clause is specified as PATTERN ($A$), the output result is empty.
+----+-----+-----+-----+ |time|match|price|label| +----+-----+-----+-----+ +----+-----+-----+-----+ Empty set.
1.2.4.3 Quantifiers
Quantifiers are used to specify the number of times a subpattern repeats, placed after the corresponding subpattern (e.g., (A | B)*).
Common quantifiers are as follows:
| Quantifier | Description |
|---|---|
* | Zero or more repetitions |
+ | One or more repetitions |
? | Zero or one repetition |
{n} | Exactly n repetitions |
{m, n} | Repetitions between m and n times (m and n are non-negative integers). * If the left bound is omitted, the default starts from 0; * If the right bound is omitted, there is no upper limit on the number of repetitions (e.g., {5,} is equivalent to "at least five times"); * If both left and right bounds are omitted (i.e., {,}), it is equivalent to *. |
- The matching preference can be changed by adding
?after the quantifier.{3,5}: Prefers 5 times, least prefers 3 times;{3,5}?: Prefers 3 times, least prefers 5 times.?: Prefers 1 time;??: Prefers 0 times.
1.2.5 AFTER MATCH SKIP Clause
Used to specify which row to start the next pattern match from after identifying a non-empty match.
| Jump Strategy | Description | Allows Overlapping Matches? |
|---|---|---|
AFTER MATCH SKIP PAST LAST ROW | Default behavior. Starts from the row after the last row of the current match. | No |
AFTER MATCH SKIP TO NEXT ROW | Starts from the second row in the current match. | Yes |
AFTER MATCH SKIP TO [ FIRST | LAST ] pattern_variable | Jumps to start from the [ first row | last row ] of a pattern variable. | Yes |
- Among all possible configurations, only when
ALL ROWS PER MATCH WITH UNMATCHED ROWSis used in combination withAFTER MATCH SKIP PAST LAST ROWcan the system ensure that exactly one output record is generated for each input row.
Examples
- Query sql
SELECT m.time, m.match, m.price, m.label
FROM t
MATCH_RECOGNIZE (
ORDER BY time
MEASURES
MATCH_NUMBER() AS match,
RUNNING RPR_LAST(totalprice) AS price,
CLASSIFIER() AS label
ALL ROWS PER MATCH
%s -- AFTER MATCH SKIP 子句
PATTERN (A B+ C+ D?)
SUBSET U = (C, D)
DEFINE
B AS B.totalprice < PREV (B.totalprice),
C AS C.totalprice > PREV (C.totalprice),
D AS false -- 永远不会匹配成功
) AS m;Results
- When AFTER MATCH SKIP PAST LAST ROW is specified
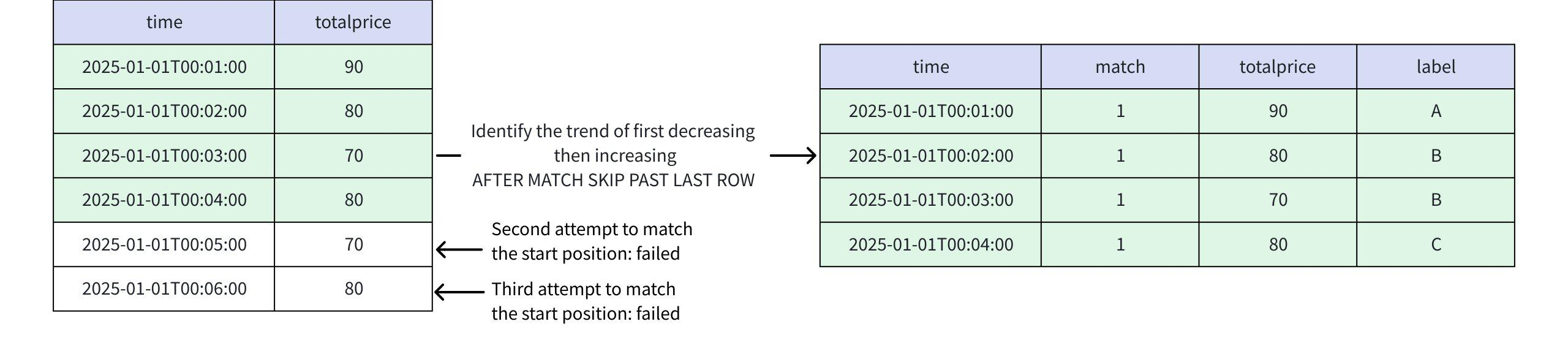
- First match: Rows 1, 2, 3, 4
- Second match: According to the semantics of
AFTER MATCH SKIP PAST LAST ROW, starting from row 5, no valid match can be found - This pattern will never have overlapping matches
+-----------------------------+-----+-----+-----+ | time|match|price|label| +-----------------------------+-----+-----+-----+ |2025-01-01T00:01:00.000+08:00| 1| 90| A| |2025-01-01T00:02:00.000+08:00| 1| 80| B| |2025-01-01T00:03:00.000+08:00| 1| 70| B| |2025-01-01T00:04:00.000+08:00| 1| 80| C| +-----------------------------+-----+-----+-----+ Total line number = 4- When AFTER MATCH SKIP TO NEXT ROW
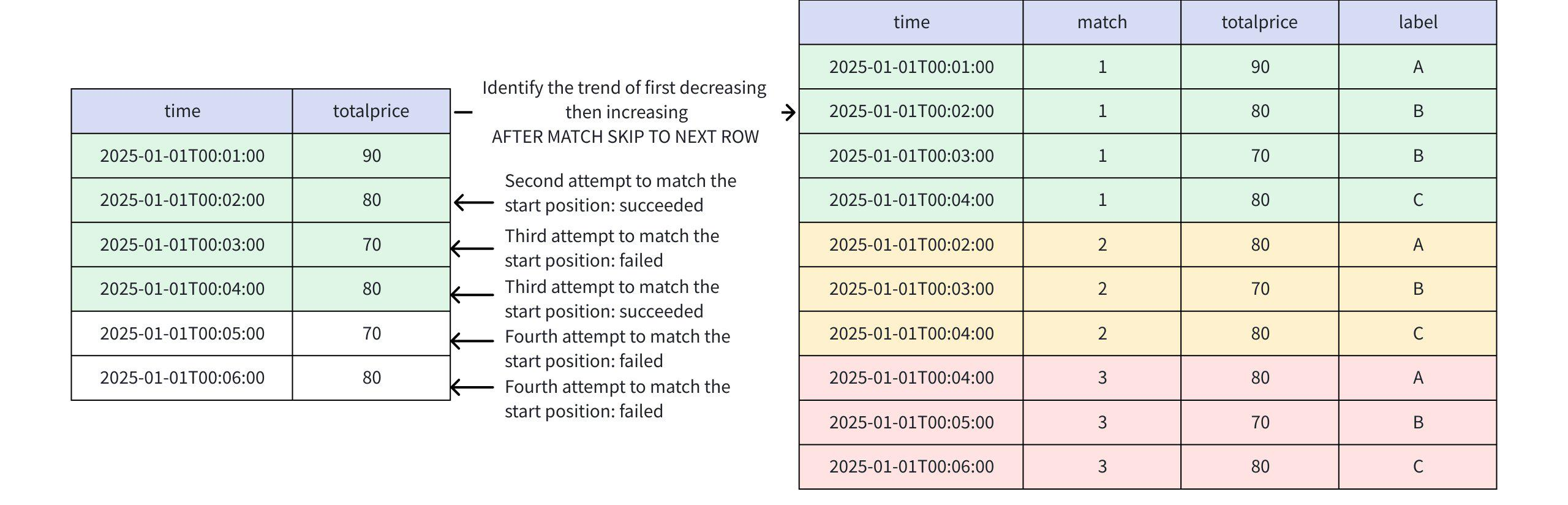
- First match: Rows 1, 2, 3, 4
- Second match: According to the semantics of
AFTER MATCH SKIP TO NEXT ROW, starting from row 2, matches: Rows 2, 3, 4 - Third match: Attempts to start from row 3, fails
- Fourth match: Attempts to start from row 4, succeeds, matches rows 4, 5, 6
- This pattern allows overlapping matches
+-----------------------------+-----+-----+-----+ | time|match|price|label| +-----------------------------+-----+-----+-----+ |2025-01-01T00:01:00.000+08:00| 1| 90| A| |2025-01-01T00:02:00.000+08:00| 1| 80| B| |2025-01-01T00:03:00.000+08:00| 1| 70| B| |2025-01-01T00:04:00.000+08:00| 1| 80| C| |2025-01-01T00:02:00.000+08:00| 2| 80| A| |2025-01-01T00:03:00.000+08:00| 2| 70| B| |2025-01-01T00:04:00.000+08:00| 2| 80| C| |2025-01-01T00:04:00.000+08:00| 3| 80| A| |2025-01-01T00:05:00.000+08:00| 3| 70| B| |2025-01-01T00:06:00.000+08:00| 3| 80| C| +-----------------------------+-----+-----+-----+ Total line number = 10- When AFTER MATCH SKIP TO FIRST C
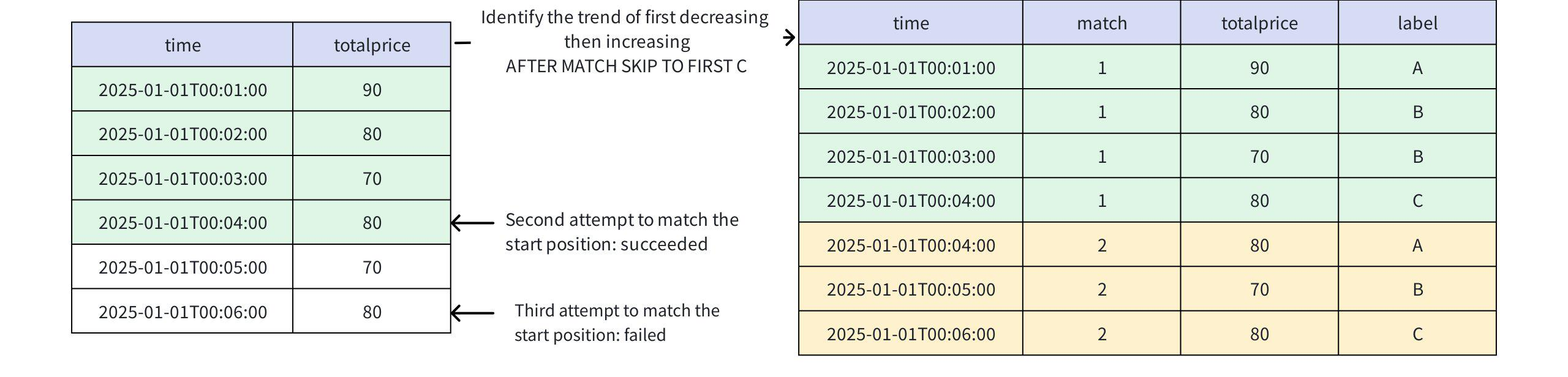
- First match: Rows 1, 2, 3, 4
- Second match: Starts from the first C (i.e., row 4), matches rows 4, 5, 6
- This pattern allows overlapping matches
+-----------------------------+-----+-----+-----+ | time|match|price|label| +-----------------------------+-----+-----+-----+ |2025-01-01T00:01:00.000+08:00| 1| 90| A| |2025-01-01T00:02:00.000+08:00| 1| 80| B| |2025-01-01T00:03:00.000+08:00| 1| 70| B| |2025-01-01T00:04:00.000+08:00| 1| 80| C| |2025-01-01T00:04:00.000+08:00| 2| 80| A| |2025-01-01T00:05:00.000+08:00| 2| 70| B| |2025-01-01T00:06:00.000+08:00| 2| 80| C| +-----------------------------+-----+-----+-----+ Total line number = 7- When AFTER MATCH SKIP TO LAST B or AFTER MATCH SKIP TO B
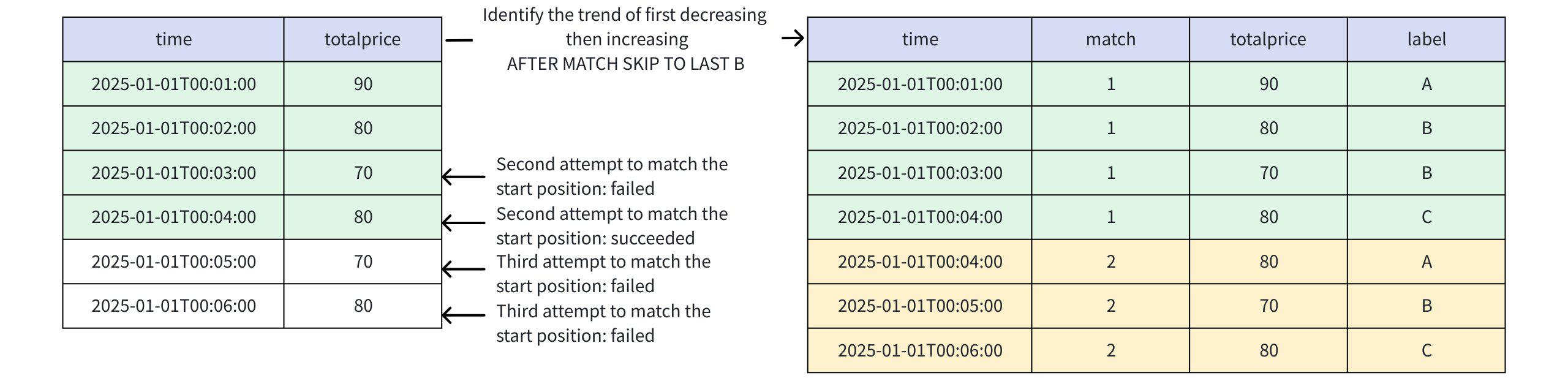
- First match: Rows 1, 2, 3, 4
- Second match: Attempts to start from the last B (i.e., row 3), fails
- Third match: Attempts to start from row 4, successfully matches rows 4, 5, 6
- This pattern allows overlapping matches
+-----------------------------+-----+-----+-----+ | time|match|price|label| +-----------------------------+-----+-----+-----+ |2025-01-01T00:01:00.000+08:00| 1| 90| A| |2025-01-01T00:02:00.000+08:00| 1| 80| B| |2025-01-01T00:03:00.000+08:00| 1| 70| B| |2025-01-01T00:04:00.000+08:00| 1| 80| C| |2025-01-01T00:04:00.000+08:00| 2| 80| A| |2025-01-01T00:05:00.000+08:00| 2| 70| B| |2025-01-01T00:06:00.000+08:00| 2| 80| C| +-----------------------------+-----+-----+-----+ Total line number = 7- When AFTER MATCH SKIP TO U
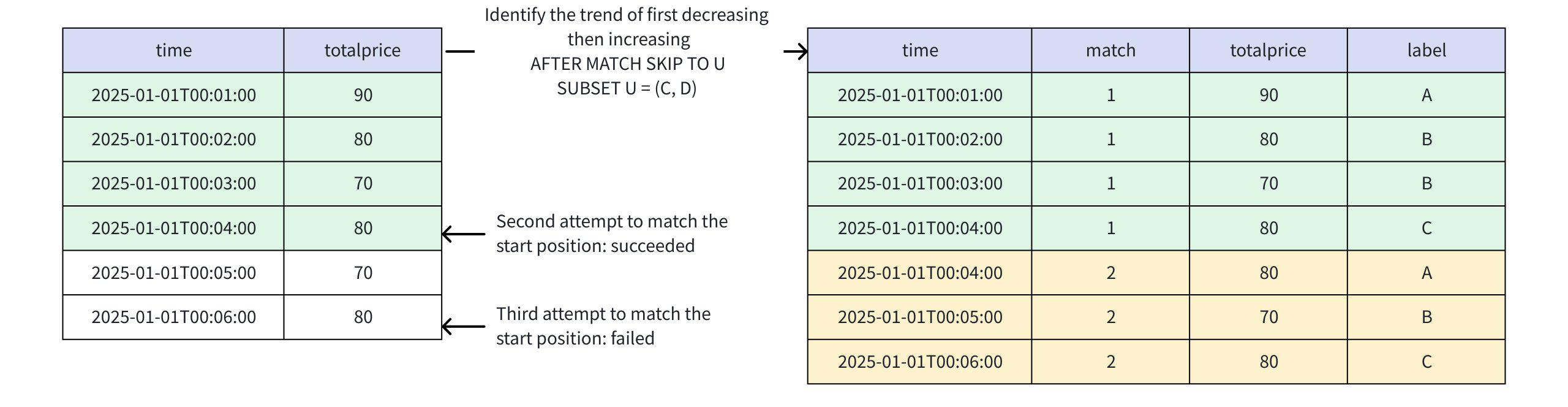
- First match: Rows 1, 2, 3, 4
- Second match:
SKIP TO Umeans jumping to the last C or D; D can never match successfully, so it jumps to the last C (i.e., row 4), successfully matching rows 4, 5, 6 - This pattern allows overlapping matches
+-----------------------------+-----+-----+-----+ | time|match|price|label| +-----------------------------+-----+-----+-----+ |2025-01-01T00:01:00.000+08:00| 1| 90| A| |2025-01-01T00:02:00.000+08:00| 1| 80| B| |2025-01-01T00:03:00.000+08:00| 1| 70| B| |2025-01-01T00:04:00.000+08:00| 1| 80| C| |2025-01-01T00:04:00.000+08:00| 2| 80| A| |2025-01-01T00:05:00.000+08:00| 2| 70| B| |2025-01-01T00:06:00.000+08:00| 2| 80| C| +-----------------------------+-----+-----+-----+ Total line number = 7- When AFTER MATCH SKIP TO A, you cannot jump to the first row of the match, otherwise it will cause an infinite loop
Msg: org.apache.iotdb.jdbc.IoTDBSQLException: 701: AFTER MATCH SKIP TO failed: cannot skip to first row of match- When AFTER MATCH SKIP TO B, you cannot jump to a pattern variable that does not exist in the match group
Msg: org.apache.iotdb.jdbc.IoTDBSQLException: 701: AFTER MATCH SKIP TO failed: pattern variable is not present in match
1.2.6 ROWS PER MATCH Clause
Used to specify the output method of the result set after a successful pattern match, including the following two main options:
| Output Method | Rule Description | Output Result | Handling Logic for Empty Matches/Unmatched Rows |
|---|---|---|---|
| ONE ROW PER MATCH | Generates one output row for each successful match. | * Columns in the PARTITION BY clause* Expressions defined in the MEASURES clause. | Outputs empty matches; skips unmatched rows. |
| ALL ROWS PER MATCH | Each row in a match generates an output record, unless the row is excluded via exclusion syntax. | * Columns in the PARTITION BY clause* Columns in the ORDER BY clause* Expressions defined in the MEASURES clause* Remaining columns in the input table | * Default: Outputs empty matches; skips unmatched rows.* ALL ROWS PER MATCHSHOW EMPTY MATCHES: Outputs empty matches by default; skips unmatched rows.* ALL ROWS PER MATCHOMIT EMPTY MATCHES: Does not output empty matches; skips unmatched rows.* ALL ROWS PER MATCHWITH UNMATCHED ROWS: Outputs empty matches and generates an additional output record for each unmatched row. |
1.2.7 MEASURES Clause
Used to specify which information to extract from a matched set of data. This clause is optional; if not explicitly specified, some input columns will become the output results of pattern recognition based on the settings of the ROWS PER MATCH clause.
SQL
MEASURES measure_expression AS measure_name [, ...]- A
measure_expressionis a scalar value calculated from the matched set of data.
| Usage Example | Description |
|---|---|
A.totalprice AS starting_price | Returns the price from the first row in the matched group (i.e., the only row associated with variable A) as the starting price. |
RPR_LAST(B.totalprice) AS bottom_price | Returns the price from the last row associated with variable B, representing the lowest price in the "V" shape pattern (corresponding to the end of the downward segment). |
RPR_LAST(U.totalprice) AS top_price | Returns the highest price in the matched group, corresponding to the last row associated with variable C or D (i.e., the end of the entire matched group). [Assuming SUBSET U = (C, D)] |
- Each
measure_expressiondefines an output column, which can be referenced by its specifiedmeasure_name.
1.2.8 Row Pattern Recognition Expressions
Expressions used in the MEASURES and DEFINE clauses are scalar expressions, evaluated in the row-level context of the input table. In addition to supporting standard SQL syntax, scalar expressions also support special extended functions for row pattern recognition.
1.2.8.1 Pattern Variable References
A.totalprice
U.orderdate
orderstatus- When a column name is prefixed with a basic pattern variable or a combined pattern variable, it refers to the corresponding column values of all rows matched by that variable.
- If a column name has no prefix, it is equivalent to using the "global combined pattern variable" (i.e., the union of all basic pattern variables) as the prefix, referring to the column values of all rows in the current match.
Using table names as column name prefixes in pattern recognition expressions is not allowed.
1.2.8.2 Extended Functions
| Function Name | Function Syntax | Description |
|---|---|---|
MATCH_NUMBER Function | MATCH_NUMBER() | Returns the sequence number of the current match within the partition, starting from 1. Empty matches occupy match sequence numbers just like non-empty matches. |
CLASSIFIER Function | CLASSIFIER(option) | 1. Returns the name of the basic pattern variable mapped by the current row. 2. option is an optional parameter: a basic pattern variable CLASSIFIER(A) or a combined pattern variable CLASSIFIER(U) can be passed in to limit the function's scope; for rows outside the scope, NULL is returned directly. When used with a combined pattern variable, it can be used to distinguish which basic pattern variable in the union the row is mapped to. |
| Logical Navigation Functions | RPR_FIRST(expr, k) | 1. Indicates locating the first row satisfying expr in the current match group, then searching for the k-th occurrence of the row corresponding to the same pattern variable towards the end of the group, and returning the specified column value of that row. If the k-th matching row is not found in the specified direction, the function returns NULL. 2. k is an optional parameter, defaulting to 0 (only locating the first row satisfying the condition); if explicitly specified, it must be a non-negative integer. |
| Logical Navigation Functions | RPR_LAST(expr, k) | 1. Indicates locating the last row satisfying expr in the current match group, then searching for the k-th occurrence of the row corresponding to the same pattern variable towards the start of the group, and returning the specified column value of that row. If the k-th matching row is not found in the specified direction, the function returns NULL. 2. k is an optional parameter, defaulting to 0 (only locating the last row satisfying the condition); if explicitly specified, it must be a non-negative integer. |
| Physical Navigation Functions | PREV(expr, k) | 1. Indicates offsetting k rows towards the start from the last row matched to the given pattern variable, and returning the corresponding column value. If navigation exceeds the partition boundary, the function returns NULL. 2. k is an optional parameter, defaulting to 1; if explicitly specified, it must be a non-negative integer. |
| Physical Navigation Functions | NEXT(expr, k) | 1. Indicates offsetting k rows towards the end from the last row matched to the given pattern variable, and returning the corresponding column value. If navigation exceeds the partition boundary, the function returns NULL. 2. k is an optional parameter, defaulting to 1; if explicitly specified, it must be a non-negative integer. |
| Aggregate Functions | COUNT, SUM, AVG, MAX, MIN Functions | Can be used to calculate data in the current match. Aggregate functions and navigation functions are not allowed to be nested within each other. (Supported from version V2.0.6) |
| Nested Functions | PREV/NEXT(CLASSIFIER()) | Nesting of physical navigation functions and the CLASSIFIER function. Used to obtain the pattern variables corresponding to the previous and next matching rows of the current row. |
| Nested Functions | PREV/NEXT(RPR_FIRST/RPR_LAST(expr, k)) | Logical functions are allowed to be nested inside physical functions; physical functions are not allowed to be nested inside logical functions. Used to perform logical offset first, then physical offset. |
Examples
- CLASSIFIER Function
- Query sql
SELECT m.time, m.match, m.price, m.lower_or_higher, m.label
FROM t
MATCH_RECOGNIZE (
ORDER BY time
MEASURES
MATCH_NUMBER() AS match,
RUNNING RPR_LAST(totalprice) AS price,
CLASSIFIER(U) AS lower_or_higher,
CLASSIFIER(W) AS label
ALL ROWS PER MATCH
PATTERN ((L | H) A)
SUBSET
U = (L, H),
W = (A, L, H)
DEFINE
A AS A.totalprice = 80,
L AS L.totalprice < 80,
H AS H.totalprice > 80
) AS m;Analysis
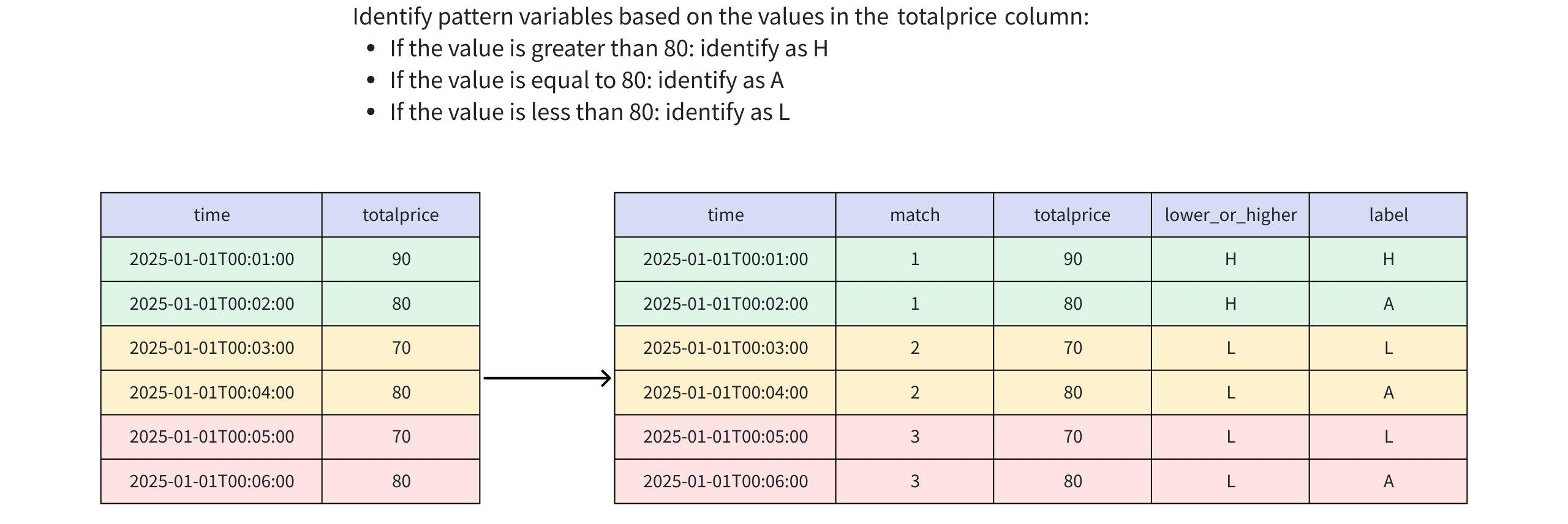
Result
+-----------------------------+-----+-----+---------------+-----+
| time|match|price|lower_or_higher|label|
+-----------------------------+-----+-----+---------------+-----+
|2025-01-01T00:01:00.000+08:00| 1| 90| H| H|
|2025-01-01T00:02:00.000+08:00| 1| 80| H| A|
|2025-01-01T00:03:00.000+08:00| 2| 70| L| L|
|2025-01-01T00:04:00.000+08:00| 2| 80| L| A|
|2025-01-01T00:05:00.000+08:00| 3| 70| L| L|
|2025-01-01T00:06:00.000+08:00| 3| 80| L| A|
+-----------------------------+-----+-----+---------------+-----+
Total line number = 6- Logical Navigation Functions
- Query sql
SELECT m.time, m.measure
FROM t
MATCH_RECOGNIZE (
ORDER BY time
MEASURES
%s AS measure -- MEASURES 子句
ALL ROWS PER MATCH
PATTERN (A+)
DEFINE A AS true
) AS m;Results
- When the value is totalprice, RPR_LAST(totalprice), RUNNING RPR_LAST(totalprice)
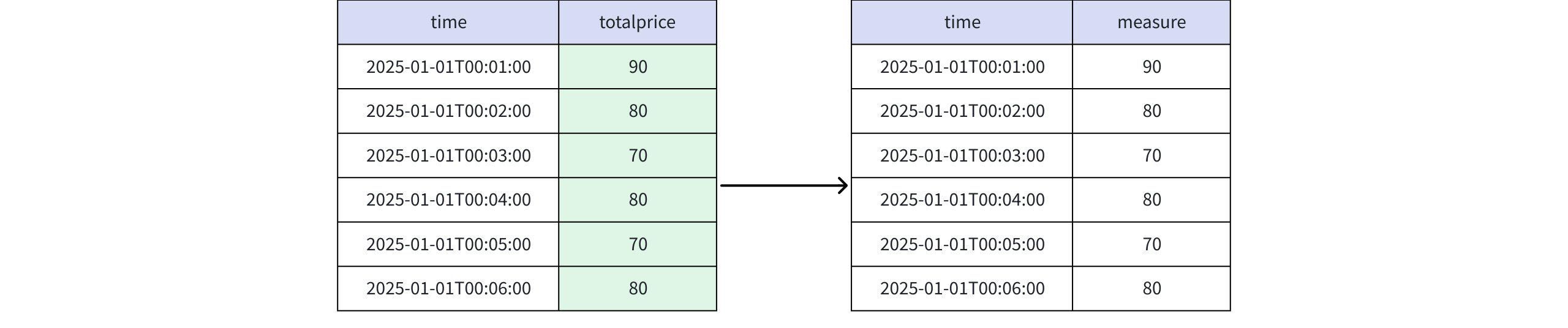
Actual Return
+-----------------------------+-------+ | time|measure| +-----------------------------+-------+ |2025-01-01T00:01:00.000+08:00| 90| |2025-01-01T00:02:00.000+08:00| 80| |2025-01-01T00:03:00.000+08:00| 70| |2025-01-01T00:04:00.000+08:00| 80| |2025-01-01T00:05:00.000+08:00| 70| |2025-01-01T00:06:00.000+08:00| 80| +-----------------------------+-------+ Total line number = 6- When the value is FINAL RPR_LAST(totalprice)
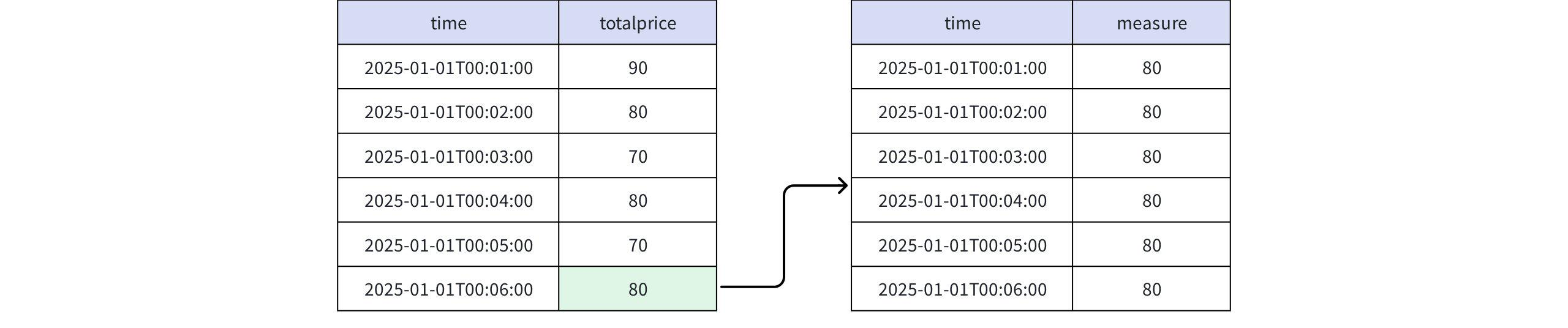
Actual Return
+-----------------------------+-------+ | time|measure| +-----------------------------+-------+ |2025-01-01T00:01:00.000+08:00| 80| |2025-01-01T00:02:00.000+08:00| 80| |2025-01-01T00:03:00.000+08:00| 80| |2025-01-01T00:04:00.000+08:00| 80| |2025-01-01T00:05:00.000+08:00| 80| |2025-01-01T00:06:00.000+08:00| 80| +-----------------------------+-------+ Total line number = 6- When the value is RPR_FIRST(totalprice), RUNNING RPR_FIRST(totalprice), FINAL RPR_FIRST(totalprice)
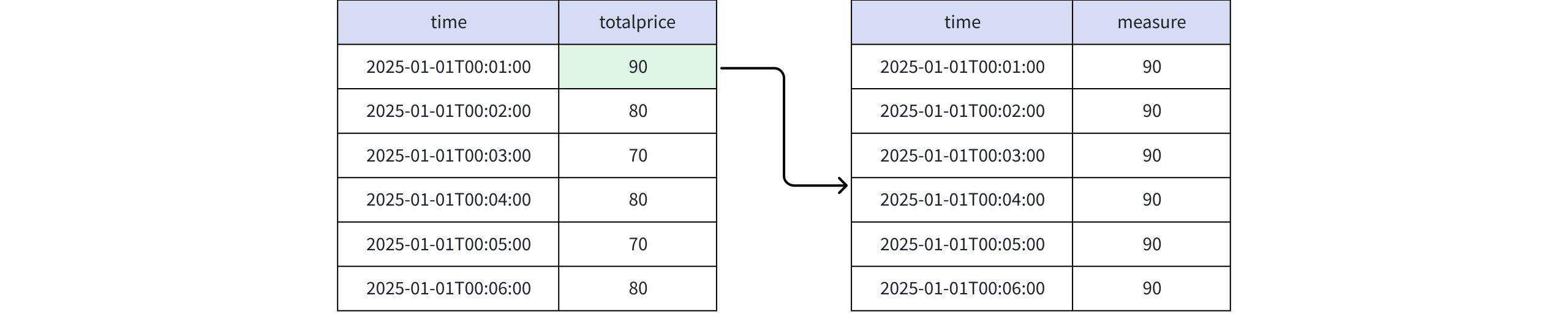
Actual Return
+-----------------------------+-------+ | time|measure| +-----------------------------+-------+ |2025-01-01T00:01:00.000+08:00| 90| |2025-01-01T00:02:00.000+08:00| 90| |2025-01-01T00:03:00.000+08:00| 90| |2025-01-01T00:04:00.000+08:00| 90| |2025-01-01T00:05:00.000+08:00| 90| |2025-01-01T00:06:00.000+08:00| 90| +-----------------------------+-------+ Total line number = 6- When the value is RPR_LAST(totalprice, 2)
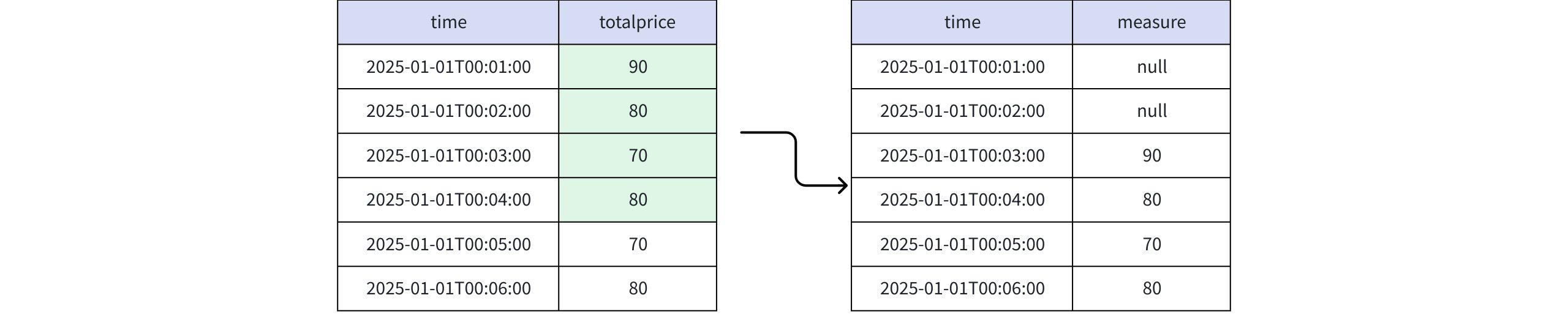
Actual Return
+-----------------------------+-------+ | time|measure| +-----------------------------+-------+ |2025-01-01T00:01:00.000+08:00| null| |2025-01-01T00:02:00.000+08:00| null| |2025-01-01T00:03:00.000+08:00| 90| |2025-01-01T00:04:00.000+08:00| 80| |2025-01-01T00:05:00.000+08:00| 70| |2025-01-01T00:06:00.000+08:00| 80| +-----------------------------+-------+ Total line number = 6- When the value is FINAL RPP_LAST(totalprice, 2)
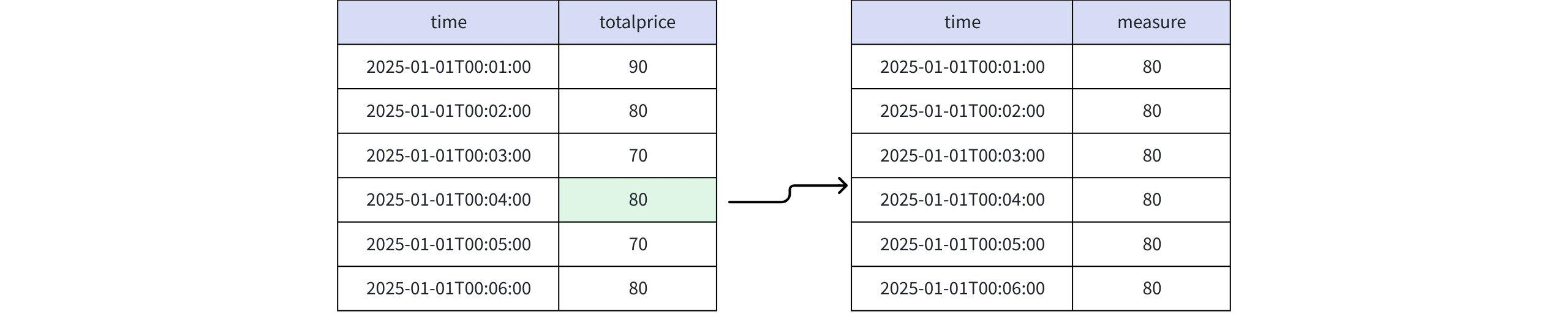
Actual Return
+-----------------------------+-------+ | time|measure| +-----------------------------+-------+ |2025-01-01T00:01:00.000+08:00| 80| |2025-01-01T00:02:00.000+08:00| 80| |2025-01-01T00:03:00.000+08:00| 80| |2025-01-01T00:04:00.000+08:00| 80| |2025-01-01T00:05:00.000+08:00| 80| |2025-01-01T00:06:00.000+08:00| 80| +-----------------------------+-------+ Total line number = 6- When the value is RPR_FIRST(totalprice, 2) and FINAL RPR_FIRST(totalprice, 2)
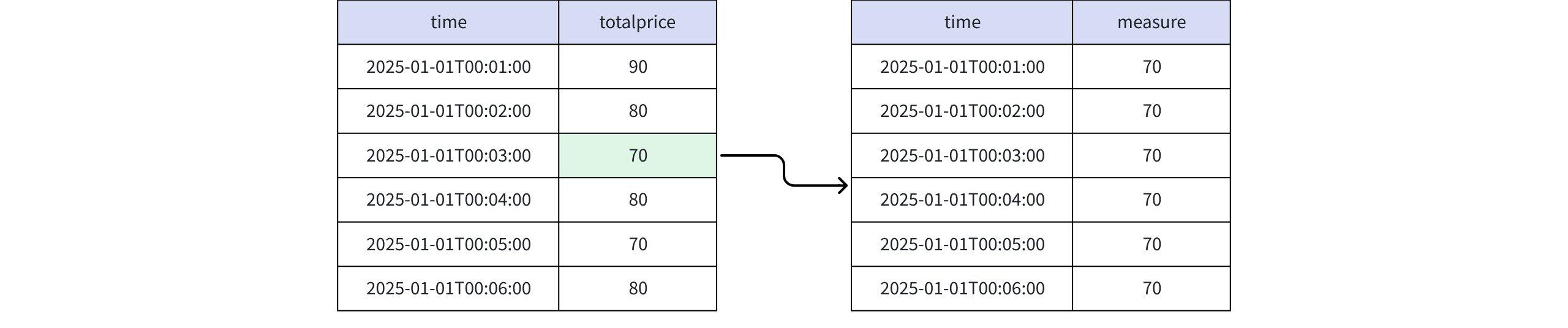
Actual Return
+-----------------------------+-------+ | time|measure| +-----------------------------+-------+ |2025-01-01T00:01:00.000+08:00| 70| |2025-01-01T00:02:00.000+08:00| 70| |2025-01-01T00:03:00.000+08:00| 70| |2025-01-01T00:04:00.000+08:00| 70| |2025-01-01T00:05:00.000+08:00| 70| |2025-01-01T00:06:00.000+08:00| 70| +-----------------------------+-------+ Total line number = 6
- Physical Navigation Functions
- Query sql
SELECT m.time, m.measure
FROM t
MATCH_RECOGNIZE (
ORDER BY time
MEASURES
%s AS measure -- MEASURES 子句
ALL ROWS PER MATCH
PATTERN (B)
DEFINE B AS B.totalprice >= PREV(B.totalprice)
) AS m;Results
- When the value is
PREV(totalprice)
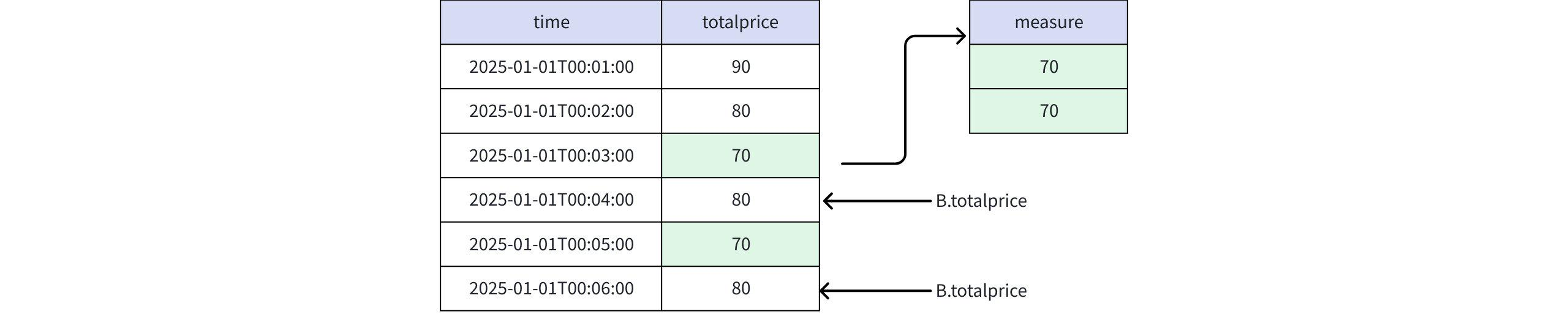
Actual Return
+-----------------------------+-------+ | time|measure| +-----------------------------+-------+ |2025-01-01T00:04:00.000+08:00| 70| |2025-01-01T00:06:00.000+08:00| 70| +-----------------------------+-------+ Total line number = 2- When the value is
PREV(B.totalprice, 2)
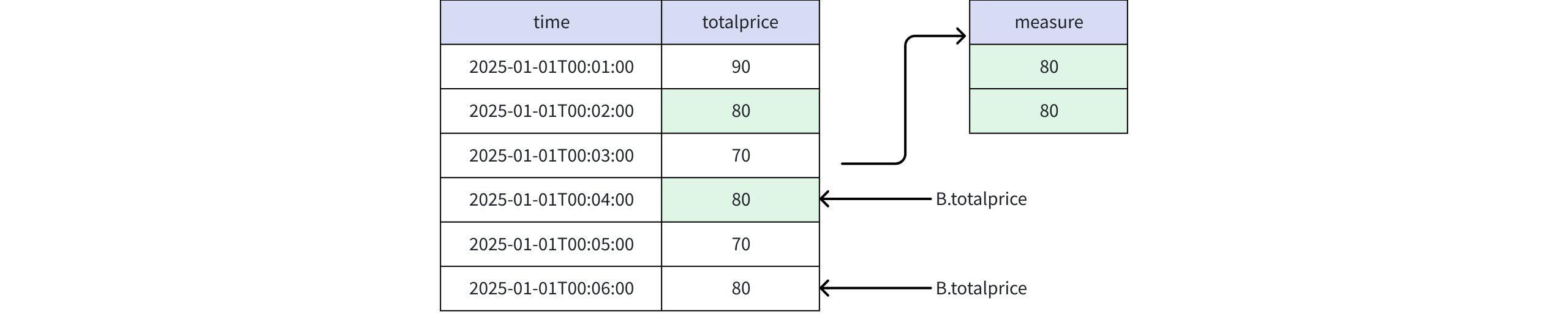
Actual Return
+-----------------------------+-------+ | time|measure| +-----------------------------+-------+ |2025-01-01T00:04:00.000+08:00| 80| |2025-01-01T00:06:00.000+08:00| 80| +-----------------------------+-------+ Total line number = 2- When the value is
PREV(B.totalprice, 4)
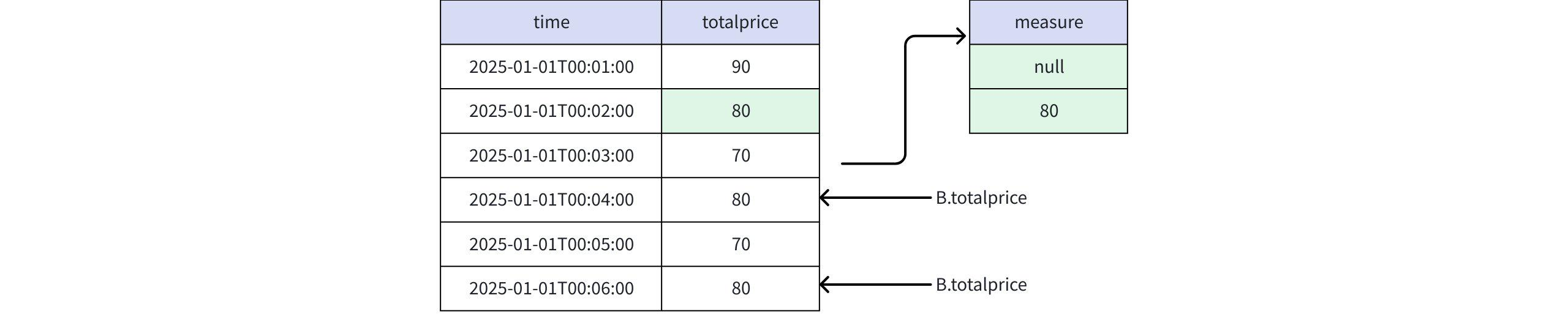
Actual Return
+-----------------------------+-------+ | time|measure| +-----------------------------+-------+ |2025-01-01T00:04:00.000+08:00| null| |2025-01-01T00:06:00.000+08:00| 80| +-----------------------------+-------+ Total line number = 2- When the value is
NEXT(totalprice)orNEXT(B.totalprice, 1)

Actual Return
+-----------------------------+-------+ | time|measure| +-----------------------------+-------+ |2025-01-01T00:04:00.000+08:00| 70| |2025-01-01T00:06:00.000+08:00| null| +-----------------------------+-------+ Total line number = 2When the value isNEXT(B.totalprice, 2)`

Actual Return
+-----------------------------+-------+ | time|measure| +-----------------------------+-------+ |2025-01-01T00:04:00.000+08:00| 80| |2025-01-01T00:06:00.000+08:00| null| +-----------------------------+-------+ Total line number = 2- When the value is
- Aggregate Functions
- Query sql
SELECT m.time, m.count, m.avg, m.sum, m.min, m.max
FROM t
MATCH_RECOGNIZE (
ORDER BY time
MEASURES
COUNT(*) AS count,
AVG(totalprice) AS avg,
SUM(totalprice) AS sum,
MIN(totalprice) AS min,
MAX(totalprice) AS max
ALL ROWS PER MATCH
PATTERN (A+)
DEFINE A AS true
) AS m;- Analysis (Taking MIN(totalprice) as an Example)
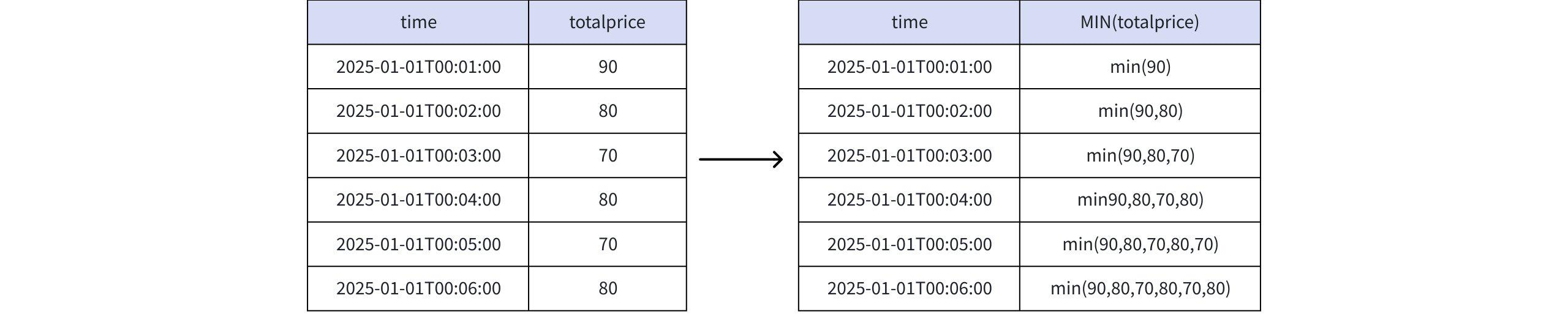
- Result
+-----------------------------+-----+-----------------+-----+---+---+
| time|count| avg| sum|min|max|
+-----------------------------+-----+-----------------+-----+---+---+
|2025-01-01T00:01:00.000+08:00| 1| 90.0| 90.0| 90| 90|
|2025-01-01T00:02:00.000+08:00| 2| 85.0|170.0| 80| 90|
|2025-01-01T00:03:00.000+08:00| 3| 80.0|240.0| 70| 90|
|2025-01-01T00:04:00.000+08:00| 4| 80.0|320.0| 70| 90|
|2025-01-01T00:05:00.000+08:00| 5| 78.0|390.0| 70| 90|
|2025-01-01T00:06:00.000+08:00| 6|78.33333333333333|470.0| 70| 90|
+-----------------------------+-----+-----------------+-----+---+---+
Total line number = 6- Nested Functions
Example 1
- Query sql
SELECT m.time, m.match, m.price, m.lower_or_higher, m.label, m.prev_label, m.next_label
FROM t
MATCH_RECOGNIZE (
ORDER BY time
MEASURES
MATCH_NUMBER() AS match,
RUNNING RPR_LAST(totalprice) AS price,
CLASSIFIER(U) AS lower_or_higher,
CLASSIFIER(W) AS label,
PREV(CLASSIFIER(W)) AS prev_label,
NEXT(CLASSIFIER(W)) AS next_label
ALL ROWS PER MATCH
PATTERN ((L | H) A)
SUBSET
U = (L, H),
W = (A, L, H)
DEFINE
A AS A.totalprice = 80,
L AS L.totalprice < 80,
H AS H.totalprice > 80
) AS m;- Analysis
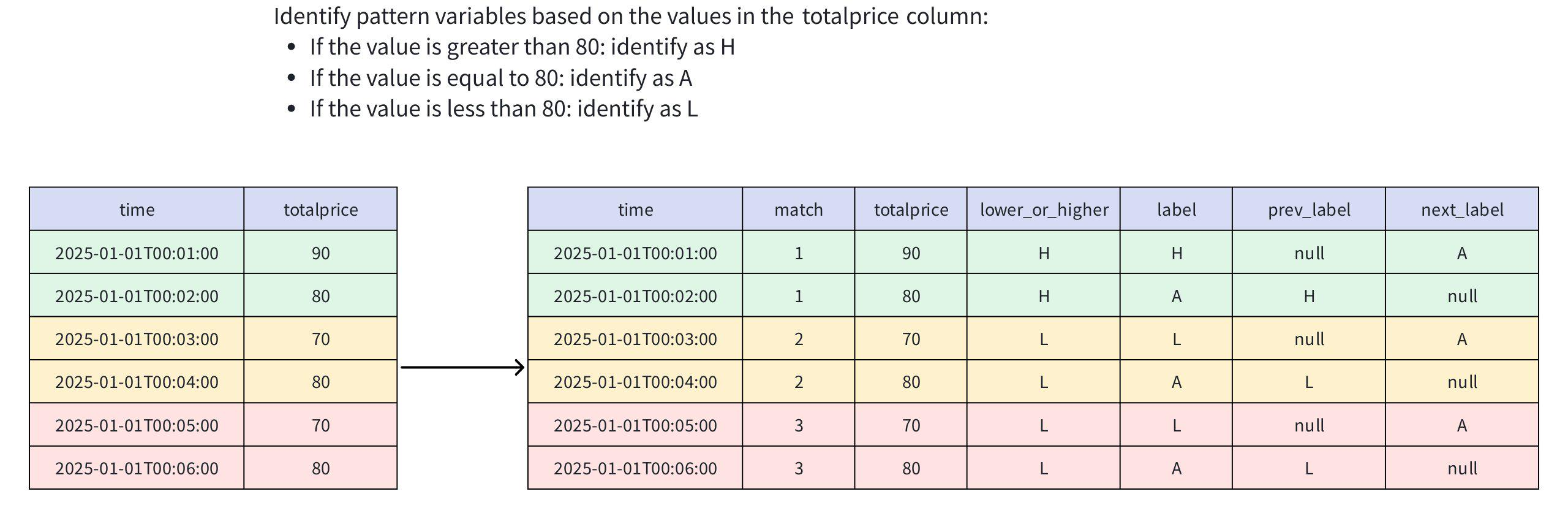
- Result
+-----------------------------+-----+-----+---------------+-----+----------+----------+
| time|match|price|lower_or_higher|label|prev_label|next_label|
+-----------------------------+-----+-----+---------------+-----+----------+----------+
|2025-01-01T00:01:00.000+08:00| 1| 90| H| H| null| A|
|2025-01-01T00:02:00.000+08:00| 1| 80| H| A| H| null|
|2025-01-01T00:03:00.000+08:00| 2| 70| L| L| null| A|
|2025-01-01T00:04:00.000+08:00| 2| 80| L| A| L| null|
|2025-01-01T00:05:00.000+08:00| 3| 70| L| L| null| A|
|2025-01-01T00:06:00.000+08:00| 3| 80| L| A| L| null|
+-----------------------------+-----+-----+---------------+-----+----------+----------+
Total line number = 6Example 2
- Query sql
SELECT m.time, m.prev_last_price, m.next_first_price
FROM t
MATCH_RECOGNIZE (
ORDER BY time
MEASURES
PREV(RPR_LAST(totalprice), 2) AS prev_last_price,
NEXT(RPR_FIRST(totalprice), 2) as next_first_price
ALL ROWS PER MATCH
PATTERN (A+)
DEFINE A AS true
) AS m;- Analysis
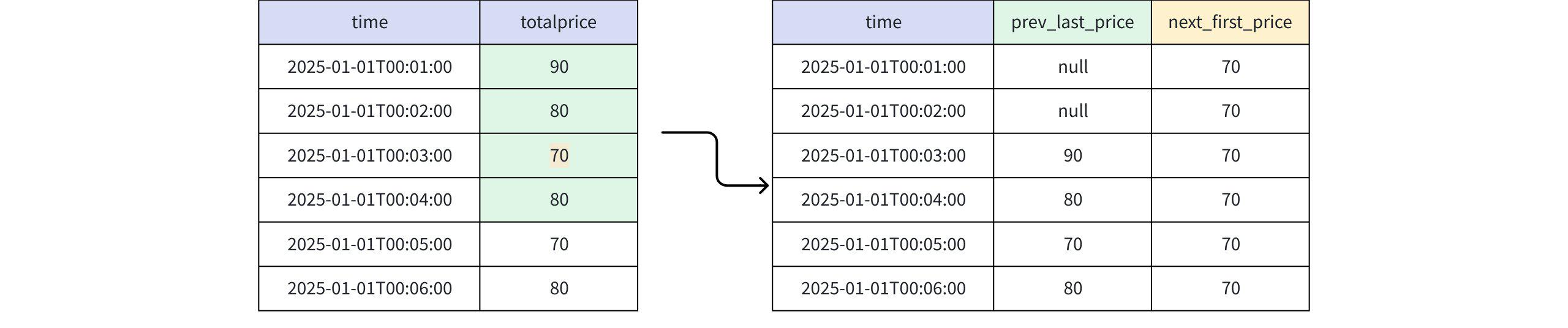
- Result
+-----------------------------+---------------+----------------+
| time|prev_last_price|next_first_price|
+-----------------------------+---------------+----------------+
|2025-01-01T00:01:00.000+08:00| null| 70|
|2025-01-01T00:02:00.000+08:00| null| 70|
|2025-01-01T00:03:00.000+08:00| 90| 70|
|2025-01-01T00:04:00.000+08:00| 80| 70|
|2025-01-01T00:05:00.000+08:00| 70| 70|
|2025-01-01T00:06:00.000+08:00| 80| 70|
+-----------------------------+---------------+----------------+
Total line number = 61.2.8.3 RUNNING and FINAL Semantics
- Definition
RUNNING: Indicates the calculation scope is from the start row of the current match group to the row currently being processed (i.e., up to the current row).FINAL: Indicates the calculation scope is from the start row of the current match group to the final row of the group (i.e., the entire match group).
- Scope of Application
- The DEFINE clause uses RUNNING semantics by default.
- The MEASURES clause uses RUNNING semantics by default and supports specifying FINAL semantics. When using the ONE ROW PER MATCH output mode, all expressions are calculated from the last row position of the match group, and at this time, RUNNING semantics are equivalent to FINAL semantics.
- Syntax Constraints
- RUNNING and FINAL need to be written before logical navigation functions or aggregate functions, and cannot directly act on column references.
- Valid:
RUNNING RPP_LAST(A.totalprice),FINAL RPP_LAST(A.totalprice) - Invalid:
RUNNING A.totalprice,FINAL A.totalprice,RUNNING PREV(A.totalprice)
- Valid:
1.3 Scenario Examples
Using Sample Data as the source data
1.3.1 Time Segment Query
Segment the data in table1 by time intervals less than or equal to 24 hours, and query the total number of data entries in each segment, as well as the start and end times.
Query SQL
SELECT start_time, end_time, cnt
FROM table1
MATCH_RECOGNIZE (
ORDER BY time
MEASURES
RPR_FIRST(A.time) AS start_time,
RPR_LAST(time) AS end_time,
COUNT() AS cnt
PATTERN (A B*)
DEFINE B AS (cast(B.time as INT64) - cast(PREV(B.time) as INT64)) <= 86400000
) AS mResults
+-----------------------------+-----------------------------+---+
| start_time| end_time|cnt|
+-----------------------------+-----------------------------+---+
|2024-11-26T13:37:00.000+08:00|2024-11-26T13:38:00.000+08:00| 2|
|2024-11-27T16:38:00.000+08:00|2024-11-30T14:30:00.000+08:00| 16|
+-----------------------------+-----------------------------+---+
Total line number = 21.3.2 Difference Segment Query
Segment the data in table2 by humidity value differences less than 0.1, and query the total number of data entries in each segment, as well as the start and end times.
- Query SQL
SELECT start_time, end_time, cnt
FROM table2
MATCH_RECOGNIZE (
ORDER BY time
MEASURES
RPR_FIRST(A.time) AS start_time,
RPR_LAST(time) AS end_time,
COUNT() AS cnt
PATTERN (A B*)
DEFINE B AS (B.humidity - PREV(B.humidity )) <=0.1
) AS m;- Results
+-----------------------------+-----------------------------+---+
| start_time| end_time|cnt|
+-----------------------------+-----------------------------+---+
|2024-11-26T13:37:00.000+08:00|2024-11-27T00:00:00.000+08:00| 2|
|2024-11-28T08:00:00.000+08:00|2024-11-29T00:00:00.000+08:00| 2|
|2024-11-29T11:00:00.000+08:00|2024-11-30T00:00:00.000+08:00| 2|
+-----------------------------+-----------------------------+---+
Total line number = 31.3.3 Event Statistics Query
Group the data in table1 by device ID, and count the start and end times and maximum humidity value where the humidity in the Shanghai area is greater than 35.
- Query SQL
SELECT m.device_id, m.match, m.event_start, m.event_end, m.max_humidity
FROM table1
MATCH_RECOGNIZE (
PARTITION BY device_id
ORDER BY time
MEASURES
MATCH_NUMBER() AS match,
RPR_FIRST(A.time) AS event_start,
RPR_LAST(A.time) AS event_end,
MAX(A.humidity) AS max_humidity
ONE ROW PER MATCH
PATTERN (A+)
DEFINE
A AS A.region= '上海' AND A.humidity> 35
) AS m- Results
+---------+-----+-----------------------------+-----------------------------+------------+
|device_id|match| event_start| event_end|max_humidity|
+---------+-----+-----------------------------+-----------------------------+------------+
| 100| 1|2024-11-28T09:00:00.000+08:00|2024-11-29T18:30:00.000+08:00| 45.1|
| 101| 1|2024-11-30T09:30:00.000+08:00|2024-11-30T09:30:00.000+08:00| 35.2|
+---------+-----+-----------------------------+-----------------------------+------------+
Total line number = 22. Window Functions
2.1 Function Overview
Window Functions perform calculations on each row based on a specific set of rows related to the current row (called a "window"). It combines grouping operations (PARTITION BY), sorting (ORDER BY), and definable calculation ranges (window frame FRAME), enabling complex cross-row calculations without collapsing the original data rows. It is commonly used in data analysis scenarios such as ranking, cumulative sums, moving averages, etc.
Note: This feature is available starting from version V 2.0.5.
For example, in a scenario where you need to query the cumulative power consumption values of different devices, you can achieve this using window functions.
-- Original data
+-----------------------------+------+-----+
| time|device| flow|
+-----------------------------+------+-----+
|1970-01-01T08:00:00.000+08:00| d0| 3|
|1970-01-01T08:00:00.001+08:00| d0| 5|
|1970-01-01T08:00:00.002+08:00| d0| 3|
|1970-01-01T08:00:00.003+08:00| d0| 1|
|1970-01-01T08:00:00.004+08:00| d1| 2|
|1970-01-01T08:00:00.005+08:00| d1| 4|
+-----------------------------+------+-----+
-- Create table and insert data
CREATE TABLE device_flow(device String tag, flow INT32 FIELD);
insert into device_flow(time, device ,flow ) values ('1970-01-01T08:00:00.000+08:00','d0',3),('1970-01-01T08:00:01.000+08:00','d0',5),('1970-01-01T08:00:02.000+08:00','d0',3),('1970-01-01T08:00:03.000+08:00','d0',1),('1970-01-01T08:00:04.000+08:00','d1',2),('1970-01-01T08:00:05.000+08:00','d1',4);
-- Execute window function query
SELECT *, sum(flow) OVER(PARTITION BY device ORDER BY flow) as sum FROM device_flow;After grouping, sorting, and calculation (steps are disassembled as shown in the figure below),
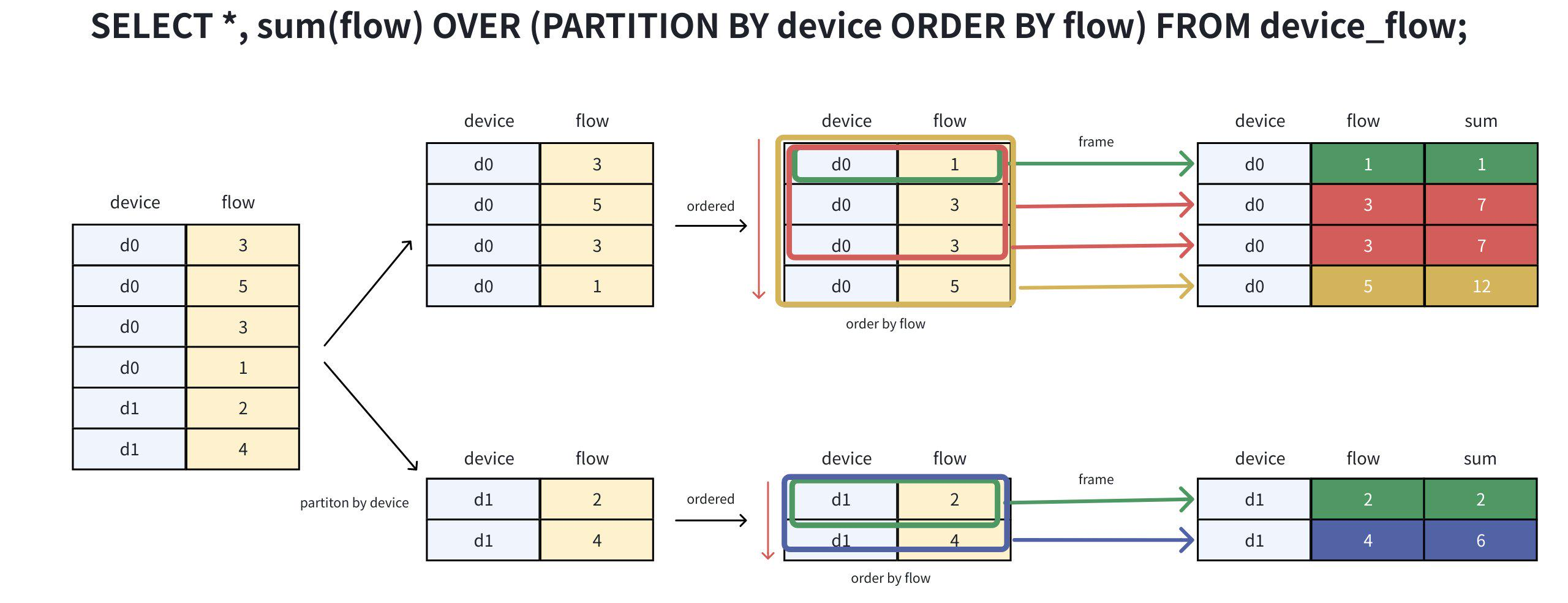
the expected results can be obtained:
+-----------------------------+------+----+----+
| time|device|flow| sum|
+-----------------------------+------+----+----+
|1970-01-01T08:00:04.000+08:00| d1| 2| 2.0|
|1970-01-01T08:00:05.000+08:00| d1| 4| 6.0|
|1970-01-01T08:00:03.000+08:00| d0| 1| 1.0|
|1970-01-01T08:00:00.000+08:00| d0| 3| 7.0|
|1970-01-01T08:00:02.000+08:00| d0| 3| 7.0|
|1970-01-01T08:00:01.000+08:00| d0| 5|12.0|
+-----------------------------+------+----+----+2.2 Function Definition
2.2.1 SQL Definition
windowDefinition
: name=identifier AS '(' windowSpecification ')'
;
windowSpecification
: (existingWindowName=identifier)?
(PARTITION BY partition+=expression (',' partition+=expression)*)?
(ORDER BY sortItem (',' sortItem)*)?
windowFrame?
;
windowFrame
: frameExtent
;
frameExtent
: frameType=RANGE start=frameBound
| frameType=ROWS start=frameBound
| frameType=GROUPS start=frameBound
| frameType=RANGE BETWEEN start=frameBound AND end=frameBound
| frameType=ROWS BETWEEN start=frameBound AND end=frameBound
| frameType=GROUPS BETWEEN start=frameBound AND end=frameBound
;
frameBound
: UNBOUNDED boundType=PRECEDING #unboundedFrame
| UNBOUNDED boundType=FOLLOWING #unboundedFrame
| CURRENT ROW #currentRowBound
| expression boundType=(PRECEDING | FOLLOWING) #boundedFrame
;2.2.2 Window Definition
2.2.2.1 Partition
PARTITION BY is used to divide data into multiple independent, unrelated "groups". Window functions can only access and operate on data within their respective groups, and cannot access data from other groups. This clause is optional; if not explicitly specified, all data is divided into the same group by default. It is worth noting that unlike GROUP BY which aggregates a group of data into a single row, the window function with PARTITION BY does not affect the number of rows within the group.
- Example
Query statement:
IoTDB> SELECT *, count(flow) OVER (PARTITION BY device) as count FROM device_flow;Disassembly steps:
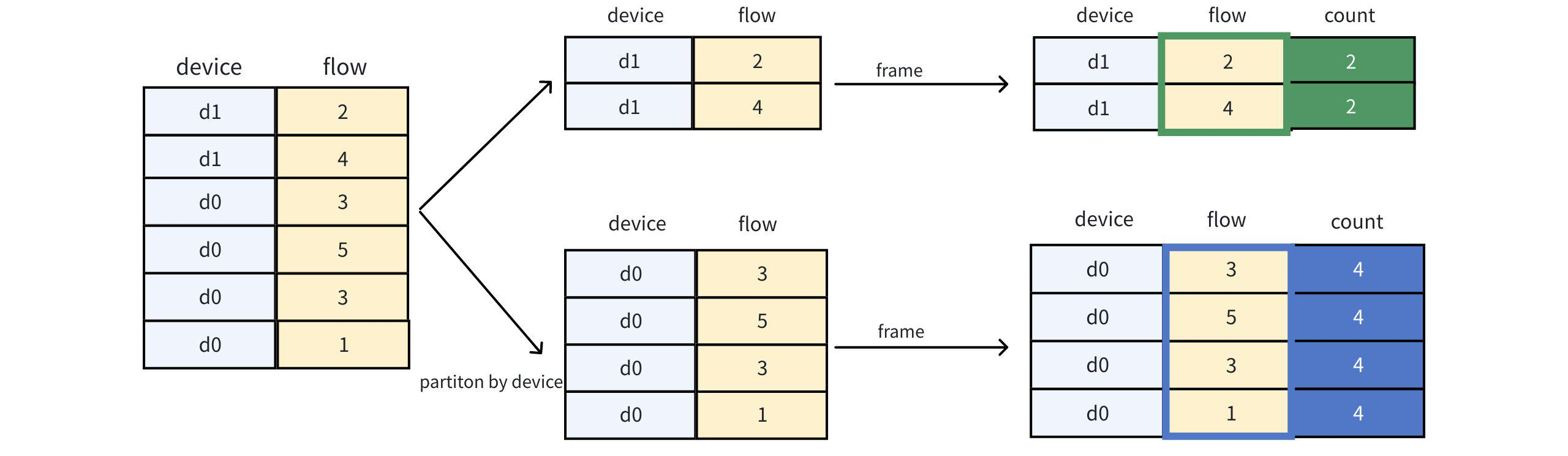
Query result:
+-----------------------------+------+----+-----+
| time|device|flow|count|
+-----------------------------+------+----+-----+
|1970-01-01T08:00:04.000+08:00| d1| 2| 2|
|1970-01-01T08:00:05.000+08:00| d1| 4| 2|
|1970-01-01T08:00:00.000+08:00| d0| 3| 4|
|1970-01-01T08:00:01.000+08:00| d0| 5| 4|
|1970-01-01T08:00:02.000+08:00| d0| 3| 4|
|1970-01-01T08:00:03.000+08:00| d0| 1| 4|
+-----------------------------+------+----+-----+2.2.2.2 Ordering
ORDER BY is used to sort data within a partition. After sorting, rows with equal values are called peers. Peers affect the behavior of window functions; for example, different rank functions handle peers differently, and different frame division methods also handle peers differently. This clause is optional.
- Example
Query statement:
IoTDB> SELECT *, rank() OVER (PARTITION BY device ORDER BY flow) as rank FROM device_flow;Disassembly steps:
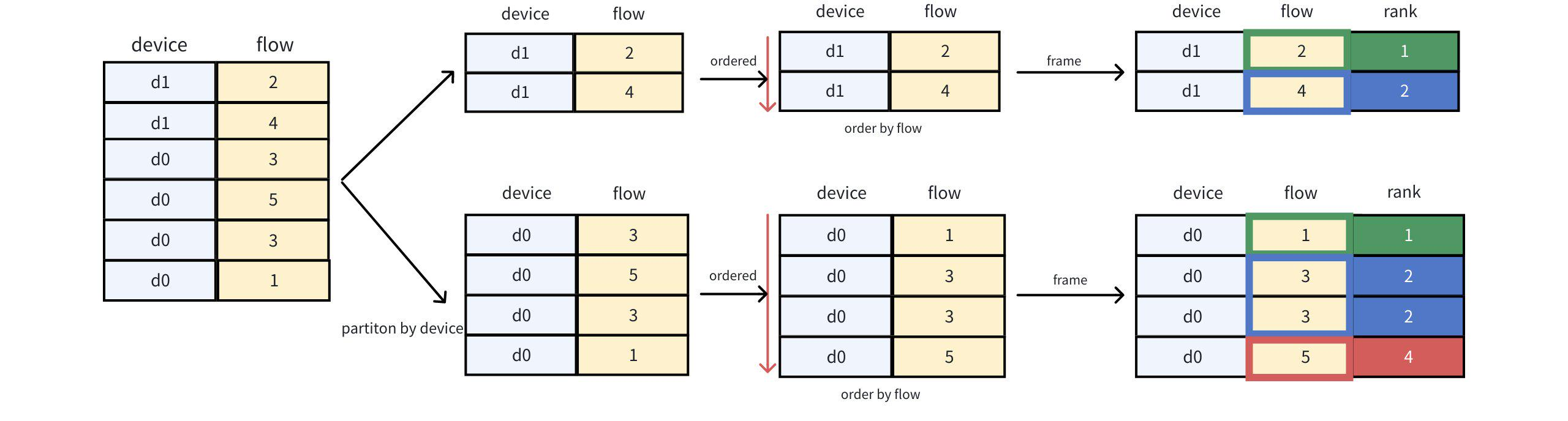
Query result:
+-----------------------------+------+----+----+
| time|device|flow|rank|
+-----------------------------+------+----+----+
|1970-01-01T08:00:04.000+08:00| d1| 2| 1|
|1970-01-01T08:00:05.000+08:00| d1| 4| 2|
|1970-01-01T08:00:03.000+08:00| d0| 1| 1|
|1970-01-01T08:00:00.000+08:00| d0| 3| 2|
|1970-01-01T08:00:02.000+08:00| d0| 3| 2|
|1970-01-01T08:00:01.000+08:00| d0| 5| 4|
+-----------------------------+------+----+----+2.2.2.3 Framing
For each row in a partition, the window function evaluates on a corresponding set of rows called a Frame (i.e., the input domain of the Window Function on each row). The Frame can be specified manually, involving two attributes when specified, as detailed below.
| Frame Attribute | Attribute Value | Value Description |
|---|---|---|
| Type | ROWS | Divide the frame by row number |
| GROUPS | Divide the frame by peers, i.e., rows with the same value are regarded as equivalent. All rows in peers are grouped into one group called a peer group | |
| RANGE | Divide the frame by value | |
| Start and End Position | UNBOUNDED PRECEDING | The first row of the entire partition |
| offset PRECEDING | Represents the row with an "offset" distance from the current row in the preceding direction | |
| CURRENT ROW | The current row | |
| offset FOLLOWING | Represents the row with an "offset" distance from the current row in the following direction | |
| UNBOUNDED FOLLOWING | The last row of the entire partition |
Among them, the meanings of CURRENT ROW, PRECEDING N, and FOLLOWING N vary with the type of frame, as shown in the following table:
ROWS | GROUPS | RANGE | |
|---|---|---|---|
CURRENT ROW | Current row | Since a peer group contains multiple rows, this option differs depending on whether it acts on frame_start and frame_end: * frame_start: the first row of the peer group; * frame_end: the last row of the peer group. | Same as GROUPS, differing depending on whether it acts on frame_start and frame_end: * frame_start: the first row of the peer group; * frame_end: the last row of the peer group. |
offset PRECEDING | The previous offset rows | The previous offset peer groups; | Rows whose value difference from the current row in the preceding direction is less than or equal to offset are grouped into one frame |
offset FOLLOWING | The following offset rows | The following offset peer groups. | Rows whose value difference from the current row in the following direction is less than or equal to offset are grouped into one frame |
The syntax format is as follows:
-- Specify both frame_start and frame_end
{ RANGE | ROWS | GROUPS } BETWEEN frame_start AND frame_end
-- Specify only frame_start, frame_end is CURRENT ROW
{ RANGE | ROWS | GROUPS } frame_startIf the Frame is not specified manually, the default Frame division rules are as follows:
- When the window function uses ORDER BY: The default Frame is RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW (i.e., from the first row of the window to the current row). For example: In RANK() OVER(PARTITION BY COL1 ORDER BY COL2), the Frame defaults to include the current row and all preceding rows in the partition.
- When the window function does not use ORDER BY: The default Frame is RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING (i.e., all rows in the entire window). For example: In AVG(COL2) OVER(PARTITION BY col1), the Frame defaults to include all rows in the partition, calculating the average of the entire partition.
It should be noted that when the Frame type is GROUPS or RANGE, ORDER BY must be specified. The difference is that ORDER BY in GROUPS can involve multiple fields, while RANGE requires calculation and thus can only specify one field.
- Example
- Frame type is ROWS
Query statement:
IoTDB> SELECT *, count(flow) OVER(PARTITION BY device ROWS 1 PRECEDING) as count FROM device_flow;Disassembly steps:
- Take the previous row and the current row as the Frame
- For the first row of the partition, since there is no previous row, the entire Frame has only this row, returning 1;
- For other rows of the partition, the entire Frame includes the current row and its previous row, returning 2:

Query result:
+-----------------------------+------+----+-----+
| time|device|flow|count|
+-----------------------------+------+----+-----+
|1970-01-01T08:00:04.000+08:00| d1| 2| 1|
|1970-01-01T08:00:05.000+08:00| d1| 4| 2|
|1970-01-01T08:00:00.000+08:00| d0| 3| 1|
|1970-01-01T08:00:01.000+08:00| d0| 5| 2|
|1970-01-01T08:00:02.000+08:00| d0| 3| 2|
|1970-01-01T08:00:03.000+08:00| d0| 1| 2|
+-----------------------------+------+----+-----+- Frame type is GROUPS
Query statement:
IoTDB> SELECT *, count(flow) OVER(PARTITION BY device ORDER BY flow GROUPS BETWEEN 1 PRECEDING AND CURRENT ROW) as count FROM device_flow;Disassembly steps:
- Take the previous peer group and the current peer group as the Frame. Taking the partition with device d0 as an example (same for d1), for the count of rows:
- For the peer group with flow 1, since there are no peer groups smaller than it, the entire Frame has only this row, returning 1;
- For the peer group with flow 3, it itself contains 2 rows, and the previous peer group is the one with flow 1 (1 row), so the entire Frame has 3 rows, returning 3;
- For the peer group with flow 5, it itself contains 1 row, and the previous peer group is the one with flow 3 (2 rows), so the entire Frame has 3 rows, returning 3.

Query result:
+-----------------------------+------+----+-----+
| time|device|flow|count|
+-----------------------------+------+----+-----+
|1970-01-01T08:00:04.000+08:00| d1| 2| 1|
|1970-01-01T08:00:05.000+08:00| d1| 4| 2|
|1970-01-01T08:00:03.000+08:00| d0| 1| 1|
|1970-01-01T08:00:00.000+08:00| d0| 3| 3|
|1970-01-01T08:00:02.000+08:00| d0| 3| 3|
|1970-01-01T08:00:01.000+08:00| d0| 5| 3|
+-----------------------------+------+----+-----+- Frame type is RANGE
Query statement:
IoTDB> SELECT *,count(flow) OVER(PARTITION BY device ORDER BY flow RANGE BETWEEN 2 PRECEDING AND CURRENT ROW) as count FROM device_flow;Disassembly steps:
- Group rows whose data is less than or equal to 2 compared to the current row into the same Frame. Taking the partition with device d0 as an example (same for d1), for the count of rows:
- For the row with flow 1, since it is the smallest row, the entire Frame has only this row, returning 1;
- For the row with flow 3, note that CURRENT ROW exists as frame_end, so it is the last row of the entire peer group. There is 1 row smaller than it that meets the requirement, and the peer group has 2 rows, so the entire Frame has 3 rows, returning 3;
- For the row with flow 5, it itself contains 1 row, and there are 2 rows smaller than it that meet the requirement, so the entire Frame has 3 rows, returning 3.

Query result:
+-----------------------------+------+----+-----+
| time|device|flow|count|
+-----------------------------+------+----+-----+
|1970-01-01T08:00:04.000+08:00| d1| 2| 1|
|1970-01-01T08:00:05.000+08:00| d1| 4| 2|
|1970-01-01T08:00:03.000+08:00| d0| 1| 1|
|1970-01-01T08:00:00.000+08:00| d0| 3| 3|
|1970-01-01T08:00:02.000+08:00| d0| 3| 3|
|1970-01-01T08:00:01.000+08:00| d0| 5| 3|
+-----------------------------+------+----+-----+2.3 Built-in Window Functions
| Window Function Category | Window Function Name | Function Definition | Supports FRAME Clause |
|---|---|---|---|
| Aggregate Function | All built-in aggregate functions | Aggregate a set of values to get a single aggregated result. | Yes |
| Value Function | first_value | Return the first value of the frame; if IGNORE NULLS is specified, skip leading NULLs | Yes |
| last_value | Return the last value of the frame; if IGNORE NULLS is specified, skip trailing NULLs | Yes | |
| nth_value | Return the nth element of the frame (note that n starts from 1); if IGNORE NULLS is specified, skip NULLs | Yes | |
| lead | Return the element offset rows after the current row (if IGNORE NULLS is specified, NULLs are not considered); if no such element exists (exceeding the partition range), return default | No | |
| lag | Return the element offset rows before the current row (if IGNORE NULLS is specified, NULLs are not considered); if no such element exists (exceeding the partition range), return default | No | |
| Rank Function | rank | Return the sequence number of the current row in the entire partition; rows with the same value have the same sequence number, and there may be gaps between sequence numbers | No |
| dense_rank | Return the sequence number of the current row in the entire partition; rows with the same value have the same sequence number, and there are no gaps between sequence numbers | No | |
| row_number | Return the row number of the current row in the entire partition; note that the row number starts from 1 | No | |
| percent_rank | Return the sequence number of the current row's value in the entire partition as a percentage; i.e., (rank() - 1) / (n - 1), where n is the number of rows in the entire partition | No | |
| cume_dist | Return the sequence number of the current row's value in the entire partition as a percentage; i.e., (number of rows less than or equal to it) / n | No | |
| ntile | Specify n to number each row from 1 to n. | No |
2.3.1 Aggregate Function
All built-in aggregate functions such as sum(), avg(), min(), max() can be used as Window Functions.
Note: Unlike GROUP BY, each row has a corresponding output in the Window Function
Example:
IoTDB> SELECT *, sum(flow) OVER (PARTITION BY device ORDER BY flow) as sum FROM device_flow;
+-----------------------------+------+----+----+
| time|device|flow| sum|
+-----------------------------+------+----+----+
|1970-01-01T08:00:04.000+08:00| d1| 2| 2.0|
|1970-01-01T08:00:05.000+08:00| d1| 4| 6.0|
|1970-01-01T08:00:03.000+08:00| d0| 1| 1.0|
|1970-01-01T08:00:00.000+08:00| d0| 3| 7.0|
|1970-01-01T08:00:02.000+08:00| d0| 3| 7.0|
|1970-01-01T08:00:01.000+08:00| d0| 5|12.0|
+-----------------------------+------+----+----+2.3.2 Value Function
first_value
- Function name:
first_value(value) [IGNORE NULLS] - Definition: Return the first value of the frame; if IGNORE NULLS is specified, skip leading NULLs;
- Example:
IoTDB> SELECT *, first_value(flow) OVER w as first_value FROM device_flow WINDOW w AS (PARTITION BY device ORDER BY flow ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING);
+-----------------------------+------+----+-----------+
| time|device|flow|first_value|
+-----------------------------+------+----+-----------+
|1970-01-01T08:00:04.000+08:00| d1| 2| 2|
|1970-01-01T08:00:05.000+08:00| d1| 4| 2|
|1970-01-01T08:00:03.000+08:00| d0| 1| 1|
|1970-01-01T08:00:00.000+08:00| d0| 3| 1|
|1970-01-01T08:00:02.000+08:00| d0| 3| 3|
|1970-01-01T08:00:01.000+08:00| d0| 5| 3|
+-----------------------------+------+----+-----------+last_value
- Function name:
last_value(value) [IGNORE NULLS] - Definition: Return the last value of the frame; if IGNORE NULLS is specified, skip trailing NULLs;
- Example:
IoTDB> SELECT *, last_value(flow) OVER w as last_value FROM device_flow WINDOW w AS (PARTITION BY device ORDER BY flow ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING);
+-----------------------------+------+----+----------+
| time|device|flow|last_value|
+-----------------------------+------+----+----------+
|1970-01-01T08:00:04.000+08:00| d1| 2| 4|
|1970-01-01T08:00:05.000+08:00| d1| 4| 4|
|1970-01-01T08:00:03.000+08:00| d0| 1| 3|
|1970-01-01T08:00:00.000+08:00| d0| 3| 3|
|1970-01-01T08:00:02.000+08:00| d0| 3| 5|
|1970-01-01T08:00:01.000+08:00| d0| 5| 5|
+-----------------------------+------+----+----------+nth_value
- Function name:
nth_value(value, n) [IGNORE NULLS] - Definition: Return the nth element of the frame (note that n starts from 1); if IGNORE NULLS is specified, skip NULLs;
- Example:
IoTDB> SELECT *, nth_value(flow, 2) OVER w as nth_values FROM device_flow WINDOW w AS (PARTITION BY device ORDER BY flow ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING);
+-----------------------------+------+----+----------+
| time|device|flow|nth_values|
+-----------------------------+------+----+----------+
|1970-01-01T08:00:04.000+08:00| d1| 2| 4|
|1970-01-01T08:00:05.000+08:00| d1| 4| 4|
|1970-01-01T08:00:03.000+08:00| d0| 1| 3|
|1970-01-01T08:00:00.000+08:00| d0| 3| 3|
|1970-01-01T08:00:02.000+08:00| d0| 3| 3|
|1970-01-01T08:00:01.000+08:00| d0| 5| 5|
+-----------------------------+------+----+----------+- lead
- Function name:
lead(value[, offset[, default]]) [IGNORE NULLS] - Definition: Return the element offset rows after the current row (if IGNORE NULLS is specified, NULLs are not considered); if no such element exists (exceeding the partition range), return default; the default value of offset is 1, and the default value of default is NULL.
- The lead function requires an ORDER BY window clause
- Example:
IoTDB> SELECT *, lead(flow) OVER w as lead FROM device_flow WINDOW w AS(PARTITION BY device ORDER BY time);
+-----------------------------+------+----+----+
| time|device|flow|lead|
+-----------------------------+------+----+----+
|1970-01-01T08:00:04.000+08:00| d1| 2| 4|
|1970-01-01T08:00:05.000+08:00| d1| 4|null|
|1970-01-01T08:00:00.000+08:00| d0| 3| 5|
|1970-01-01T08:00:01.000+08:00| d0| 5| 3|
|1970-01-01T08:00:02.000+08:00| d0| 3| 1|
|1970-01-01T08:00:03.000+08:00| d0| 1|null|
+-----------------------------+------+----+----+- lag
- Function name:
lag(value[, offset[, default]]) [IGNORE NULLS] - Definition: Return the element offset rows before the current row (if IGNORE NULLS is specified, NULLs are not considered); if no such element exists (exceeding the partition range), return default; the default value of offset is 1, and the default value of default is NULL.
- The lag function requires an ORDER BY window clause
- Example:
IoTDB> SELECT *, lag(flow) OVER w as lag FROM device_flow WINDOW w AS(PARTITION BY device ORDER BY device);
+-----------------------------+------+----+----+
| time|device|flow| lag|
+-----------------------------+------+----+----+
|1970-01-01T08:00:04.000+08:00| d1| 2|null|
|1970-01-01T08:00:05.000+08:00| d1| 4| 2|
|1970-01-01T08:00:00.000+08:00| d0| 3|null|
|1970-01-01T08:00:01.000+08:00| d0| 5| 3|
|1970-01-01T08:00:02.000+08:00| d0| 3| 5|
|1970-01-01T08:00:03.000+08:00| d0| 1| 3|
+-----------------------------+------+----+----+2.3.3 Rank Function
- rank
- Function name:
rank() - Definition: Return the sequence number of the current row in the entire partition; rows with the same value have the same sequence number, and there may be gaps between sequence numbers;
- Example:
IoTDB> SELECT *, rank() OVER w as rank FROM device_flow WINDOW w AS (PARTITION BY device ORDER BY flow);
+-----------------------------+------+----+----+
| time|device|flow|rank|
+-----------------------------+------+----+----+
|1970-01-01T08:00:04.000+08:00| d1| 2| 1|
|1970-01-01T08:00:05.000+08:00| d1| 4| 2|
|1970-01-01T08:00:03.000+08:00| d0| 1| 1|
|1970-01-01T08:00:00.000+08:00| d0| 3| 2|
|1970-01-01T08:00:02.000+08:00| d0| 3| 2|
|1970-01-01T08:00:01.000+08:00| d0| 5| 4|
+-----------------------------+------+----+----+- dense_rank
- Function name:
dense_rank() - Definition: Return the sequence number of the current row in the entire partition; rows with the same value have the same sequence number, and there are no gaps between sequence numbers.
- Example:
IoTDB> SELECT *, dense_rank() OVER w as dense_rank FROM device_flow WINDOW w AS (PARTITION BY device ORDER BY flow);
+-----------------------------+------+----+----------+
| time|device|flow|dense_rank|
+-----------------------------+------+----+----------+
|1970-01-01T08:00:04.000+08:00| d1| 2| 1|
|1970-01-01T08:00:05.000+08:00| d1| 4| 2|
|1970-01-01T08:00:03.000+08:00| d0| 1| 1|
|1970-01-01T08:00:00.000+08:00| d0| 3| 2|
|1970-01-01T08:00:02.000+08:00| d0| 3| 2|
|1970-01-01T08:00:01.000+08:00| d0| 5| 3|
+-----------------------------+------+----+----------+- row_number
- Function name:
row_number() - Definition: Return the row number of the current row in the entire partition; note that the row number starts from 1;
- Example:
IoTDB> SELECT *, row_number() OVER w as row_number FROM device_flow WINDOW w AS (PARTITION BY device ORDER BY flow);
+-----------------------------+------+----+----------+
| time|device|flow|row_number|
+-----------------------------+------+----+----------+
|1970-01-01T08:00:04.000+08:00| d1| 2| 1|
|1970-01-01T08:00:05.000+08:00| d1| 4| 2|
|1970-01-01T08:00:03.000+08:00| d0| 1| 1|
|1970-01-01T08:00:00.000+08:00| d0| 3| 2|
|1970-01-01T08:00:02.000+08:00| d0| 3| 3|
|1970-01-01T08:00:01.000+08:00| d0| 5| 4|
+-----------------------------+------+----+----------+- percent_rank
- Function name:
percent_rank() - Definition: Return the sequence number of the current row's value in the entire partition as a percentage; i.e., (rank() - 1) / (n - 1), where n is the number of rows in the entire partition;
- Example:
IoTDB> SELECT *, percent_rank() OVER w as percent_rank FROM device_flow WINDOW w AS (PARTITION BY device ORDER BY flow);
+-----------------------------+------+----+------------------+
| time|device|flow| percent_rank|
+-----------------------------+------+----+------------------+
|1970-01-01T08:00:04.000+08:00| d1| 2| 0.0|
|1970-01-01T08:00:05.000+08:00| d1| 4| 1.0|
|1970-01-01T08:00:03.000+08:00| d0| 1| 0.0|
|1970-01-01T08:00:00.000+08:00| d0| 3|0.3333333333333333|
|1970-01-01T08:00:02.000+08:00| d0| 3|0.3333333333333333|
|1970-01-01T08:00:01.000+08:00| d0| 5| 1.0|
+-----------------------------+------+----+------------------+- cume_dist
- Function name:
cume_dist - Definition: Return the sequence number of the current row's value in the entire partition as a percentage; i.e., (number of rows less than or equal to it) / n.
- Example:
IoTDB> SELECT *, cume_dist() OVER w as cume_dist FROM device_flow WINDOW w AS (PARTITION BY device ORDER BY flow);
+-----------------------------+------+----+---------+
| time|device|flow|cume_dist|
+-----------------------------+------+----+---------+
|1970-01-01T08:00:04.000+08:00| d1| 2| 0.5|
|1970-01-01T08:00:05.000+08:00| d1| 4| 1.0|
|1970-01-01T08:00:03.000+08:00| d0| 1| 0.25|
|1970-01-01T08:00:00.000+08:00| d0| 3| 0.75|
|1970-01-01T08:00:02.000+08:00| d0| 3| 0.75|
|1970-01-01T08:00:01.000+08:00| d0| 5| 1.0|
+-----------------------------+------+----+---------+- ntile
- Function name:
ntile - Definition: Specify n to number each row from 1 to n.
- If the number of rows in the entire partition is less than n, the number is the row index;
- If the number of rows in the entire partition is greater than n:
- If the number of rows is divisible by n, it is perfect. For example, if the number of rows is 4 and n is 2, the numbers are 1, 1, 2, 2;
- If the number of rows is not divisible by n, distribute to the first few groups. For example, if the number of rows is 5 and n is 3, the numbers are 1, 1, 2, 2, 3;
- Example:
IoTDB> SELECT *, ntile(2) OVER w as ntile FROM device_flow WINDOW w AS (PARTITION BY device ORDER BY flow);
+-----------------------------+------+----+-----+
| time|device|flow|ntile|
+-----------------------------+------+----+-----+
|1970-01-01T08:00:04.000+08:00| d1| 2| 1|
|1970-01-01T08:00:05.000+08:00| d1| 4| 2|
|1970-01-01T08:00:03.000+08:00| d0| 1| 1|
|1970-01-01T08:00:00.000+08:00| d0| 3| 1|
|1970-01-01T08:00:02.000+08:00| d0| 3| 2|
|1970-01-01T08:00:01.000+08:00| d0| 5| 2|
+-----------------------------+------+----+-----+2.4 Scenario Examples
- Multi-device diff function
For each row of each device, calculate the difference from the previous row:
SELECT
*,
measurement - lag(measurement) OVER (PARTITION BY device ORDER BY time)
FROM data
WHERE timeCondition;For each row of each device, calculate the difference from the next row:
SELECT
*,
measurement - lead(measurement) OVER (PARTITION BY device ORDER BY time)
FROM data
WHERE timeCondition;For each row of a single device, calculate the difference from the previous row (same for the next row):
SELECT
*,
measurement - lag(measurement) OVER (ORDER BY time)
FROM data
where device='d1'
WHERE timeCondition;- Multi-device TOP_K/BOTTOM_K
Use rank to get the sequence number, then retain the desired order in the outer query.
(Note: The execution order of window functions is after the HAVING clause, so a subquery is needed here)
SELECT *
FROM(
SELECT
*,
rank() OVER (PARTITION BY device ORDER BY time DESC)
FROM data
WHERE timeCondition
)
WHERE rank <= 3;In addition to sorting by time, you can also sort by the value of the measurement point:
SELECT *
FROM(
SELECT
*,
rank() OVER (PARTITION BY device ORDER BY measurement DESC)
FROM data
WHERE timeCondition
)
WHERE rank <= 3;- Multi-device CHANGE_POINTS
This SQL is used to remove consecutive identical values in the input sequence, which can be achieved with lead + subquery:
SELECT
time,
device,
measurement
FROM(
SELECT
time,
device,
measurement,
LEAD(measurement) OVER (PARTITION BY device ORDER BY time) AS next
FROM data
WHERE timeCondition
)
WHERE measurement != next OR next IS NULL;