
时序特色分析
时序特色分析
IoTDB 针对时序数据的特色分析场景,提供了模式查询与窗口函数两大核心能力,为时序数据的深度挖掘与复杂计算提供了灵活高效的解决方案。下文将对两大功能进行详细的介绍。
1. 模式查询
1.1 概述
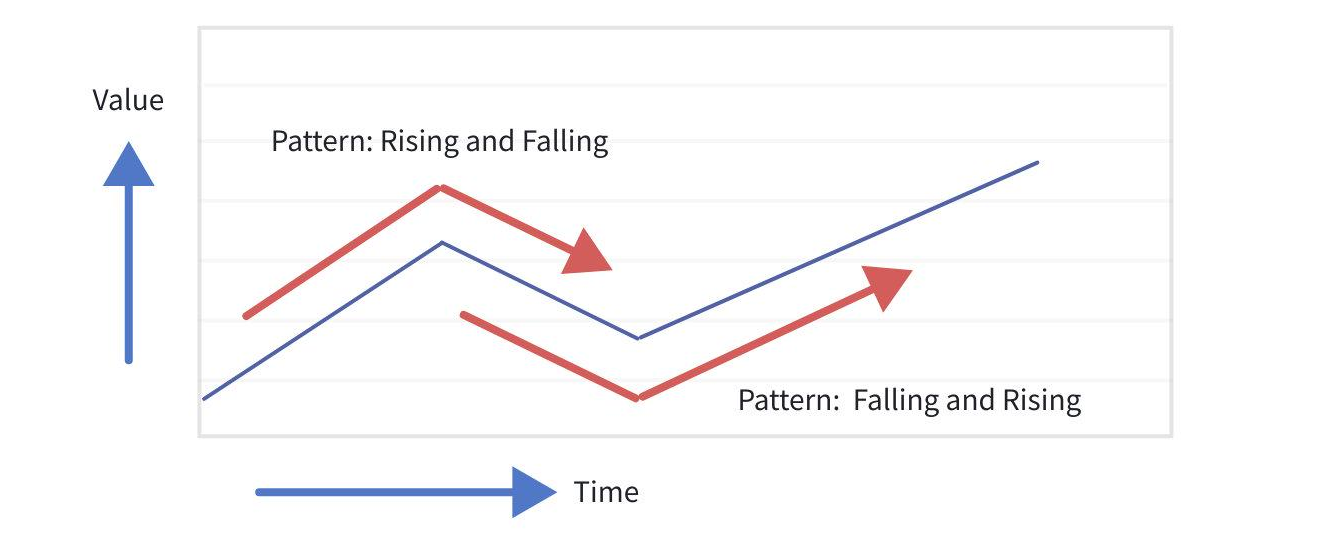
模式查询支持通过定义模式变量的识别逻辑以及正则表达式来捕获一段连续的数据,并对每一段捕获的数据进行分析计算,适用于识别时序数据中的特定模式(如下图所示)、检测特定事件等业务场景。
注意:该功能从 V 2.0.5 版本开始提供。
1.2 功能介绍
1.2.1 语法格式
MATCH_RECOGNIZE (
[ PARTITION BY column [, ...] ]
[ ORDER BY column [, ...] ]
[ MEASURES measure_definition [, ...] ]
[ ROWS PER MATCH ]
[ AFTER MATCH skip_to ]
PATTERN ( row_pattern )
[ SUBSET subset_definition [, ...] ]
DEFINE variable_definition [, ...]
)说明:
- PARTITION BY : 可选,用于对输入表进行分组,每个分组能独立进行模式匹配。如果未声明该子句,则整个输入表将作为一个整体进行处理。
- ORDER BY :可选,用于确保输入数据按某种顺序进行匹配处理。
- MEASURES :可选,用于指定从匹配到的一段数据中提取哪些信息。
- ROWS PER MATCH :可选,用于指定模式匹配成功后结果集的输出方式。
- AFTER MATCH SKIP :可选,用于指定在识别到一个非空匹配后,下一次模式匹配应从哪一行继续进行。
- PATTERN :用于定义需要匹配的行模式。
- SUBSET :可选,用于将多个基本模式变量所匹配的行合并为一个逻辑集合。
- DEFINE :用于定义行模式的基本模式变量。
语法示例原始数据:
IoTDB:database3> select * from t
+-----------------------------+------+----------+
| time|device|totalprice|
+-----------------------------+------+----------+
|2025-01-01T00:01:00.000+08:00| d1| 90|
|2025-01-01T00:02:00.000+08:00| d1| 80|
|2025-01-01T00:03:00.000+08:00| d1| 70|
|2025-01-01T00:04:00.000+08:00| d1| 80|
|2025-01-01T00:05:00.000+08:00| d1| 70|
|2025-01-01T00:06:00.000+08:00| d1| 80|
+-----------------------------+------+----------+
-- 创建语句
create table t(device tag, totalprice int32 field)
insert into t(time,device,totalprice) values(2025-01-01T00:01:00, 'd1', 90),(2025-01-01T00:02:00, 'd1', 80),(2025-01-01T00:03:00, 'd1', 70),(2025-01-01T00:04:00, 'd1', 80),(2025-01-01T00:05:00, 'd1', 70),(2025-01-01T00:06:00, 'd1', 80)1.2.2 DEFINE 子句
用于为模式识别中的每个基本模式变量指定其判断条件。这些变量通常由标识符(如 A, B)代表,并通过该子句中的布尔表达式精确定义哪些行符合该变量的要求。
- 在模式匹配执行过程中,仅当布尔表达式返回 TRUE 时,才会将当前行标记为该变量,从而将其纳入到当前匹配分组中。
-- 只有在当前行的 totalprice 值小于前一行 totalprice 值的情况下,当前行才可以被识别为 B。
DEFINE B AS totalprice < PREV(totalprice)- 未在子句中显式定义的变量,其匹配条件隐含为恒真(TRUE),即可在任何输入行上成功匹配。
1.2.3 SUBSET 子句
用于将多个基本模式变量(如 A、B)匹配到的行合并成一个联合模式变量(如 U),使这些行可以被视为同一个逻辑集合进行操作。可用于MEASURES、DEFINE 和AFTER MATCH SKIP子句。
SUBSET U = (A, B)例如,对于模式 PATTERN ((A | B){5} C+) ,在匹配过程中无法确定第五次重复时具体匹配的是基本模式变量 A 还是 B,因此
- 在
MEASURES子句中,若需要引用该阶段最后一次匹配到的行,则可通过定义联合模式变量SUBSET U = (A, B)实现。此时表达式RPR_LAST(U.totalprice)将直接返回该目标行的totalprice值。 - 在
AFTER MATCH SKIP子句中,若匹配结果中未包含基本模式变量 A 或 B 时,执行AFTER MATCH SKIP TO LAST B或AFTER MATCH SKIP TO LAST A会因锚点缺失跳转失败;而通过引入联合模式变量SUBSET U = (A, B),使用AFTER MATCH SKIP TO LAST U则始终有效。
1.2.4 PATTERN 子句
用于定义需要匹配的行模式,其基本构成单元是基本模式变量。
PATTERN ( row_pattern )1.2.4.1 模式种类
| 行模式 | 语法格式 | 描述 |
|---|---|---|
| 模式连接(Pattern Concatenation) | A B+ C+ D+ | 由不带任何运算符的子模式组成,按声明顺序依次匹配所有子模式。 |
| 模式选择(Pattern Alternation) | A | B | C | 由以|分隔的多个子模式组成,仅匹配其中一个。当多个子模式均可匹配时,选择最左侧的子模式匹配。 |
| 模式排列(Pattern Permutation) | PERMUTE(A, B, C) | 该模式等价于对所有子模式元素的不同顺序进行选择匹配,即要求 A、B、C 三者均须匹配,但其出现顺序不固定。当多种匹配顺序均可成功时,依据 PERMUTE 列表中元素的定义先后顺序,按字典序原则确定优先级。例如,A B C 为最高优先,C B A 则为最低优先。 |
| 模式分组(Pattern Grouping) | (A B C) | 用圆括号将子模式括起,视作一个整体对待,可与其他运算符配合使用。如(A B C)+表示连续出现一组(A B C)的模式。 |
| 空模式(Empty Pattern) | () | 表示一个不包含任何行的空匹配 |
| 模式排除(Pattern Exclusion) | {- row_pattern -} | 用于指定在输出中需要排除的匹配部分。通常与ALL ROWS PER MATCH选项结合使用,用于输出感兴趣的行。如PATTERN (A {- B+ C+ -} D+),并使用ALL ROWS PER MATCH时,输出将仅包含匹配的首行(A对应行)与尾部行(D+对应行)。 |
1.2.4.2 分区起始/结束锚点(Partition Start/End Anchor)
^A表示匹配以 A 为分区开始的模式- 当 PATTERN 子句的取值为
^A时,要求匹配必须从分区的首行开始,且这一行要满足A的定义 - 当 PATTERN 子句的取值为
^A^或A^时,输出结果为空
- 当 PATTERN 子句的取值为
A$表示匹配以 A 为分区结束的模式- 当 PATTERN 子句的取值为
A$时,要求必须在分区的结束位置匹配,并且这一行要满足A的定义 - 当 PATTERN 子句的取值为
$A或$A$时,输出结果为空
- 当 PATTERN 子句的取值为
示例说明
- 查询 sql
SELECT m.time, m.match, m.price, m.label
FROM t
MATCH_RECOGNIZE (
ORDER BY time
MEASURES
MATCH_NUMBER() AS match,
RUNNING RPR_LAST(totalprice) AS price,
CLASSIFIER() AS label
ALL ROWS PER MATCH
AFTER MATCH SKIP PAST LAST ROW
PATTERN %s -- PATTERN 子句
DEFINE A AS true
) AS m;查询结果
- 当 PATTERN 子句为 PATTERN (^A) 时
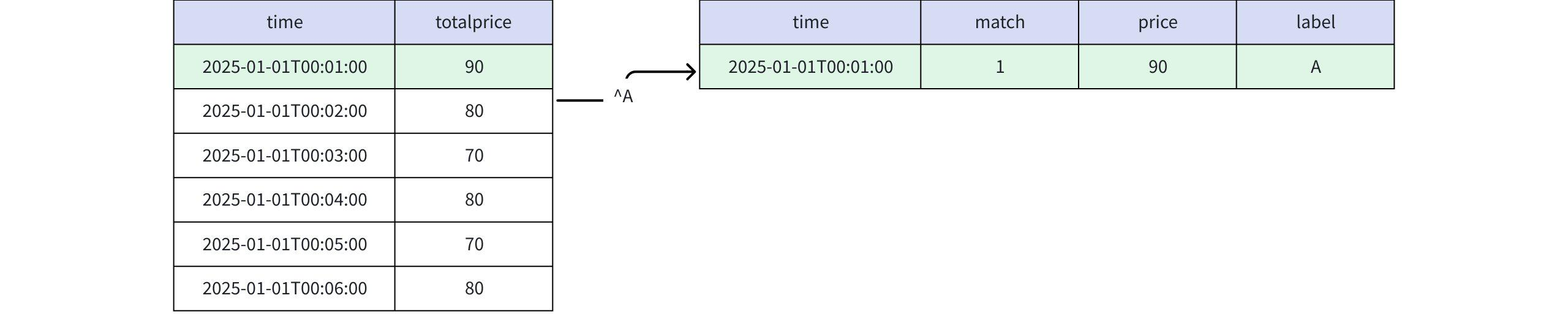
实际返回
+-----------------------------+-----+-----+-----+ | time|match|price|label| +-----------------------------+-----+-----+-----+ |2025-01-01T00:01:00.000+08:00| 1| 90| A| +-----------------------------+-----+-----+-----+ Total line number = 1- 当 PATTERN 子句为 PATTERN (^A^) 时,输出的结果为空,因为不可能从分区的起始位置开始匹配了一个 A 之后,又回到分区的起始位置
+----+-----+-----+-----+ |time|match|price|label| +----+-----+-----+-----+ +----+-----+-----+-----+ Empty set.- 当 PATTERN 子句为 PATTERN (A$) 时
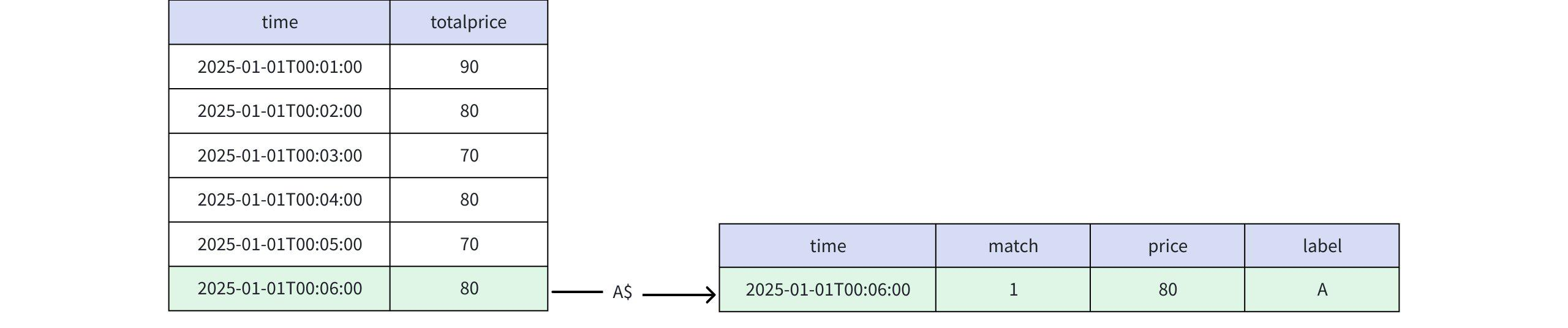
实际返回
+-----------------------------+-----+-----+-----+ | time|match|price|label| +-----------------------------+-----+-----+-----+ |2025-01-01T00:06:00.000+08:00| 1| 80| A| +-----------------------------+-----+-----+-----+ Total line number = 1- 当 PATTERN 子句为 PATTERN ($A$) 时,输出的结果为空
+----+-----+-----+-----+ |time|match|price|label| +----+-----+-----+-----+ +----+-----+-----+-----+ Empty set.
1.2.4.3 量词(Quantifiers)
量词用于指定子模式重复出现的次数,置于相应子模式之后,如 (A | B)*。
常用量词如下:
| 量词 | 描述 |
|---|---|
* | 零次或多次重复 |
+ | 一次或多次重复 |
? | 零次或一次重复 |
{n} | 恰好重复 n 次 |
{m, n} | 重复次数在 m 到 n 之间(m、n 为非负整数)。* 若省略左界,则默认从 0 开始;* 若省略右界,则重复次数不设上限(如 {5,} 等同于“至少重复五次”);* 若同时省略左右界,即 {,},则与 * 等价。 |
- 可通过在量词后加
?改变匹配偏好。{3,5}:偏好 5 次,最不偏好 3 次;{3,5}?:偏好 3 次,最不偏好 5 次?:偏好 1 次;??:偏好 0 次
1.2.5 AFTER MATCH SKIP 子句
用于指定在识别到一个非空匹配后,下一次模式匹配应从哪一行继续进行。
| 跳转策略 | 描述 | 是否允许识别重叠匹配项 |
|---|---|---|
AFTER MATCH SKIP PAST LAST ROW | 默认行为。在当前匹配的最后一行之后的下一行开始。 | 否 |
AFTER MATCH SKIP TO NEXT ROW | 在当前匹配中的第二行开始。 | 是 |
AFTER MATCH SKIP TO [ FIRST | LAST ] pattern_variable | 跳转到某个模式变量的 [ 第一行 | 最后一行 ] 开始。 | 是 |
- 在所有可能的配置中,仅当
ALL ROWS PER MATCH WITH UNMATCHED ROWS与AFTER MATCH SKIP PAST LAST ROW联合使用时,系统才能确保对每个输入行恰好生成一条输出记录。
示例说明
- 查询 sql
SELECT m.time, m.match, m.price, m.label
FROM t
MATCH_RECOGNIZE (
ORDER BY time
MEASURES
MATCH_NUMBER() AS match,
RUNNING RPR_LAST(totalprice) AS price,
CLASSIFIER() AS label
ALL ROWS PER MATCH
%s -- AFTER MATCH SKIP 子句
PATTERN (A B+ C+ D?)
SUBSET U = (C, D)
DEFINE
B AS B.totalprice < PREV (B.totalprice),
C AS C.totalprice > PREV (C.totalprice),
D AS false -- 永远不会匹配成功
) AS m;查询结果
- 当 AFTER MATCH SKIP PAST LAST ROW 时
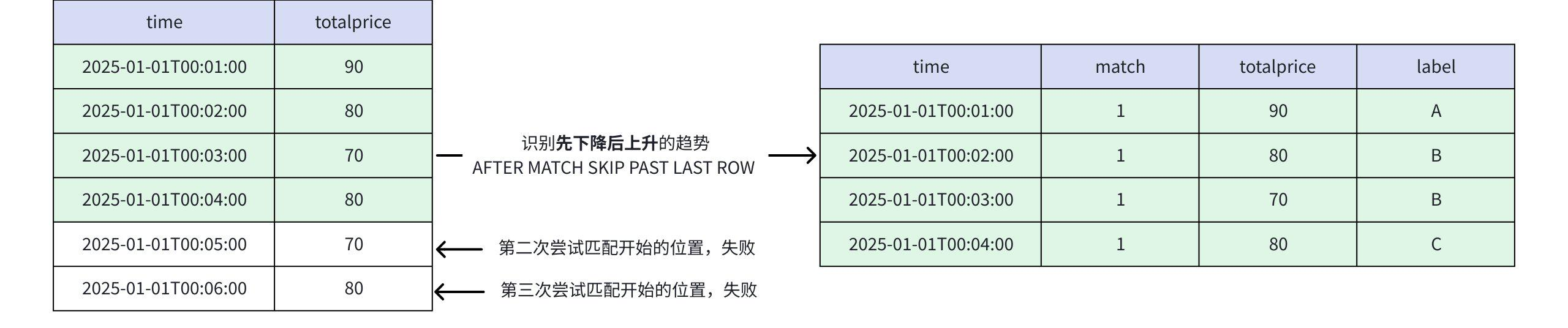
- 第一次匹配:第 1、2、3、4 行
- 第二次匹配:根据
AFTER MATCH SKIP PAST LAST ROW语义,从第 5 行开始,无法再找寻到一个合法匹配 - 此模式一定不会出现重叠匹配
+-----------------------------+-----+-----+-----+ | time|match|price|label| +-----------------------------+-----+-----+-----+ |2025-01-01T00:01:00.000+08:00| 1| 90| A| |2025-01-01T00:02:00.000+08:00| 1| 80| B| |2025-01-01T00:03:00.000+08:00| 1| 70| B| |2025-01-01T00:04:00.000+08:00| 1| 80| C| +-----------------------------+-----+-----+-----+ Total line number = 4- 当 AFTER MATCH SKIP TO NEXT ROW 时

- 第一次匹配:第 1、2、3、4 行
- 第二次匹配:根据
AFTER MATCH SKIP TO NEXT ROW语义,从第 2 行开始,匹配:第 2、3、4 行 - 第三次匹配:尝试从第 3 行开始,失败
- 第三次匹配:尝试从第 4 行开始,成功,匹配第 4、5、6行
- 此模式允许出现重叠匹配
+-----------------------------+-----+-----+-----+ | time|match|price|label| +-----------------------------+-----+-----+-----+ |2025-01-01T00:01:00.000+08:00| 1| 90| A| |2025-01-01T00:02:00.000+08:00| 1| 80| B| |2025-01-01T00:03:00.000+08:00| 1| 70| B| |2025-01-01T00:04:00.000+08:00| 1| 80| C| |2025-01-01T00:02:00.000+08:00| 2| 80| A| |2025-01-01T00:03:00.000+08:00| 2| 70| B| |2025-01-01T00:04:00.000+08:00| 2| 80| C| |2025-01-01T00:04:00.000+08:00| 3| 80| A| |2025-01-01T00:05:00.000+08:00| 3| 70| B| |2025-01-01T00:06:00.000+08:00| 3| 80| C| +-----------------------------+-----+-----+-----+ Total line number = 10- 当 AFTER MATCH SKIP TO FIRST C 时
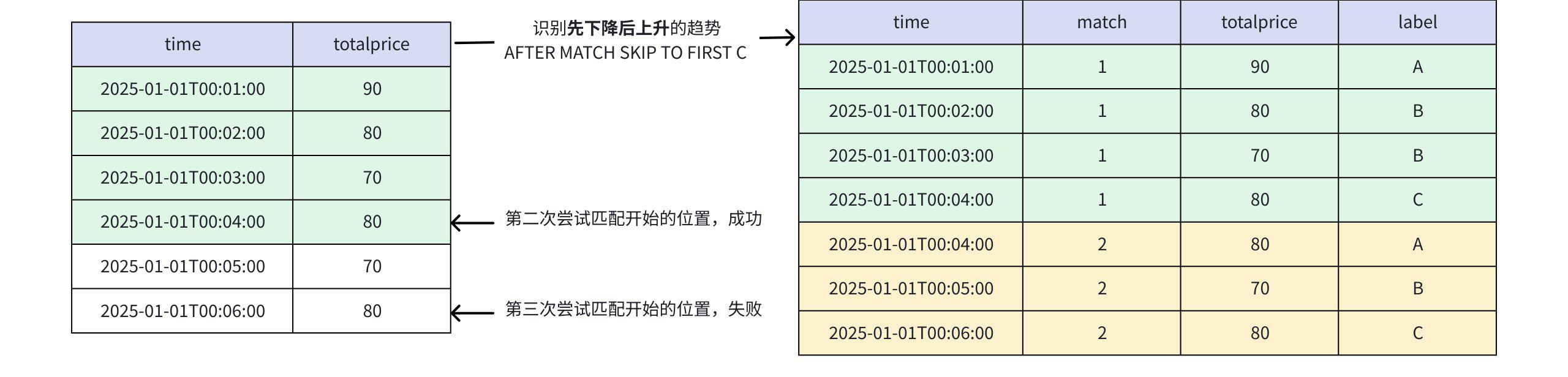
- 第一次匹配:第 1、2、3、4 行
- 第二次匹配:从第一个 C (也就是第 4 行)处开始,匹配第4、5、6行
- 此模式允许出现重叠匹配
+-----------------------------+-----+-----+-----+ | time|match|price|label| +-----------------------------+-----+-----+-----+ |2025-01-01T00:01:00.000+08:00| 1| 90| A| |2025-01-01T00:02:00.000+08:00| 1| 80| B| |2025-01-01T00:03:00.000+08:00| 1| 70| B| |2025-01-01T00:04:00.000+08:00| 1| 80| C| |2025-01-01T00:04:00.000+08:00| 2| 80| A| |2025-01-01T00:05:00.000+08:00| 2| 70| B| |2025-01-01T00:06:00.000+08:00| 2| 80| C| +-----------------------------+-----+-----+-----+ Total line number = 7- 当 AFTER MATCH SKIP TO LAST B 或 AFTER MATCH SKIP TO B 时

- 第一次匹配:第 1、2、3、4 行
- 第二次匹配:尝试从最后一个 B (也就是第 3 行)处开始,失败
- 第二次匹配:尝试从第 4 行开始,成功匹配第4、5、6行
- 此模式允许出现重叠匹配
+-----------------------------+-----+-----+-----+ | time|match|price|label| +-----------------------------+-----+-----+-----+ |2025-01-01T00:01:00.000+08:00| 1| 90| A| |2025-01-01T00:02:00.000+08:00| 1| 80| B| |2025-01-01T00:03:00.000+08:00| 1| 70| B| |2025-01-01T00:04:00.000+08:00| 1| 80| C| |2025-01-01T00:04:00.000+08:00| 2| 80| A| |2025-01-01T00:05:00.000+08:00| 2| 70| B| |2025-01-01T00:06:00.000+08:00| 2| 80| C| +-----------------------------+-----+-----+-----+ Total line number = 7- 当 AFTER MATCH SKIP TO U 时
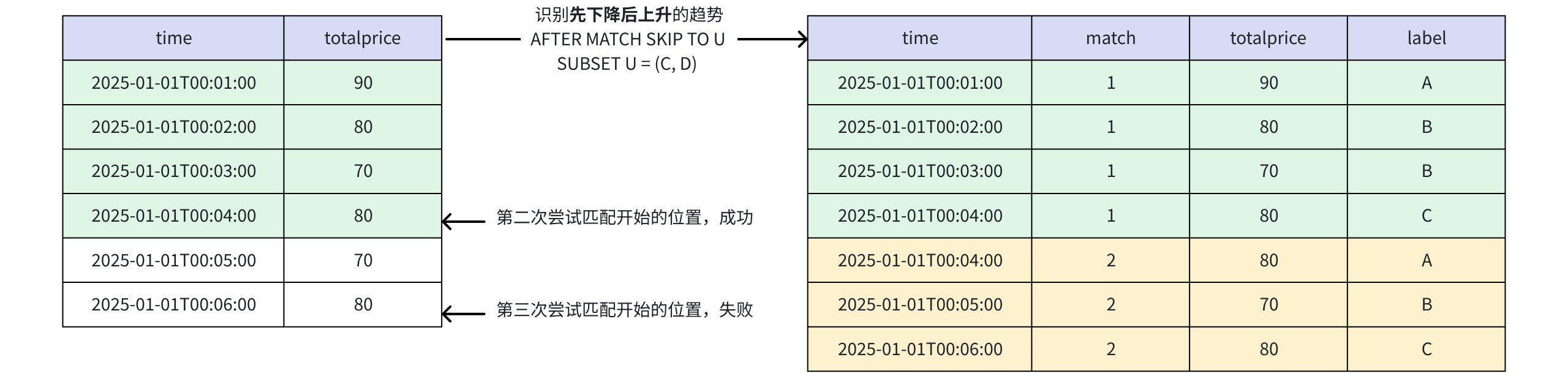
- 第一次匹配:第 1、2、3、4 行
- 第二次匹配:
SKIP TO U表示跳转到最后一个 C 或 D,D 永远不可能匹配成功,所以就是跳转到最后一个 C(也就是第 4 行),成功匹配第4、5、6行 - 此模式允许出现重叠匹配
+-----------------------------+-----+-----+-----+ | time|match|price|label| +-----------------------------+-----+-----+-----+ |2025-01-01T00:01:00.000+08:00| 1| 90| A| |2025-01-01T00:02:00.000+08:00| 1| 80| B| |2025-01-01T00:03:00.000+08:00| 1| 70| B| |2025-01-01T00:04:00.000+08:00| 1| 80| C| |2025-01-01T00:04:00.000+08:00| 2| 80| A| |2025-01-01T00:05:00.000+08:00| 2| 70| B| |2025-01-01T00:06:00.000+08:00| 2| 80| C| +-----------------------------+-----+-----+-----+ Total line number = 7- 当 AFTER MATCH SKIP TO A 时,报错。因为不能跳转到匹配的第一行, 否则会造成死循环。
Msg: org.apache.iotdb.jdbc.IoTDBSQLException: 701: AFTER MATCH SKIP TO failed: cannot skip to first row of match- 当 AFTER MATCH SKIP TO B 时,报错。因为不能跳转到匹配分组中不存在的模式变量。
Msg: org.apache.iotdb.jdbc.IoTDBSQLException: 701: AFTER MATCH SKIP TO failed: pattern variable is not present in match
1.2.6 ROWS PER MATCH 子句
用于指定模式匹配成功后结果集的输出方式,主要包括以下两种选项:
| 输出方式 | 规则描述 | 输出结果 | 空匹配/未匹配行处理逻辑 |
|---|---|---|---|
| ONE ROW PER MATCH | 每一次成功匹配,产生一行输出结果。 | * PARTITION BY 子句中的列* MEASURES 子句中定义的表达式。 | 输出空匹配;跳过未匹配行。 |
| ALL ROWS PER MATCH | 每一次匹配中的每一行都将产生一条输出记录,除非该行通过 exclusion 语法排除。 | * PARTITION BY 子句中的列* ORDER BY 子句中的列* MEASURES 子句中定义的表达式* 输入表中的其余列 | * 默认:输出空匹配;跳过未匹配行。* ALL ROWS PER MATCHSHOW EMPTY MATCHES:默认输出空匹配,跳过未匹配行* ALL ROWS PER MATCHOMIT EMPTY MATCHES:不输出空匹配,跳过未匹配行* ALL ROWS PER MATCHWITH UNMATCHED ROWS:输出空匹配,并为每一条未匹配行额外生成一条输出记录 |
1.2.7 MEASURES 子句
用于指定从匹配到的一段数据中提取哪些信息。该子句为可选项,如果未显式指定,则根据 ROWS PER MATCH 子句的设置,部分输入列会成为模式识别的输出结果。
MEASURES measure_expression AS measure_name [, ...]measure_expression是根据匹配的一段数据计算出的标量值。
| 用法示例 | 说明 |
|---|---|
A.totalprice AS starting_price | 返回匹配分组中第一行(即与变量 A 关联的唯一一行)中的价格,作为起始价格。 |
RPR_LAST(B.totalprice) AS bottom_price | 返回与变量 B 关联的最后一行中的价格,代表“V”形模式中最低点的价格,对应下降区段的末尾。 |
RPR_LAST(U.totalprice) AS top_price | 返回匹配分组中的最高价格,对应变量 C 或 D 所关联的最后一行,即整个匹配分组的末尾。【假设 SUBSET U = (C, D)】 |
- 每个
measure_expression都会定义一个输出列,该列可通过其指定的measure_name进行引用。
1.2.8 模式查询表达式
在 MEASURES 与 DEFINE 子句中使用的表达式为标量表达式,用于在输入表的行级上下文中求值。标量表达式除了支持标准 SQL 语法外,还支持针对模式查询的特殊扩展函数。
1.2.8.1 模式变量引用
A.totalprice
U.orderdate
orderstatus- 当列名前缀为某基本模式变量或联合模式变量时,表示引用该变量所匹配的所有行的对应列值。
- 若列名不带前缀,则等同于使用“全局联合模式变量”(即所有基本模式变量的并集)作前缀,表示引用当前匹配中所有行的该列值。
不允许在模式识别表达式中使用表名作列名前缀。
1.2.8.2 扩展函数
| 函数名 | 函数式 | 描述 |
|---|---|---|
MATCH_NUMBER函数 | MATCH_NUMBER() | 返回当前匹配在分区内的序号,从 1 开始计数。空匹配与非空匹配一致,也占用匹配序号。 |
CLASSIFIER 函数 | CLASSIFIER(option) | 1. 返回当前行所映射的基本模式变量名称。1. option是一个可选参数:可以传入基本模式变量CLASSIFIER(A)或联合模式变量CLASSIFIER(U),用于限定函数作用范围,对于不在范围内的行,直接返回 NULL。在对联合模式变量使用时,可用于辨别该行究竟映射至并集中哪一个基本模式变量。 |
| 逻辑导航函数 | RPR_FIRST(expr, k) | 1. 表示从当前匹配分组中,定位至第一个满足 expr 的行,在此基础上再向分组尾部方向搜索到第 k 次出现的同一模式变量对应行,返回该行的指定列值。如果在指定方向上未能找到第 k 次匹配行,则函数返回 NULL。1. 其中 k 是可选参数,默认为 0,表示仅定位至首个满足条件的行;若显式指定,必须为非负整数。 |
| 逻辑导航函数 | RPR_LAST(expr, k) | 1. 表示从当前匹配分组中,定位至最后一个满足 expr 的行,在此基础上再向分组开头方向搜索到第 k 次出现的同一模式变量对应行,返回该行的指定列值。如果在指定方向上未能找到第 k 次匹配行,则函数返回 NULL。1. 其中 k 是可选参数,默认为 0,表示仅定位至末个满足条件的行;若显式指定,必须为非负整数。 |
| 物理导航函数 | PREV(expr, k) | 1. 表示从最后一次匹配至给定模式变量的行开始,向开头方向偏移 k 行,返回对应列值。若导航超出分区边界,则函数返回 NULL。1. 其中 k 是可选参数,默认为 1;若显式指定,必须为非负整数。 |
| 物理导航函数 | NEXT(expr, k) | 1. 表示从最后一次匹配至给定模式变量的行开始,向尾部方向偏移 k 行,返回对应列值。若导航超出分区边界,则函数返回 NULL。1. 其中 k 是可选参数,默认为 1;若显式指定,必须为非负整数。 |
| 聚合函数 | COUNT、SUM、AVG、MAX、MIN 函数 | 可用于对当前匹配中的数据进行计算。聚合函数与导航函数不允许互相嵌套。(V 2.0.6 版本起支持) |
| 嵌套函数 | PREV/NEXT(CLASSIFIER()) | 物理导航函数与 CLASSIFIER 函数嵌套。用于获取当前行的前一个和后一个匹配行所对应的模式变量 |
| 嵌套函数 | PREV/NEXT(RPR_FIRST/RPR_LAST(expr, k)) | 物理函数内部允许嵌套逻辑函数,逻辑函数内部不允许嵌套物理函数。用于先进行逻辑偏移,再进行物理偏移。 |
示例说明
- CLASSIFIER 函数
- 查询 sql
SELECT m.time, m.match, m.price, m.lower_or_higher, m.label
FROM t
MATCH_RECOGNIZE (
ORDER BY time
MEASURES
MATCH_NUMBER() AS match,
RUNNING RPR_LAST(totalprice) AS price,
CLASSIFIER(U) AS lower_or_higher,
CLASSIFIER(W) AS label
ALL ROWS PER MATCH
PATTERN ((L | H) A)
SUBSET
U = (L, H),
W = (A, L, H)
DEFINE
A AS A.totalprice = 80,
L AS L.totalprice < 80,
H AS H.totalprice > 80
) AS m;分析过程
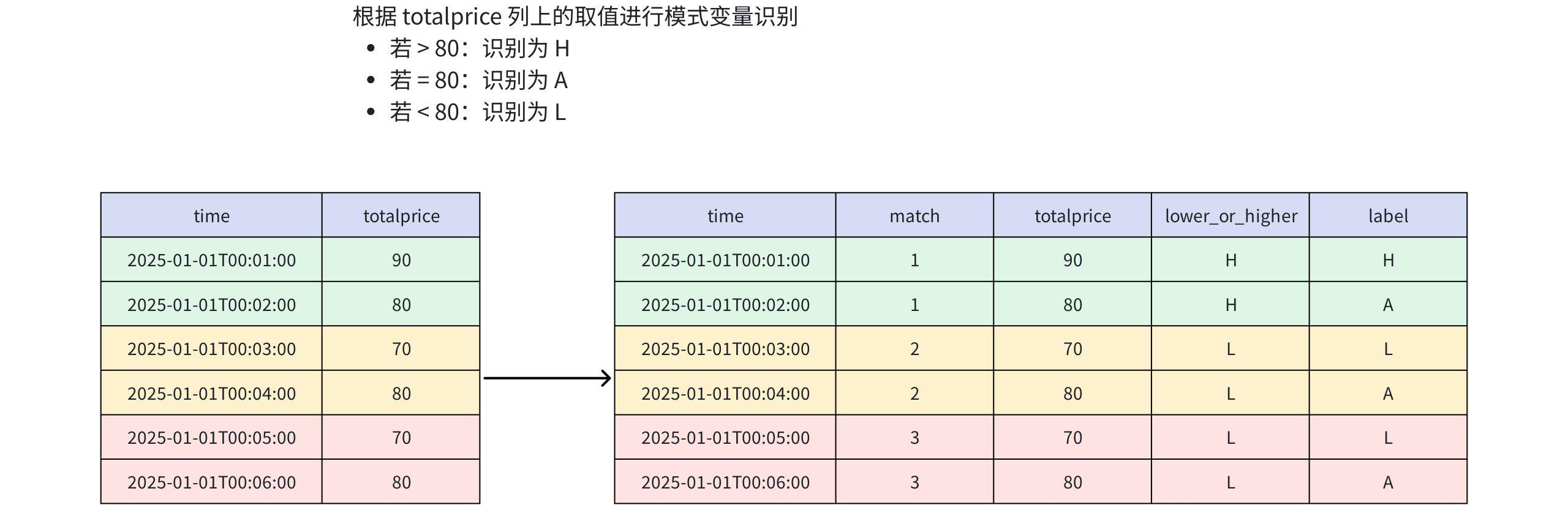
查询结果
+-----------------------------+-----+-----+---------------+-----+
| time|match|price|lower_or_higher|label|
+-----------------------------+-----+-----+---------------+-----+
|2025-01-01T00:01:00.000+08:00| 1| 90| H| H|
|2025-01-01T00:02:00.000+08:00| 1| 80| H| A|
|2025-01-01T00:03:00.000+08:00| 2| 70| L| L|
|2025-01-01T00:04:00.000+08:00| 2| 80| L| A|
|2025-01-01T00:05:00.000+08:00| 3| 70| L| L|
|2025-01-01T00:06:00.000+08:00| 3| 80| L| A|
+-----------------------------+-----+-----+---------------+-----+
Total line number = 6- 逻辑导航函数
- 查询 sql
SELECT m.time, m.measure
FROM t
MATCH_RECOGNIZE (
ORDER BY time
MEASURES
%s AS measure -- MEASURES 子句
ALL ROWS PER MATCH
PATTERN (A+)
DEFINE A AS true
) AS m;查询结果
- 当取值为 totalprice、RPR_LAST(totalprice)、RUNNING RPR_LAST(totalprice) 时
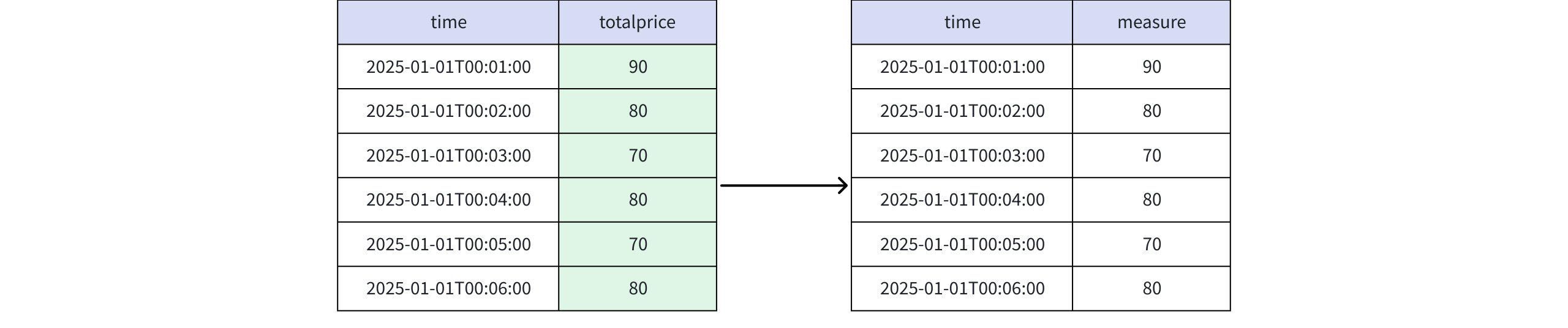
实际返回
+-----------------------------+-------+ | time|measure| +-----------------------------+-------+ |2025-01-01T00:01:00.000+08:00| 90| |2025-01-01T00:02:00.000+08:00| 80| |2025-01-01T00:03:00.000+08:00| 70| |2025-01-01T00:04:00.000+08:00| 80| |2025-01-01T00:05:00.000+08:00| 70| |2025-01-01T00:06:00.000+08:00| 80| +-----------------------------+-------+ Total line number = 6- 当取值为 FINAL RPR_LAST(totalprice) 时
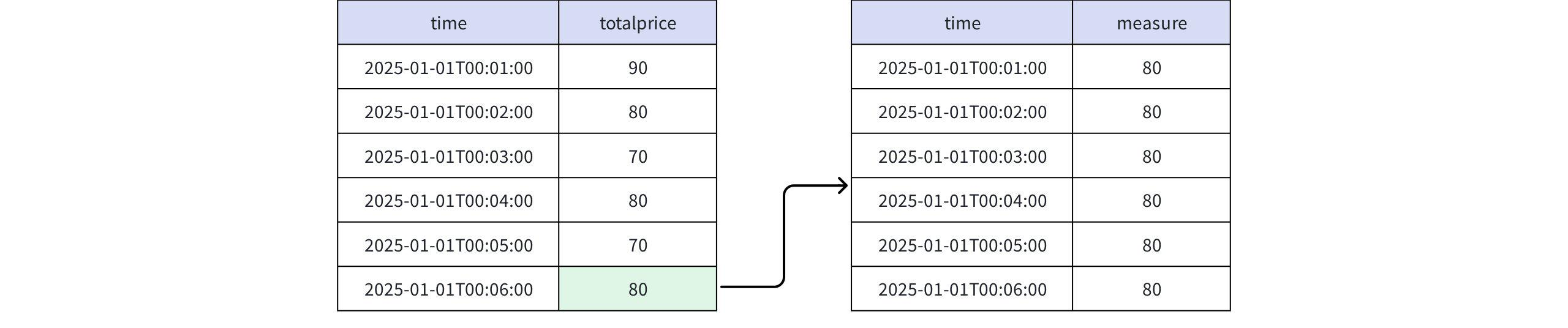
实际返回
+-----------------------------+-------+ | time|measure| +-----------------------------+-------+ |2025-01-01T00:01:00.000+08:00| 80| |2025-01-01T00:02:00.000+08:00| 80| |2025-01-01T00:03:00.000+08:00| 80| |2025-01-01T00:04:00.000+08:00| 80| |2025-01-01T00:05:00.000+08:00| 80| |2025-01-01T00:06:00.000+08:00| 80| +-----------------------------+-------+ Total line number = 6- 当取值为 RPR_FIRST(totalprice)、 RUNNING RPR_FIRST(totalprice)、FINAL RPR_FIRST(totalprice)时
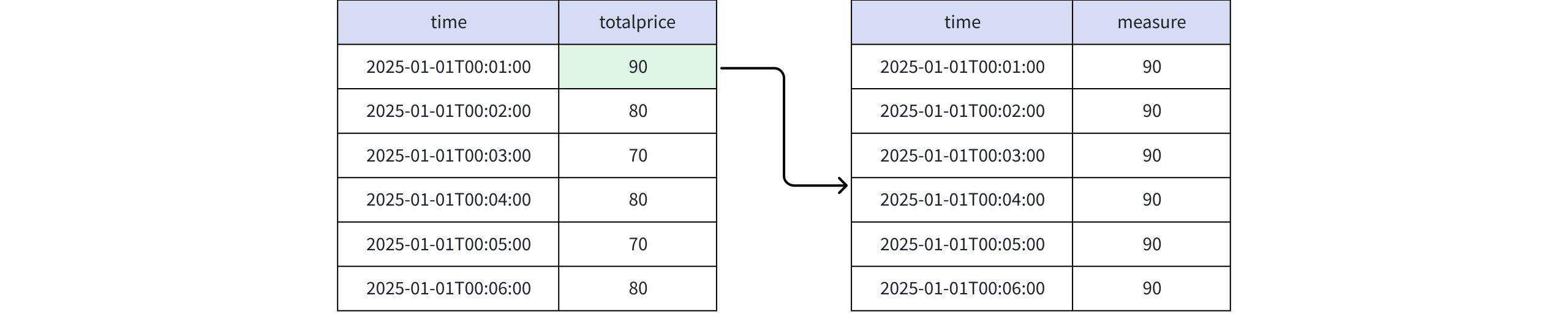
实际返回
+-----------------------------+-------+ | time|measure| +-----------------------------+-------+ |2025-01-01T00:01:00.000+08:00| 90| |2025-01-01T00:02:00.000+08:00| 90| |2025-01-01T00:03:00.000+08:00| 90| |2025-01-01T00:04:00.000+08:00| 90| |2025-01-01T00:05:00.000+08:00| 90| |2025-01-01T00:06:00.000+08:00| 90| +-----------------------------+-------+ Total line number = 6- 当取值为 RPR_LAST(totalprice, 2) 时
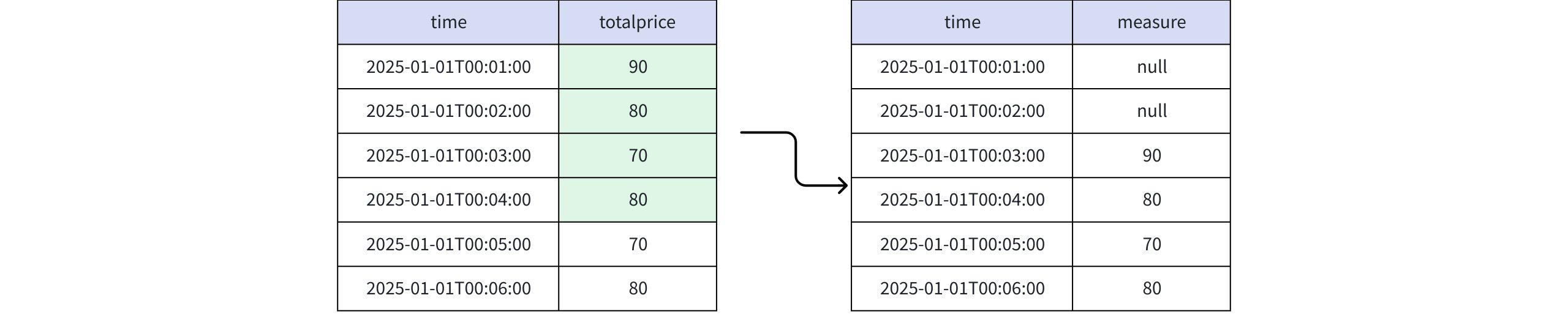
实际返回
+-----------------------------+-------+ | time|measure| +-----------------------------+-------+ |2025-01-01T00:01:00.000+08:00| null| |2025-01-01T00:02:00.000+08:00| null| |2025-01-01T00:03:00.000+08:00| 90| |2025-01-01T00:04:00.000+08:00| 80| |2025-01-01T00:05:00.000+08:00| 70| |2025-01-01T00:06:00.000+08:00| 80| +-----------------------------+-------+ Total line number = 6- 当取值为 FINAL RPP_LAST(totalprice, 2) 时
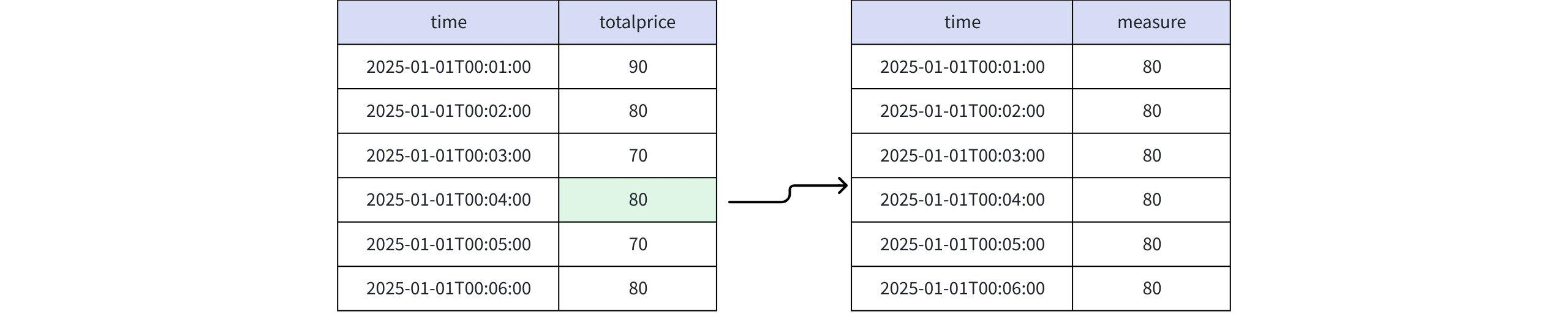
实际返回
+-----------------------------+-------+ | time|measure| +-----------------------------+-------+ |2025-01-01T00:01:00.000+08:00| 80| |2025-01-01T00:02:00.000+08:00| 80| |2025-01-01T00:03:00.000+08:00| 80| |2025-01-01T00:04:00.000+08:00| 80| |2025-01-01T00:05:00.000+08:00| 80| |2025-01-01T00:06:00.000+08:00| 80| +-----------------------------+-------+ Total line number = 6- 当取值为 RPR_FIRST(totalprice, 2) 和 FINAL RPR_FIRST(totalprice, 2) 时
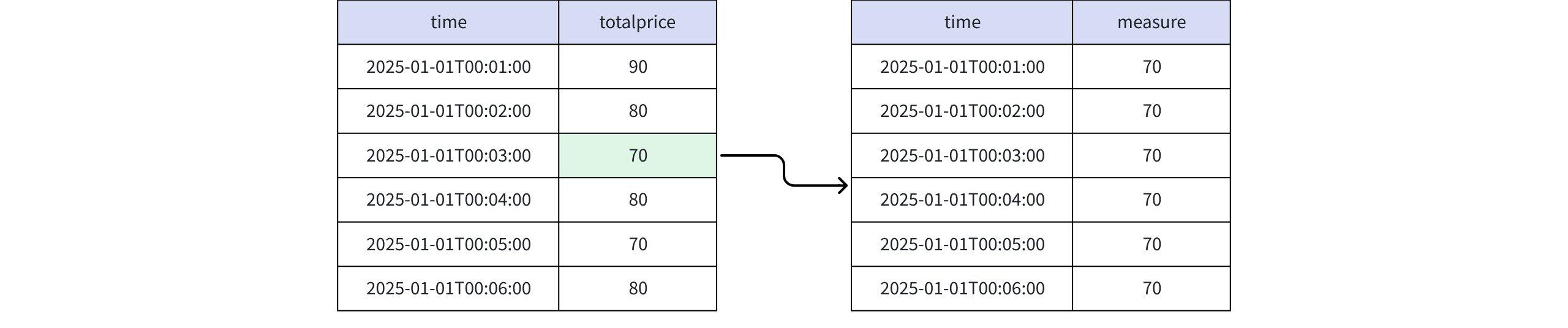
实际返回
+-----------------------------+-------+ | time|measure| +-----------------------------+-------+ |2025-01-01T00:01:00.000+08:00| 70| |2025-01-01T00:02:00.000+08:00| 70| |2025-01-01T00:03:00.000+08:00| 70| |2025-01-01T00:04:00.000+08:00| 70| |2025-01-01T00:05:00.000+08:00| 70| |2025-01-01T00:06:00.000+08:00| 70| +-----------------------------+-------+ Total line number = 6
- 物理导航函数
- 查询 sql
SELECT m.time, m.measure
FROM t
MATCH_RECOGNIZE (
ORDER BY time
MEASURES
%s AS measure -- MEASURES 子句
ALL ROWS PER MATCH
PATTERN (B)
DEFINE B AS B.totalprice >= PREV(B.totalprice)
) AS m;查询结果
- 当取值为
PREV(totalprice)时
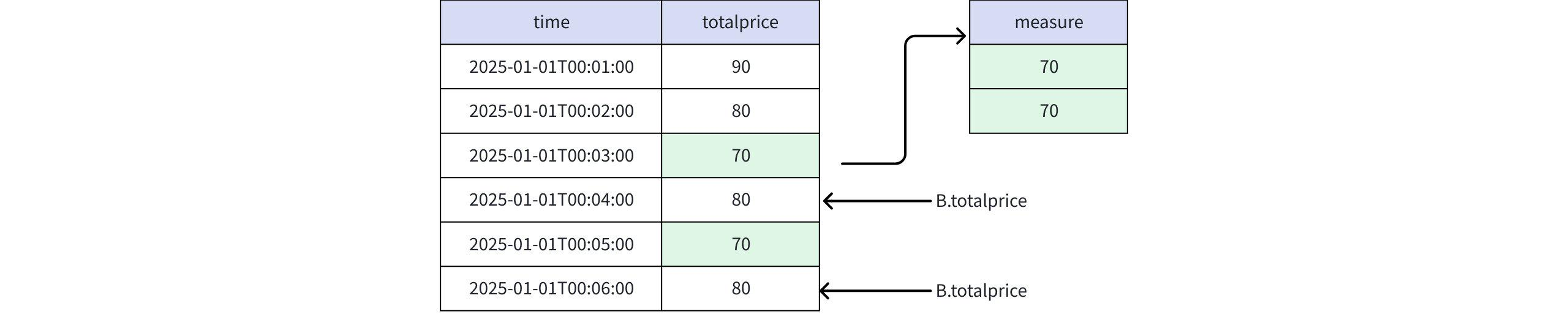
实际返回
+-----------------------------+-------+ | time|measure| +-----------------------------+-------+ |2025-01-01T00:04:00.000+08:00| 70| |2025-01-01T00:06:00.000+08:00| 70| +-----------------------------+-------+ Total line number = 2- 当取值为
PREV(B.totalprice, 2)时
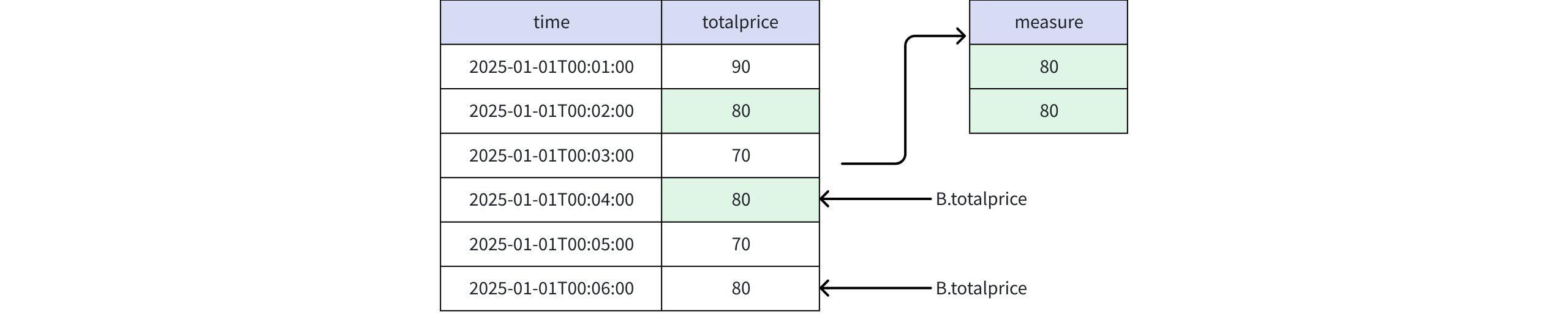
实际返回
+-----------------------------+-------+ | time|measure| +-----------------------------+-------+ |2025-01-01T00:04:00.000+08:00| 80| |2025-01-01T00:06:00.000+08:00| 80| +-----------------------------+-------+ Total line number = 2- 当取值为
PREV(B.totalprice, 4)时
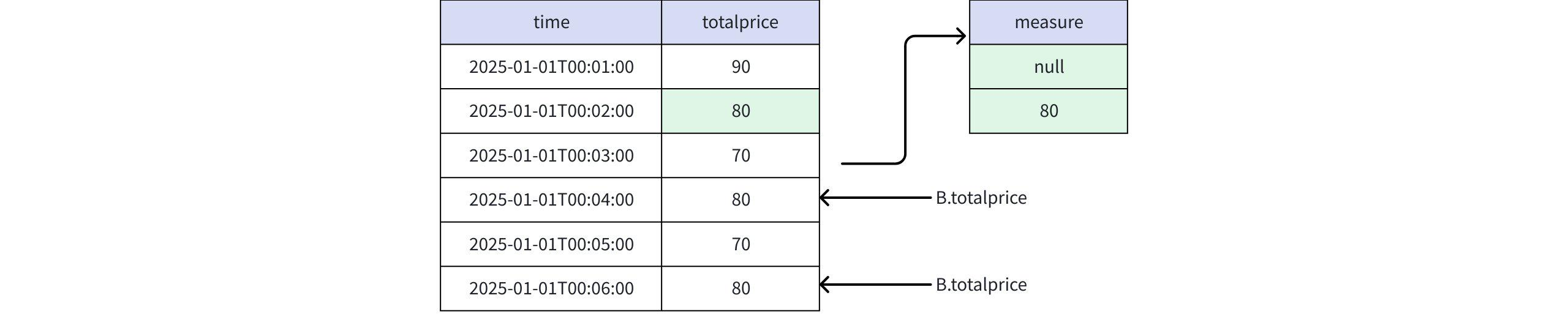
实际返回
+-----------------------------+-------+ | time|measure| +-----------------------------+-------+ |2025-01-01T00:04:00.000+08:00| null| |2025-01-01T00:06:00.000+08:00| 80| +-----------------------------+-------+ Total line number = 2- 当取值为
NEXT(totalprice)或NEXT(B.totalprice, 1)时

实际返回
+-----------------------------+-------+ | time|measure| +-----------------------------+-------+ |2025-01-01T00:04:00.000+08:00| 70| |2025-01-01T00:06:00.000+08:00| null| +-----------------------------+-------+ Total line number = 2当取值为 NEXT(B.totalprice, 2)时

实际返回
+-----------------------------+-------+ | time|measure| +-----------------------------+-------+ |2025-01-01T00:04:00.000+08:00| 80| |2025-01-01T00:06:00.000+08:00| null| +-----------------------------+-------+ Total line number = 2- 当取值为
- 聚合函数
- 查询 sql
SELECT m.time, m.count, m.avg, m.sum, m.min, m.max
FROM t
MATCH_RECOGNIZE (
ORDER BY time
MEASURES
COUNT(*) AS count,
AVG(totalprice) AS avg,
SUM(totalprice) AS sum,
MIN(totalprice) AS min,
MAX(totalprice) AS max
ALL ROWS PER MATCH
PATTERN (A+)
DEFINE A AS true
) AS m;- 分析过程(以 MIN(totalprice)为例)
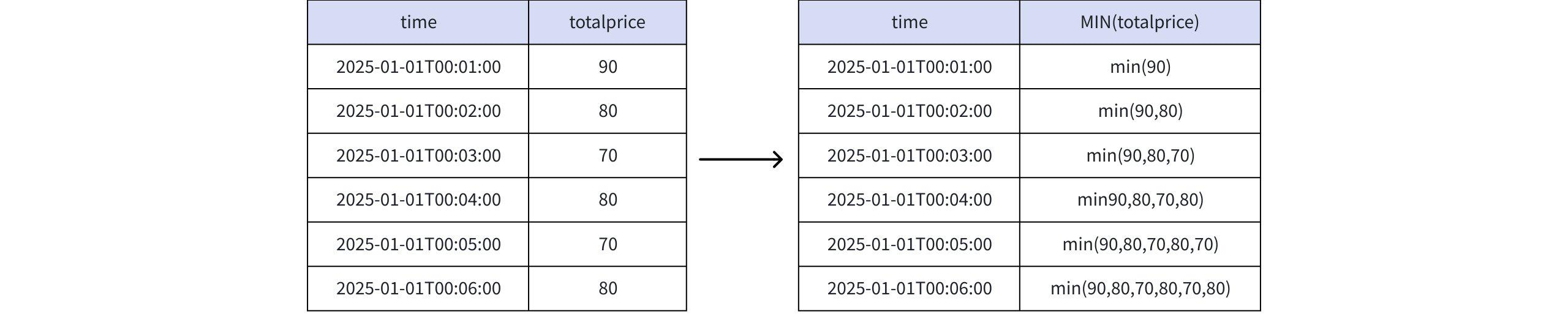
- 查询结果
+-----------------------------+-----+-----------------+-----+---+---+
| time|count| avg| sum|min|max|
+-----------------------------+-----+-----------------+-----+---+---+
|2025-01-01T00:01:00.000+08:00| 1| 90.0| 90.0| 90| 90|
|2025-01-01T00:02:00.000+08:00| 2| 85.0|170.0| 80| 90|
|2025-01-01T00:03:00.000+08:00| 3| 80.0|240.0| 70| 90|
|2025-01-01T00:04:00.000+08:00| 4| 80.0|320.0| 70| 90|
|2025-01-01T00:05:00.000+08:00| 5| 78.0|390.0| 70| 90|
|2025-01-01T00:06:00.000+08:00| 6|78.33333333333333|470.0| 70| 90|
+-----------------------------+-----+-----------------+-----+---+---+
Total line number = 6- 嵌套函数
示例一
- 查询 sql
SELECT m.time, m.match, m.price, m.lower_or_higher, m.label, m.prev_label, m.next_label
FROM t
MATCH_RECOGNIZE (
ORDER BY time
MEASURES
MATCH_NUMBER() AS match,
RUNNING RPR_LAST(totalprice) AS price,
CLASSIFIER(U) AS lower_or_higher,
CLASSIFIER(W) AS label,
PREV(CLASSIFIER(W)) AS prev_label,
NEXT(CLASSIFIER(W)) AS next_label
ALL ROWS PER MATCH
PATTERN ((L | H) A)
SUBSET
U = (L, H),
W = (A, L, H)
DEFINE
A AS A.totalprice = 80,
L AS L.totalprice < 80,
H AS H.totalprice > 80
) AS m;- 分析过程
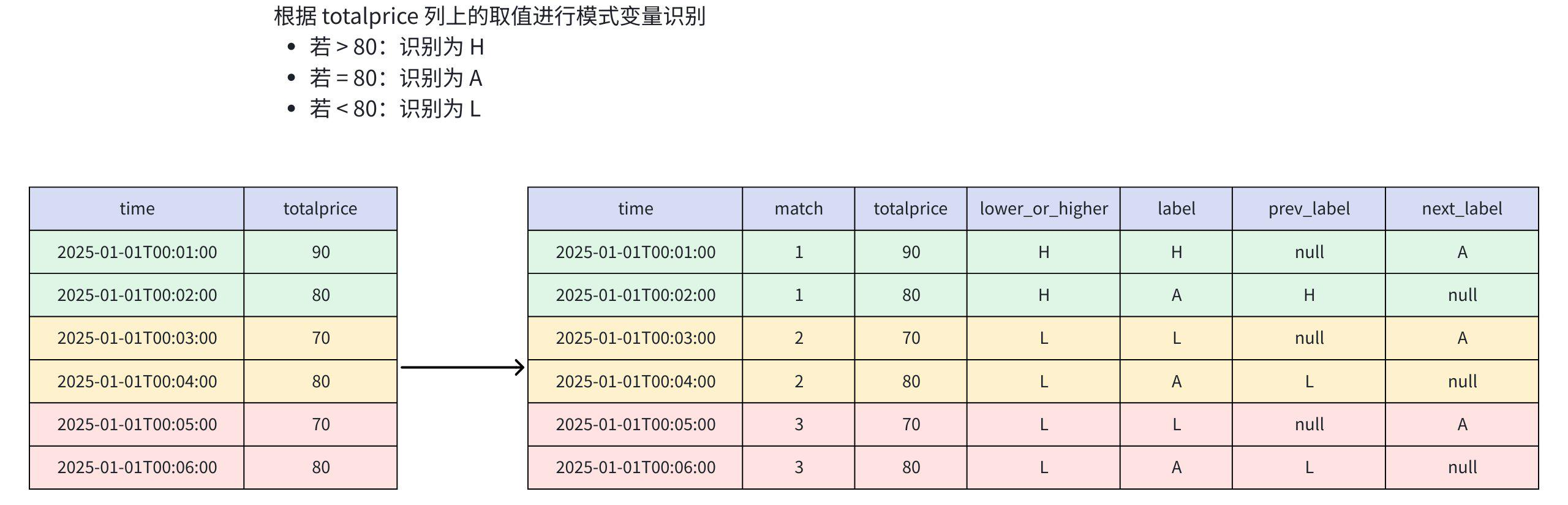
- 查询结果
+-----------------------------+-----+-----+---------------+-----+----------+----------+
| time|match|price|lower_or_higher|label|prev_label|next_label|
+-----------------------------+-----+-----+---------------+-----+----------+----------+
|2025-01-01T00:01:00.000+08:00| 1| 90| H| H| null| A|
|2025-01-01T00:02:00.000+08:00| 1| 80| H| A| H| null|
|2025-01-01T00:03:00.000+08:00| 2| 70| L| L| null| A|
|2025-01-01T00:04:00.000+08:00| 2| 80| L| A| L| null|
|2025-01-01T00:05:00.000+08:00| 3| 70| L| L| null| A|
|2025-01-01T00:06:00.000+08:00| 3| 80| L| A| L| null|
+-----------------------------+-----+-----+---------------+-----+----------+----------+
Total line number = 6示例二
- 查询 sql
SELECT m.time, m.prev_last_price, m.next_first_price
FROM t
MATCH_RECOGNIZE (
ORDER BY time
MEASURES
PREV(RPR_LAST(totalprice), 2) AS prev_last_price,
NEXT(RPR_FIRST(totalprice), 2) as next_first_price
ALL ROWS PER MATCH
PATTERN (A+)
DEFINE A AS true
) AS m;- 分析过程
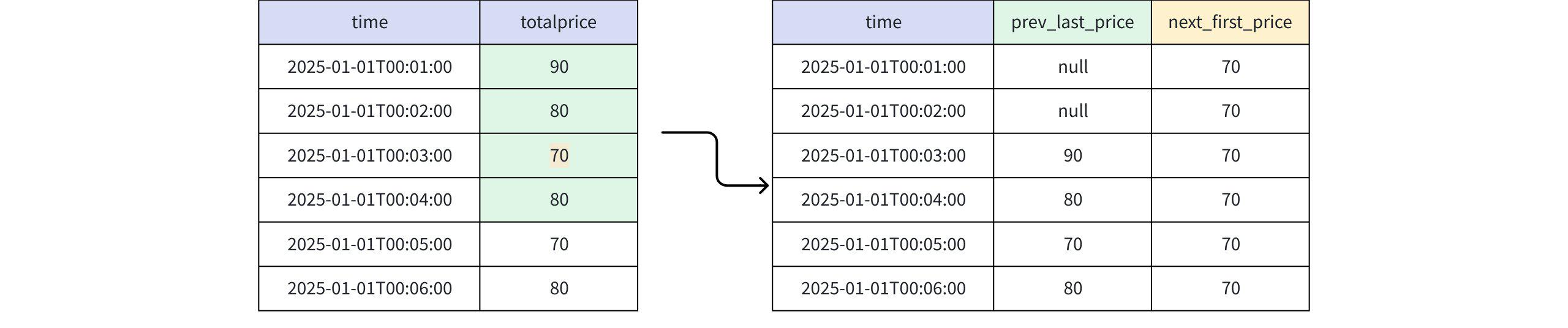
- 查询结果
+-----------------------------+---------------+----------------+
| time|prev_last_price|next_first_price|
+-----------------------------+---------------+----------------+
|2025-01-01T00:01:00.000+08:00| null| 70|
|2025-01-01T00:02:00.000+08:00| null| 70|
|2025-01-01T00:03:00.000+08:00| 90| 70|
|2025-01-01T00:04:00.000+08:00| 80| 70|
|2025-01-01T00:05:00.000+08:00| 70| 70|
|2025-01-01T00:06:00.000+08:00| 80| 70|
+-----------------------------+---------------+----------------+
Total line number = 61.2.8.3 RUNNING 和 FINAL 语义
- 定义
RUNNING: 表示计算范围为当前匹配分组内,从分组的起始行到当前正在处理的行(即到当前行为止)。FINAL: 表示计算范围为当前匹配分组内,从分组的起始行到分组的最终行(即整个匹配分组)。
- 作用范围
- DEFINE 子句默认采用 RUNNING 语义。
- MEASURES 子句默认采用 RUNNING 语义,支持指定 FINAL 语义。当采用 ONE ROW PER MATCH 输出模式时,所有表达式都从匹配分组的末行位置进行计算,此时 RUNNING 语义与 FINAL 语义等价。
- 语法约束
- RUNNING 和 FINAL 需要写在逻辑导航函数或聚合函数之前,不能直接作用于列引用。
- 合法:
RUNNING RPP_LAST(A.totalprice)、FINAL RPP_LAST(A.totalprice) - 非法:
RUNNING A.totalprice、FINAL A.totalprice、RUNNING PREV(A.totalprice)
- 合法:
1.3 场景示例
以示例数据为源数据
1.3.1 时间分段查询
将 table1 中的数据按照时间间隔小于等于 24 小时分段,查询每段中的数据总条数,以及开始、结束时间。
查询SQL
SELECT start_time, end_time, cnt
FROM table1
MATCH_RECOGNIZE (
ORDER BY time
MEASURES
RPR_FIRST(A.time) AS start_time,
RPR_LAST(time) AS end_time,
COUNT() AS cnt
PATTERN (A B*)
DEFINE B AS (cast(B.time as INT64) - cast(PREV(B.time) as INT64)) <= 86400000
) AS m查询结果
+-----------------------------+-----------------------------+---+
| start_time| end_time|cnt|
+-----------------------------+-----------------------------+---+
|2024-11-26T13:37:00.000+08:00|2024-11-26T13:38:00.000+08:00| 2|
|2024-11-27T16:38:00.000+08:00|2024-11-30T14:30:00.000+08:00| 16|
+-----------------------------+-----------------------------+---+
Total line number = 21.3.2 差值分段查询
将 table2 中的数据按照 humidity 湿度值差值小于 0.1 分段,查询每段中的数据总条数,以及开始、结束时间。
- 查询sql
SELECT start_time, end_time, cnt
FROM table2
MATCH_RECOGNIZE (
ORDER BY time
MEASURES
RPR_FIRST(A.time) AS start_time,
RPR_LAST(time) AS end_time,
COUNT() AS cnt
PATTERN (A B*)
DEFINE B AS (B.humidity - PREV(B.humidity )) <=0.1
) AS m;- 查询结果
+-----------------------------+-----------------------------+---+
| start_time| end_time|cnt|
+-----------------------------+-----------------------------+---+
|2024-11-26T13:37:00.000+08:00|2024-11-27T00:00:00.000+08:00| 2|
|2024-11-28T08:00:00.000+08:00|2024-11-29T00:00:00.000+08:00| 2|
|2024-11-29T11:00:00.000+08:00|2024-11-30T00:00:00.000+08:00| 2|
+-----------------------------+-----------------------------+---+
Total line number = 31.3.3 事件统计查询
将 table1 中数据按照设备号分组,统计上海地区湿度大于 35 的开始、结束时间及最大湿度值。
- 查询sql
SELECT m.device_id, m.match, m.event_start, m.event_end, m.max_humidity
FROM table1
MATCH_RECOGNIZE (
PARTITION BY device_id
ORDER BY time
MEASURES
MATCH_NUMBER() AS match,
RPR_FIRST(A.time) AS event_start,
RPR_LAST(A.time) AS event_end,
MAX(A.humidity) AS max_humidity
ONE ROW PER MATCH
PATTERN (A+)
DEFINE
A AS A.region= '上海' AND A.humidity> 35
) AS m- 查询结果
+---------+-----+-----------------------------+-----------------------------+------------+
|device_id|match| event_start| event_end|max_humidity|
+---------+-----+-----------------------------+-----------------------------+------------+
| 100| 1|2024-11-28T09:00:00.000+08:00|2024-11-29T18:30:00.000+08:00| 45.1|
| 101| 1|2024-11-30T09:30:00.000+08:00|2024-11-30T09:30:00.000+08:00| 35.2|
+---------+-----+-----------------------------+-----------------------------+------------+
Total line number = 22. 窗口函数
2.1 功能介绍
窗口函数(Window Function) 是一种基于与当前行相关的特定行集合(称为“窗口”) 对每一行进行计算的特殊函数。它将分组操作(PARTITION BY)、排序(ORDER BY)与可定义的计算范围(窗口框架 FRAME)结合,在不折叠原始数据行的前提下实现复杂的跨行计算。常用于数据分析场景,比如排名、累计和、移动平均等操作。
注意:该功能从 V 2.0.5 版本开始提供。
例如,某场景下需要查询不同设备的功耗累加值,即可通过窗口函数来实现。
-- 原始数据
+-----------------------------+------+-----+
| time|device| flow|
+-----------------------------+------+-----+
|1970-01-01T08:00:00.000+08:00| d0| 3|
|1970-01-01T08:00:00.001+08:00| d0| 5|
|1970-01-01T08:00:00.002+08:00| d0| 3|
|1970-01-01T08:00:00.003+08:00| d0| 1|
|1970-01-01T08:00:00.004+08:00| d1| 2|
|1970-01-01T08:00:00.005+08:00| d1| 4|
+-----------------------------+------+-----+
-- 创建表并插入数据
CREATE TABLE device_flow(device String tag, flow INT32 FIELD);
insert into device_flow(time, device ,flow ) values ('1970-01-01T08:00:00.000+08:00','d0',3),('1970-01-01T08:00:01.000+08:00','d0',5),('1970-01-01T08:00:02.000+08:00','d0',3),('1970-01-01T08:00:03.000+08:00','d0',1),('1970-01-01T08:00:04.000+08:00','d1',2),('1970-01-01T08:00:05.000+08:00','d1',4);
--执行窗口函数查询
SELECT *, sum(flow) OVER(PARTITION BY device ORDER BY flow) as sum FROM device_flow;经过分组、排序、计算(步骤拆解如下图所示),
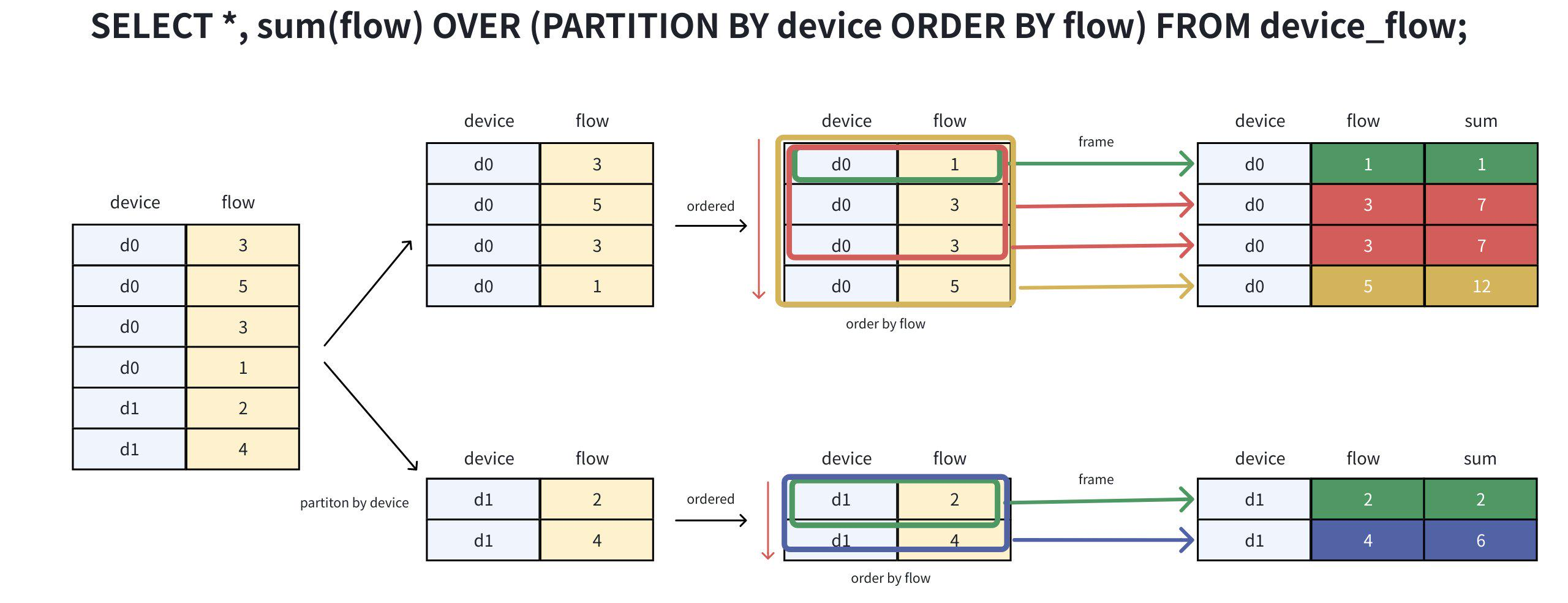
即可得到期望结果:
+-----------------------------+------+----+----+
| time|device|flow| sum|
+-----------------------------+------+----+----+
|1970-01-01T08:00:04.000+08:00| d1| 2| 2.0|
|1970-01-01T08:00:05.000+08:00| d1| 4| 6.0|
|1970-01-01T08:00:03.000+08:00| d0| 1| 1.0|
|1970-01-01T08:00:00.000+08:00| d0| 3| 7.0|
|1970-01-01T08:00:02.000+08:00| d0| 3| 7.0|
|1970-01-01T08:00:01.000+08:00| d0| 5|12.0|
+-----------------------------+------+----+----+2.2 功能定义
2.2.1 SQL 定义
windowDefinition
: name=identifier AS '(' windowSpecification ')'
;
windowSpecification
: (existingWindowName=identifier)?
(PARTITION BY partition+=expression (',' partition+=expression)*)?
(ORDER BY sortItem (',' sortItem)*)?
windowFrame?
;
windowFrame
: frameExtent
;
frameExtent
: frameType=RANGE start=frameBound
| frameType=ROWS start=frameBound
| frameType=GROUPS start=frameBound
| frameType=RANGE BETWEEN start=frameBound AND end=frameBound
| frameType=ROWS BETWEEN start=frameBound AND end=frameBound
| frameType=GROUPS BETWEEN start=frameBound AND end=frameBound
;
frameBound
: UNBOUNDED boundType=PRECEDING #unboundedFrame
| UNBOUNDED boundType=FOLLOWING #unboundedFrame
| CURRENT ROW #currentRowBound
| expression boundType=(PRECEDING | FOLLOWING) #boundedFrame
;2.2.2 窗口定义
2.2.2.1 Partition
PARTITION BY 用于将数据分为多个独立、不相关的「组」,窗口函数只能访问并操作其所属分组内的数据,无法访问其它分组。该子句是可选的;如果未显式指定,则默认将所有数据分到同一组。值得注意的是,与 GROUP BY 通过聚合函数将一组数据规约成一行不同,PARTITION BY 的窗口函数并不会影响组内的行数。
- 示例
查询语句:
IoTDB> SELECT *, count(flow) OVER (PARTITION BY device) as count FROM device_flow;拆解步骤:
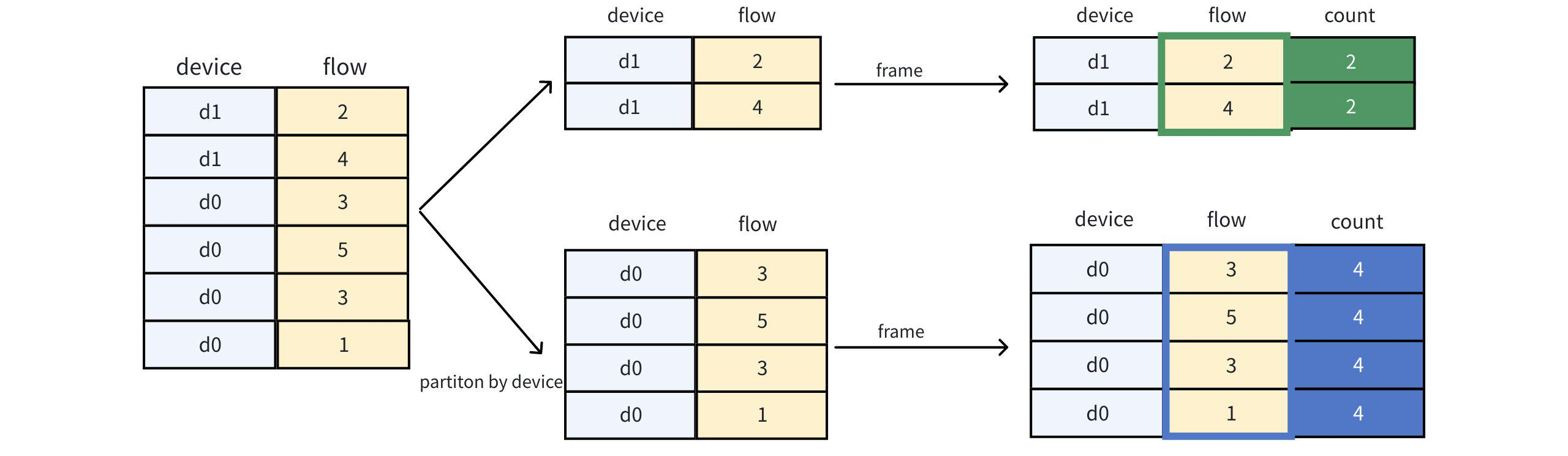
查询结果:
+-----------------------------+------+----+-----+
| time|device|flow|count|
+-----------------------------+------+----+-----+
|1970-01-01T08:00:04.000+08:00| d1| 2| 2|
|1970-01-01T08:00:05.000+08:00| d1| 4| 2|
|1970-01-01T08:00:00.000+08:00| d0| 3| 4|
|1970-01-01T08:00:01.000+08:00| d0| 5| 4|
|1970-01-01T08:00:02.000+08:00| d0| 3| 4|
|1970-01-01T08:00:03.000+08:00| d0| 1| 4|
+-----------------------------+------+----+-----+2.2.2.2 Ordering
ORDER BY 用于对 partition 内的数据进行排序。排序后,相等的行被称为 peers。peers 会影响窗口函数的行为,例如不同 rank function 对 peers 的处理不同;不同 frame 的划分方式对于 peers 的处理也不同。该子句是可选的。
- 示例
查询语句:
IoTDB> SELECT *, rank() OVER (PARTITION BY device ORDER BY flow) as rank FROM device_flow;拆解步骤:
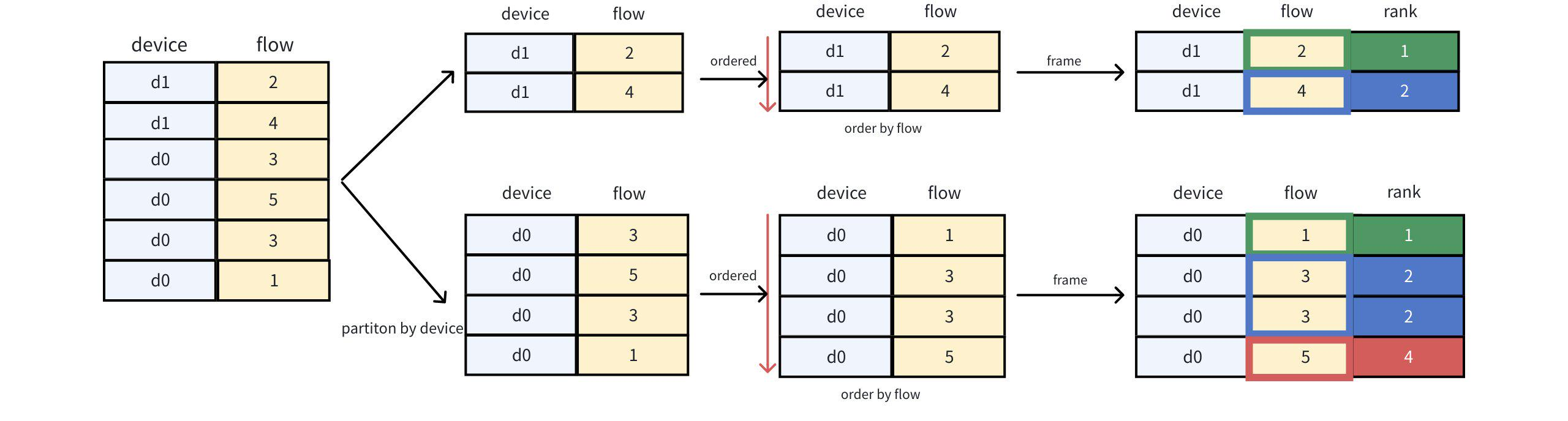
查询结果:
+-----------------------------+------+----+----+
| time|device|flow|rank|
+-----------------------------+------+----+----+
|1970-01-01T08:00:04.000+08:00| d1| 2| 1|
|1970-01-01T08:00:05.000+08:00| d1| 4| 2|
|1970-01-01T08:00:03.000+08:00| d0| 1| 1|
|1970-01-01T08:00:00.000+08:00| d0| 3| 2|
|1970-01-01T08:00:02.000+08:00| d0| 3| 2|
|1970-01-01T08:00:01.000+08:00| d0| 5| 4|
+-----------------------------+------+----+----+2.2.2.3 Framing
对于 partition 中的每一行,窗口函数都会在相应的一组行上求值,这些行称为 Frame(即 Window Function 在每一行上的输入域)。Frame 可以手动指定,指定时涉及两个属性,具体说明如下。
| Frame 属性 | 属性值 | 值描述 |
|---|---|---|
| 类型 | ROWS | 通过行号来划分 frame |
| GROUPS | 通过 peers 来划分 frame,即值相同的行视为同等的存在。peers 中所有的行分为一个组,叫做 peer group | |
| RANGE | 通过值来划分 frame | |
| 起始和终止位置 | UNBOUNDED PRECEDING | 整个 partition 的第一行 |
| offset PRECEDING | 代表前面和当前行「距离」为 offset 的行 | |
| CURRENT ROW | 当前行 | |
| offset FOLLOWING | 代表后面和当前行「距离」为 offset 的行 | |
| UNBOUNDED FOLLOWING | 整个 partition 的最后一行 |
其中,CURRENT ROW、PRECEDING N 和 FOLLOWING N 的含义随着 frame 种类的不同而不同,如下表所示:
ROWS | GROUPS | RANGE | |
|---|---|---|---|
CURRENT ROW | 当前行 | 由于 peer group 包含多行,因此这个选项根据作用于 frame_start 和 frame_end 而不同:* frame_start:peer group 的第一行;* frame_end:peer group 的最后一行。 | 和 GROUPS 相同,根据作用于 frame_start 和 frame_end 而不同:* frame_start:peer group 的第一行;* frame_end:peer group 的最后一行。 |
offset PRECEDING | 前 offset 行 | 前 offset 个 peer group; | 前面与当前行的值之差小于等于 offset 就分为一个 frame |
offset FOLLOWING | 后 offset 行 | 后 offset 个 peer group。 | 后面与当前行的值之差小于等于 offset 就分为一个 frame |
语法格式如下:
-- 同时指定 frame_start 和 frame_end
{ RANGE | ROWS | GROUPS } BETWEEN frame_start AND frame_end
-- 仅指定 frame_start,frame_end 为 CURRENT ROW
{ RANGE | ROWS | GROUPS } frame_start若未手动指定 Frame,Frame 的默认划分规则如下:
- 当窗口函数使用 ORDER BY 时:默认 Frame 为 RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW (即从窗口的第一行到当前行)。例如:RANK() OVER(PARTITION BY COL1 0RDER BY COL2) 中,Frame 默认包含分区内当前行及之前的所有行。
- 当窗口函数不使用 ORDER BY 时:默认 Frame 为 RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING (即整个窗口的所有行)。例如:AVG(COL2) OVER(PARTITION BY col1) 中,Frame 默认包含分区内的所有行,计算整个分区的平均值。
需要注意的是,当 Frame 类型为 GROUPS 或 RANGE 时,需要指定 ORDER BY,区别在于 GROUPS 中的 ORDER BY 可以涉及多个字段,而 RANGE 需要计算,所以只能指定一个字段。
- 示例
- Frame 类型为 ROWS
查询语句:
IoTDB> SELECT *, count(flow) OVER(PARTITION BY device ROWS 1 PRECEDING) as count FROM device_flow;拆解步骤:
- 取前一行和当前行作为 Frame
- 对于 partition 的第一行,由于没有前一行,所以整个 Frame 只有它一行,返回 1;
- 对于 partition 的其他行,整个 Frame 包含当前行和它的前一行,返回 2:

查询结果:
+-----------------------------+------+----+-----+
| time|device|flow|count|
+-----------------------------+------+----+-----+
|1970-01-01T08:00:04.000+08:00| d1| 2| 1|
|1970-01-01T08:00:05.000+08:00| d1| 4| 2|
|1970-01-01T08:00:00.000+08:00| d0| 3| 1|
|1970-01-01T08:00:01.000+08:00| d0| 5| 2|
|1970-01-01T08:00:02.000+08:00| d0| 3| 2|
|1970-01-01T08:00:03.000+08:00| d0| 1| 2|
+-----------------------------+------+----+-----+- Frame 类型为 GROUPS
查询语句:
IoTDB> SELECT *, count(flow) OVER(PARTITION BY device ORDER BY flow GROUPS BETWEEN 1 PRECEDING AND CURRENT ROW) as count FROM device_flow;拆解步骤:
- 取前一个 peer group 和当前 peer group 作为 Frame,那么以 device 为 d0 的 partition 为例(d1同理),对于 count 行数:
- 对于 flow 为 1 的 peer group,由于它也没比它小的 peer group 了,所以整个 Frame 就它一行,返回 1;
- 对于 flow 为 3 的 peer group,它本身包含 2 行,前一个 peer group 就是 flow 为 1 的,就一行,因此整个 Frame 三行,返回 3;
- 对于 flow 为 5 的 peer group,它本身包含 1 行,前一个 peer group 就是 flow 为 3 的,共两行,因此整个 Frame 三行,返回 3。

查询结果:
+-----------------------------+------+----+-----+
| time|device|flow|count|
+-----------------------------+------+----+-----+
|1970-01-01T08:00:04.000+08:00| d1| 2| 1|
|1970-01-01T08:00:05.000+08:00| d1| 4| 2|
|1970-01-01T08:00:03.000+08:00| d0| 1| 1|
|1970-01-01T08:00:00.000+08:00| d0| 3| 3|
|1970-01-01T08:00:02.000+08:00| d0| 3| 3|
|1970-01-01T08:00:01.000+08:00| d0| 5| 3|
+-----------------------------+------+----+-----+- Frame 类型为 RANGE
查询语句:
IoTDB> SELECT *,count(flow) OVER(PARTITION BY device ORDER BY flow RANGE BETWEEN 2 PRECEDING AND CURRENT ROW) as count FROM device_flow;拆解步骤:
- 把比当前行数据小于等于 2 的分为同一个 Frame,那么以 device 为 d0 的 partition 为例(d1 同理),对于 count 行数:
- 对于 flow 为 1 的行,由于它是最小的行了,所以整个 Frame 就它一行,返回 1;
- 对于 flow 为 3 的行,注意 CURRENT ROW 是作为 frame_end 存在,因此是整个 peer group 的最后一行,符合要求比它小的共 1 行,然后 peer group 有 2 行,所以整个 Frame 共 3 行,返回 3;
- 对于 flow 为 5 的行,它本身包含 1 行,符合要求的比它小的共 2 行,所以整个 Frame 共 3 行,返回 3。

查询结果:
+-----------------------------+------+----+-----+
| time|device|flow|count|
+-----------------------------+------+----+-----+
|1970-01-01T08:00:04.000+08:00| d1| 2| 1|
|1970-01-01T08:00:05.000+08:00| d1| 4| 2|
|1970-01-01T08:00:03.000+08:00| d0| 1| 1|
|1970-01-01T08:00:00.000+08:00| d0| 3| 3|
|1970-01-01T08:00:02.000+08:00| d0| 3| 3|
|1970-01-01T08:00:01.000+08:00| d0| 5| 3|
+-----------------------------+------+----+-----+2.3 内置的窗口函数
| 窗口函数分类 | 窗口函数名 | 函数定义 | 是否支持 FRAME 子句 |
|---|---|---|---|
| Aggregate Function | 所有内置聚合函数 | 对一组值进行聚合计算,得到单个聚合结果。 | 是 |
| Value Function | first_value | 返回 frame 的第一个值,如果指定了 IGNORE NULLS 需要跳过前缀的 NULL | 是 |
| last_value | 返回 frame 的最后一个值,如果指定了 IGNORE NULLS 需要跳过后缀的 NULL | 是 | |
| nth_value | 返回 frame 的第 n 个元素(注意 n 是从 1 开始),如果有 IGNORE NULLS 需要跳过 NULL | 是 | |
| lead | 返回当前行的后 offset 个元素(如果有 IGNORE NULLS 则 NULL 不考虑在内),如果没有这样的元素(超过 partition 范围),则返回 default | 否 | |
| lag | 返回当前行的前 offset 个元素(如果有 IGNORE NULLS 则 NULL 不考虑在内),如果没有这样的元素(超过 partition 范围),则返回 default | 否 | |
| Rank Function | rank | 返回当前行在整个 partition 中的序号,值相同的行序号相同,序号之间可能有 gap | 否 |
| dense_rank | 返回当前行在整个 partition 中的序号,值相同的行序号相同,序号之间没有 gap | 否 | |
| row_number | 返回当前行在整个 partition 中的行号,注意行号从 1 开始 | 否 | |
| percent_rank | 以百分比的形式,返回当前行的值在整个 partition 中的序号;即 (rank() - 1) / (n - 1),其中 n 是整个 partition 的行数 | 否 | |
| cume_dist | 以百分比的形式,返回当前行的值在整个 partition 中的序号;即 (小于等于它的行数) / n | 否 | |
| ntile | 指定 n,给每一行进行 1~n 的编号。 | 否 |
2.3.1 Aggregate Function
所有内置聚合函数,如 sum()、avg()、min()、max() 都能当作 Window Function 使用。
注意:与 GROUP BY 不同,Window Function 中每一行都有相应的输出
示例:
IoTDB> SELECT *, sum(flow) OVER (PARTITION BY device ORDER BY flow) as sum FROM device_flow;
+-----------------------------+------+----+----+
| time|device|flow| sum|
+-----------------------------+------+----+----+
|1970-01-01T08:00:04.000+08:00| d1| 2| 2.0|
|1970-01-01T08:00:05.000+08:00| d1| 4| 6.0|
|1970-01-01T08:00:03.000+08:00| d0| 1| 1.0|
|1970-01-01T08:00:00.000+08:00| d0| 3| 7.0|
|1970-01-01T08:00:02.000+08:00| d0| 3| 7.0|
|1970-01-01T08:00:01.000+08:00| d0| 5|12.0|
+-----------------------------+------+----+----+2.3.2 Value Function
first_value
- 函数名:
first_value(value) [IGNORE NULLS] - 定义:返回 frame 的第一个值,如果指定了 IGNORE NULLS 需要跳过前缀的 NULL;
- 示例:
IoTDB> SELECT *, first_value(flow) OVER w as first_value FROM device_flow WINDOW w AS (PARTITION BY device ORDER BY flow ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING);
+-----------------------------+------+----+-----------+
| time|device|flow|first_value|
+-----------------------------+------+----+-----------+
|1970-01-01T08:00:04.000+08:00| d1| 2| 2|
|1970-01-01T08:00:05.000+08:00| d1| 4| 2|
|1970-01-01T08:00:03.000+08:00| d0| 1| 1|
|1970-01-01T08:00:00.000+08:00| d0| 3| 1|
|1970-01-01T08:00:02.000+08:00| d0| 3| 3|
|1970-01-01T08:00:01.000+08:00| d0| 5| 3|
+-----------------------------+------+----+-----------+last_value
- 函数名:
last_value(value) [IGNORE NULLS] - 定义:返回 frame 的最后一个值,如果指定了 IGNORE NULLS 需要跳过后缀的 NULL;
- 示例:
IoTDB> SELECT *, last_value(flow) OVER w as last_value FROM device_flow WINDOW w AS (PARTITION BY device ORDER BY flow ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING);
+-----------------------------+------+----+----------+
| time|device|flow|last_value|
+-----------------------------+------+----+----------+
|1970-01-01T08:00:04.000+08:00| d1| 2| 4|
|1970-01-01T08:00:05.000+08:00| d1| 4| 4|
|1970-01-01T08:00:03.000+08:00| d0| 1| 3|
|1970-01-01T08:00:00.000+08:00| d0| 3| 3|
|1970-01-01T08:00:02.000+08:00| d0| 3| 5|
|1970-01-01T08:00:01.000+08:00| d0| 5| 5|
+-----------------------------+------+----+----------+nth_value
- 函数名:
nth_value(value, n) [IGNORE NULLS] - 定义:返回 frame 的第 n 个元素(注意 n 是从 1 开始),如果有 IGNORE NULLS 需要跳过 NULL;
- 示例:
IoTDB> SELECT *, nth_value(flow, 2) OVER w as nth_values FROM device_flow WINDOW w AS (PARTITION BY device ORDER BY flow ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING);
+-----------------------------+------+----+----------+
| time|device|flow|nth_values|
+-----------------------------+------+----+----------+
|1970-01-01T08:00:04.000+08:00| d1| 2| 4|
|1970-01-01T08:00:05.000+08:00| d1| 4| 4|
|1970-01-01T08:00:03.000+08:00| d0| 1| 3|
|1970-01-01T08:00:00.000+08:00| d0| 3| 3|
|1970-01-01T08:00:02.000+08:00| d0| 3| 3|
|1970-01-01T08:00:01.000+08:00| d0| 5| 5|
+-----------------------------+------+----+----------+- lead
- 函数名:
lead(value[, offset[, default]]) [IGNORE NULLS] - 定义:返回当前行的后 offset 个元素(如果有 IGNORE NULLS 则 NULL 不考虑在内),如果没有这样的元素(超过 partition 范围),则返回 default;offset 的默认值为 1,default 的默认值为 NULL。
- lead 函数需要需要一个 ORDER BY 窗口子句
- 示例:
IoTDB> SELECT *, lead(flow) OVER w as lead FROM device_flow WINDOW w AS(PARTITION BY device ORDER BY time);
+-----------------------------+------+----+----+
| time|device|flow|lead|
+-----------------------------+------+----+----+
|1970-01-01T08:00:04.000+08:00| d1| 2| 4|
|1970-01-01T08:00:05.000+08:00| d1| 4|null|
|1970-01-01T08:00:00.000+08:00| d0| 3| 5|
|1970-01-01T08:00:01.000+08:00| d0| 5| 3|
|1970-01-01T08:00:02.000+08:00| d0| 3| 1|
|1970-01-01T08:00:03.000+08:00| d0| 1|null|
+-----------------------------+------+----+----+- lag
- 函数名:
lag(value[, offset[, default]]) [IGNORE NULLS] - 定义:返回当前行的前 offset 个元素(如果有 IGNORE NULLS 则 NULL 不考虑在内),如果没有这样的元素(超过 partition 范围),则返回 default;offset 的默认值为 1,default 的默认值为 NULL。
- lag 函数需要需要一个 ORDER BY 窗口子句
- 示例:
IoTDB> SELECT *, lag(flow) OVER w as lag FROM device_flow WINDOW w AS(PARTITION BY device ORDER BY device);
+-----------------------------+------+----+----+
| time|device|flow| lag|
+-----------------------------+------+----+----+
|1970-01-01T08:00:04.000+08:00| d1| 2|null|
|1970-01-01T08:00:05.000+08:00| d1| 4| 2|
|1970-01-01T08:00:00.000+08:00| d0| 3|null|
|1970-01-01T08:00:01.000+08:00| d0| 5| 3|
|1970-01-01T08:00:02.000+08:00| d0| 3| 5|
|1970-01-01T08:00:03.000+08:00| d0| 1| 3|
+-----------------------------+------+----+----+2.3.3 Rank Function
- rank
- 函数名:
rank() - 定义:返回当前行在整个 partition 中的序号,值相同的行序号相同,序号之间可能有 gap;
- 示例:
IoTDB> SELECT *, rank() OVER w as rank FROM device_flow WINDOW w AS (PARTITION BY device ORDER BY flow);
+-----------------------------+------+----+----+
| time|device|flow|rank|
+-----------------------------+------+----+----+
|1970-01-01T08:00:04.000+08:00| d1| 2| 1|
|1970-01-01T08:00:05.000+08:00| d1| 4| 2|
|1970-01-01T08:00:03.000+08:00| d0| 1| 1|
|1970-01-01T08:00:00.000+08:00| d0| 3| 2|
|1970-01-01T08:00:02.000+08:00| d0| 3| 2|
|1970-01-01T08:00:01.000+08:00| d0| 5| 4|
+-----------------------------+------+----+----+- dense_rank
- 函数名:
dense_rank() - 定义:返回当前行在整个 partition 中的序号,值相同的行序号相同,序号之间没有 gap。
- 示例:
IoTDB> SELECT *, dense_rank() OVER w as dense_rank FROM device_flow WINDOW w AS (PARTITION BY device ORDER BY flow);
+-----------------------------+------+----+----------+
| time|device|flow|dense_rank|
+-----------------------------+------+----+----------+
|1970-01-01T08:00:04.000+08:00| d1| 2| 1|
|1970-01-01T08:00:05.000+08:00| d1| 4| 2|
|1970-01-01T08:00:03.000+08:00| d0| 1| 1|
|1970-01-01T08:00:00.000+08:00| d0| 3| 2|
|1970-01-01T08:00:02.000+08:00| d0| 3| 2|
|1970-01-01T08:00:01.000+08:00| d0| 5| 3|
+-----------------------------+------+----+----------+- row_number
- 函数名:
row_number() - 定义:返回当前行在整个 partition 中的行号,注意行号从 1 开始;
- 示例:
IoTDB> SELECT *, row_number() OVER w as row_number FROM device_flow WINDOW w AS (PARTITION BY device ORDER BY flow);
+-----------------------------+------+----+----------+
| time|device|flow|row_number|
+-----------------------------+------+----+----------+
|1970-01-01T08:00:04.000+08:00| d1| 2| 1|
|1970-01-01T08:00:05.000+08:00| d1| 4| 2|
|1970-01-01T08:00:03.000+08:00| d0| 1| 1|
|1970-01-01T08:00:00.000+08:00| d0| 3| 2|
|1970-01-01T08:00:02.000+08:00| d0| 3| 3|
|1970-01-01T08:00:01.000+08:00| d0| 5| 4|
+-----------------------------+------+----+----------+- percent_rank
- 函数名:
percent_rank() - 定义:以百分比的形式,返回当前行的值在整个 partition 中的序号;即 (rank() - 1) / (n - 1),其中 n 是整个 partition 的行数;
- 示例:
IoTDB> SELECT *, percent_rank() OVER w as percent_rank FROM device_flow WINDOW w AS (PARTITION BY device ORDER BY flow);
+-----------------------------+------+----+------------------+
| time|device|flow| percent_rank|
+-----------------------------+------+----+------------------+
|1970-01-01T08:00:04.000+08:00| d1| 2| 0.0|
|1970-01-01T08:00:05.000+08:00| d1| 4| 1.0|
|1970-01-01T08:00:03.000+08:00| d0| 1| 0.0|
|1970-01-01T08:00:00.000+08:00| d0| 3|0.3333333333333333|
|1970-01-01T08:00:02.000+08:00| d0| 3|0.3333333333333333|
|1970-01-01T08:00:01.000+08:00| d0| 5| 1.0|
+-----------------------------+------+----+------------------+- cume_dist
- 函数名:cume_dist
- 定义:以百分比的形式,返回当前行的值在整个 partition 中的序号;即 (小于等于它的行数) / n。
- 示例:
IoTDB> SELECT *, cume_dist() OVER w as cume_dist FROM device_flow WINDOW w AS (PARTITION BY device ORDER BY flow);
+-----------------------------+------+----+---------+
| time|device|flow|cume_dist|
+-----------------------------+------+----+---------+
|1970-01-01T08:00:04.000+08:00| d1| 2| 0.5|
|1970-01-01T08:00:05.000+08:00| d1| 4| 1.0|
|1970-01-01T08:00:03.000+08:00| d0| 1| 0.25|
|1970-01-01T08:00:00.000+08:00| d0| 3| 0.75|
|1970-01-01T08:00:02.000+08:00| d0| 3| 0.75|
|1970-01-01T08:00:01.000+08:00| d0| 5| 1.0|
+-----------------------------+------+----+---------+- ntile
- 函数名:ntile
- 定义:指定 n,给每一行进行 1~n 的编号。
- 整个 partition 行数比 n 小,那么编号就是行号 index;
- 整个 partition 行数比 n 大:
- 如果行数能除尽 n,那么比较完美,比如行数为 4,n 为 2,那么编号为 1、1、2、2、;
- 如果行数不能除尽 n,那么就分给开头几组,比如行数为 5,n 为 3,那么编号为 1、1、2、2、3;
- 示例:
IoTDB> SELECT *, ntile(2) OVER w as ntile FROM device_flow WINDOW w AS (PARTITION BY device ORDER BY flow);
+-----------------------------+------+----+-----+
| time|device|flow|ntile|
+-----------------------------+------+----+-----+
|1970-01-01T08:00:04.000+08:00| d1| 2| 1|
|1970-01-01T08:00:05.000+08:00| d1| 4| 2|
|1970-01-01T08:00:03.000+08:00| d0| 1| 1|
|1970-01-01T08:00:00.000+08:00| d0| 3| 1|
|1970-01-01T08:00:02.000+08:00| d0| 3| 2|
|1970-01-01T08:00:01.000+08:00| d0| 5| 2|
+-----------------------------+------+----+-----+2.4 场景示例
- 多设备 diff 函数
对于每个设备的每一行,与前一行求差值:
SELECT
*,
measurement - lag(measurement) OVER (PARTITION BY device ORDER BY time)
FROM data
WHERE timeCondition;对于每个设备的每一行,与后一行求差值:
SELECT
*,
measurement - lead(measurement) OVER (PARTITION BY device ORDER BY time)
FROM data
WHERE timeCondition;对于单个设备的每一行,与前一行求差值(后一行同理):
SELECT
*,
measurement - lag(measurement) OVER (ORDER BY time)
FROM data
where device='d1'
WHERE timeCondition;- 多设备 TOP_K/BOTTOM_K
利用 rank 获取序号,然后在外部的查询中保留想要的顺序。
(注意, window function 的执行顺序在 HAVING 子句之后,所以这里需要子查询)
SELECT *
FROM(
SELECT
*,
rank() OVER (PARTITION BY device ORDER BY time DESC)
FROM data
WHERE timeCondition
)
WHERE rank <= 3;除了按照时间排序之外,还可以按照测点的值进行排序:
SELECT *
FROM(
SELECT
*,
rank() OVER (PARTITION BY device ORDER BY measurement DESC)
FROM data
WHERE timeCondition
)
WHERE rank <= 3;- 多设备 CHANGE_POINTS
这个 sql 用来去除输入序列中连续相同值,可以用 lead + 子查询实现:
SELECT
time,
device,
measurement
FROM(
SELECT
time,
device,
measurement,
LEAD(measurement) OVER (PARTITION BY device ORDER BY time) AS next
FROM data
WHERE timeCondition
)
WHERE measurement != next OR next IS NULL;